从三大顶会论文看百变Self-Attention

作者丨刘朋伯
学校丨哈尔滨工业大学硕士生
研究方向丨自然语言处理
研究背景
本人维护了一个 NLP 论文集仓库:
https://github.com/PengboLiu/NLP-Papers
首先简单讲一下 Self Attention。
Self Attention 原本是 Transformer 中的一个结构,现在很多时候也被单独拿出来作为一个特征抽取器。输入是一个 Query 向量,一个 Key 向量和一个 Value 向量。在 Self Attention 中,三者相同。是模型维度。
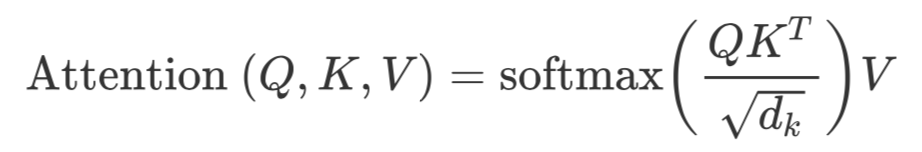
如果是 Multi-Head Attention,那就把多个 Attention 拼在一起。

简单粗暴又有效,那么能不能对这种结构进行一些改进呢?
首先是 EMNLP 2019 中,腾讯 AI Lab 的三篇关于改进 SANs 的论文(本文中,Self Attention Networks 简记为 SANs)。


在 Transformer 中,SANs 本身不能表示句子结构的,句子的序列信息是靠 “position encoding” 得到的。
本文对此进行改进,在 SANs 中融合了结构性的位置表示信息,以此增强 SANs 对句子潜在结构的建模能力。当然并没有舍弃原有的 position encoding,本文是把序列信息和结构信息一并使用。
结构化位置表示:position encoding 是根据句子中单词的实际位置建模,而本文引入了依存句法树表示单词之间的关系。直觉上来说,这种方法能挖掘出更多关于句子中各个词语之间的依存信息。
本文介绍了两种位置:绝对结构位置和相对结构位置(使用 Stanford Parser):
1. 绝对结构位置:把主要动词作为原点,然后计算依存树上每个单词到原点的距离;
2. 相对结构位置:根据以下规则计算每两个单词之间的距离:
在依存树的一条边上,两个单词的绝对结构位置之差就是相对结构位置;
如果不在同一条边,两个单词的绝对结构位置之和乘 1(两个单词在句子中正序)或 -1(两个单词在句子中正序逆序)或 0 (同一个单词)
最后,序列绝对位置和结构绝对位置通过非线性函数结合在一起得到绝对位置的表示。至于相对位置,因为每个时间步的单词都不同,方法和绝对位置表示也不一样。这里,作者参考了 Self-Attention with Relative Position Representations [1] 中的方法。
作者在 NMT 和 Linguistic Probing Evaluation 两个任务上进行试验,结果表明无论是相对结构位置还是绝对结构位置都能更好地在句法和语义层面上建模,从而达到更好的效果。


上一篇论文是利用 Parser 生成依存句法树进而改变 SANs 的输出,这篇论文则在 SANs 的结构做了一些改动,目的类似,也是为了增加句子的句法结构信息。
多粒度的 Self Attention 简称为 MG-SA,结合多头注意力和短语建模。一方面,在多头注意力中拿出几个“头”在 N 元语法和句法维度对短语建模;然后,利用短语之间的相互作用增强 SANs 对句子结构建模的能力(还是 structure modeling)。
本文的 motivation 有两方面:
1. 和上一篇论文类似,考虑短语模式学习句子的潜在结构;
2. 最近很多论文表明,SANs 中很多“head” 并没有被充分利用,这样何不试试把一些“head” 做别的事情从而改善 SANs 的性能。
改进后的 MG-SA 如下:
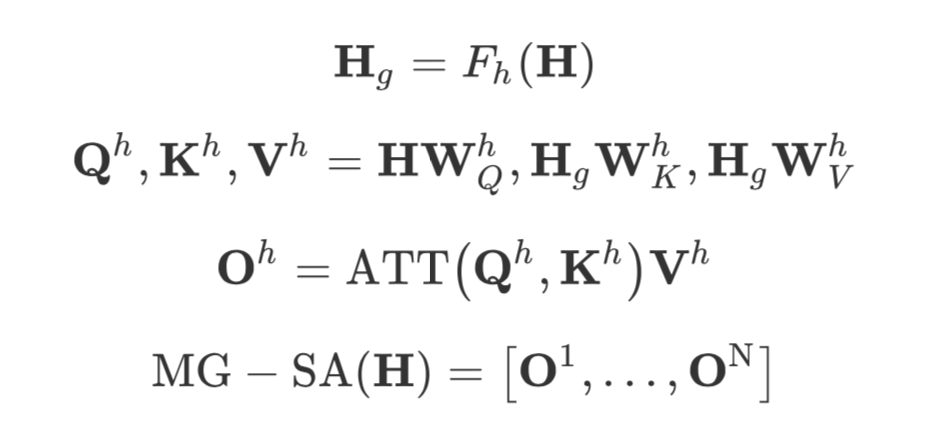
ATT 就是经典的 Self Attention,无需多言。可以看出,主要的改动在于 H9(文章称之为生成的短语级记忆)。计算方法也就是文章提到的 “Multi-Granularity” 表示:
多粒度表示
首先是得到短语划分并对其合成,如图(a),然后短语标签监督和短语交互可以进一步增强短语表示在结构上的建模能力。最终得到的 MG-SA 如图(b)。
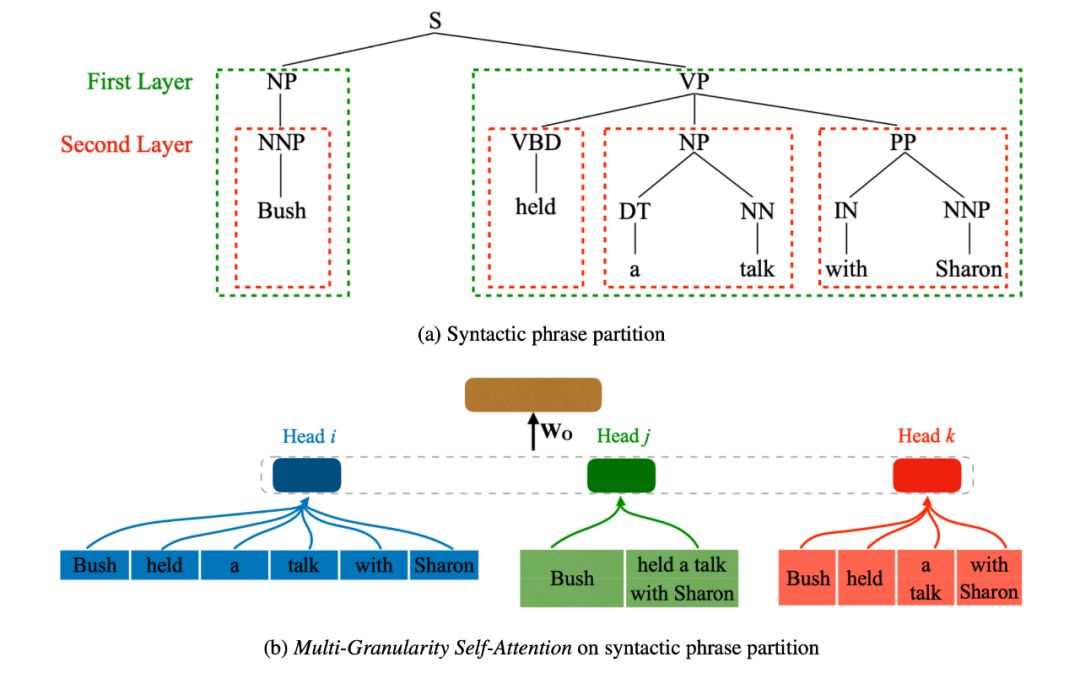
短语划分(Phrase Partition):句子划分成若干个不重叠的长度为 n 个单词的短语。此外,又提出了句法级的短语划分(当然也要靠句法树),得到的短语输入为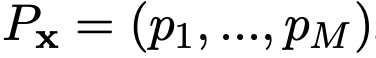
合成策略(Composition Strategies):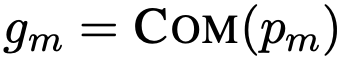
短语标签监督(Phrase Tag Supervision):得到的,我们再使用它预测短语的标签(就是 NP、VP、PP 这些)。预测方法(softmax)和损失函数(负对数似然)如下:
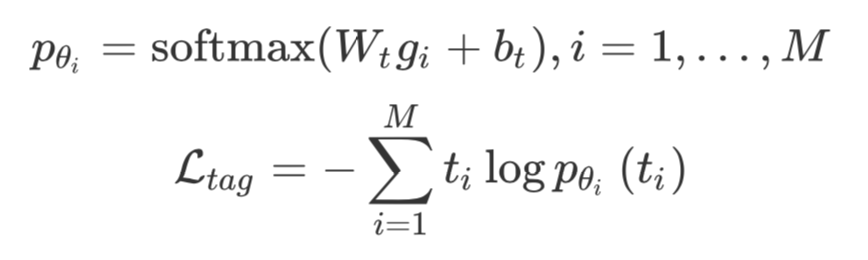
短语间的交互(Phrase Interaction ):想让句子的短语得到交互,直觉肯定是要引入循环式的结构(REC),那 LSTM 当之无愧了。本文采用了 ICLR2019 提出的 Ordered Neurons LSTM (ON-LSTM,关于 ON-LSTM 的介绍,可以参考ON-LSTM:用有序神经元表达层次结构)。到此为止,我们终于得到了。
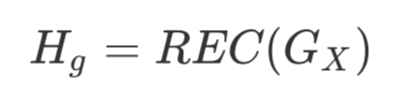
训练和实验
训练时的损失函数需要把刚才定义的短语标签预测损失加起来;
在机器翻译任务上做了若干组实验,并进行了可视化分析;
完成了 Does string-based neural mt learn source syntax [2] 中的任务来评估 MG-SA 多粒度短语建模的能力。


看论文标题就知道,又是一篇对 SANs 结构改进的文章,而且也使用了刚才提到的 ON-LSTM。本文的贡献有二:
1. 层次结构(要区别与上文的句法结构)可以更好地对 SANs 建模;
2. 证明了 ON-LSTM 对有助于 NMT 任务;
这里,我们主要看看对 SANs 的改进。
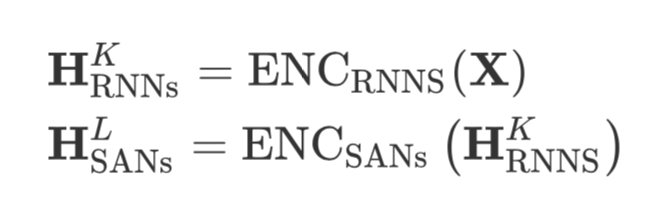
其实就是输入先使用 RNNs 编码,然后得到的输出再用 SANs 编码。这里的 RNN 就是 ON-LSTM,具体细节还是看苏神的文章就好。
最后,也没有直接去利用得到的 SANs 的输出,而是使用 Short-Cut Connection (就是类似 Transformer 中 residual connection 的结构)。也算是取之 Transformer,用之 Transformer。
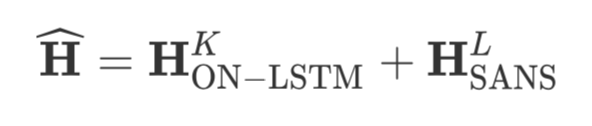


同样是来自 EMNLP 2019 的 paper,这篇 paper 对 SANs 的改进主要是在两个相邻单词之间增加了一个“Constituent Attention”模块,从而达到树结构的效果(也就是 Tree Transformer)。
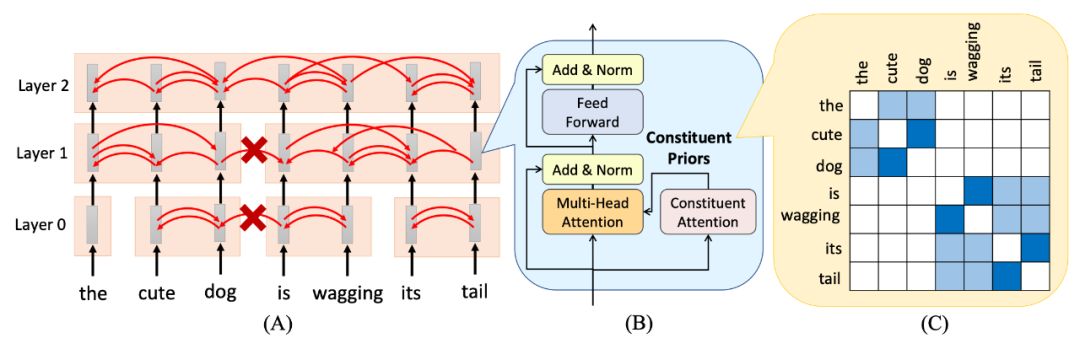
图(A)是 Tree Transformer 的结构。以图为例,输入“the cute dog is wagging its tail”。在 layer0,cute 和 dog 组成一个“Constituent”,its 和 tail 组成一个“Constituent”。在 layer1,两个相邻的“Constituent” 可能融合在一起,所以“Constituent” 的尺寸是越来越大的,到最顶层就只有一个“Constituent” 了。那么怎么划分一个“Constituent”呢?
文章引入了“Constituent Attention”、“ Neighboring Attention” 和“Hierarchical Constraint” 的概念。
首先是 Neighboring Attention,q 和 k 和经典的 transformer 结构中的意义相同。
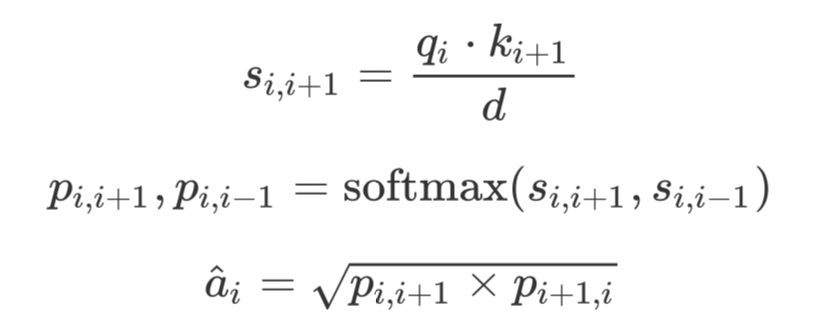
得到的还需“Hierarchical Constraint”的处理,至于为什么后面会说。
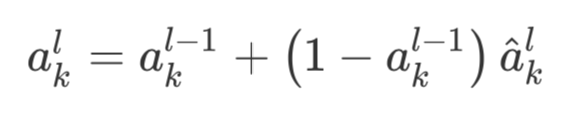
最后一步,终于要计算“Constituent Attention”了!
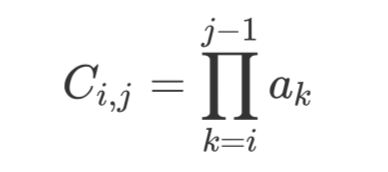
由 i,j 之间的
连乘得到。不过这么做有个问题就是某个
特别小的话,连乘起来的结果会趋近于 0,所以我们用对数和的形式代替它:
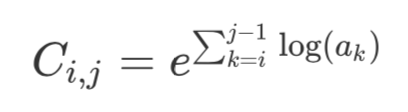
“Constituent Attention” 要怎么去用呢?并不是单独作为一个结构,而是在原有的 attention 概率分布前乘上这个“Constituent Attention” 就好了。
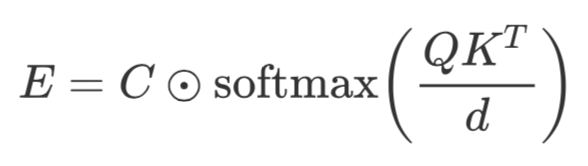
在这,解释一下“Hierarchical Constraint”:因为 attention 的每一个 layer,都不小于前一个 layer,为了保证这种层次性,我们需要添加这样一种限制,使得每一层的“Constituent Attention” 都要大于上一层的。
图(B)是整个 Tree Transformer 的结构,图(C)是 Constituent Attention 的热力图,可以看到,确实有了分块的效果。
值得一提的是,文章还单独一节介绍了 Tree Transformer 中的Neighboring Attention,可以看做一种无监督的 parsing,也算是意料中的收获吧。


NeurIPS 2019 的文章,来自 CMU Neubig 团队,一篇偏重解释性的文章。
文章讨论的是 SANs 是不是真的需要那么多 heads。讨论这件事,就需要删除掉一些 heads 做对比实验。Head 具体怎么删除呢?文章中的做法是将一些 head 参数矩阵置 0 进行 mask。
去掉一个head的影响
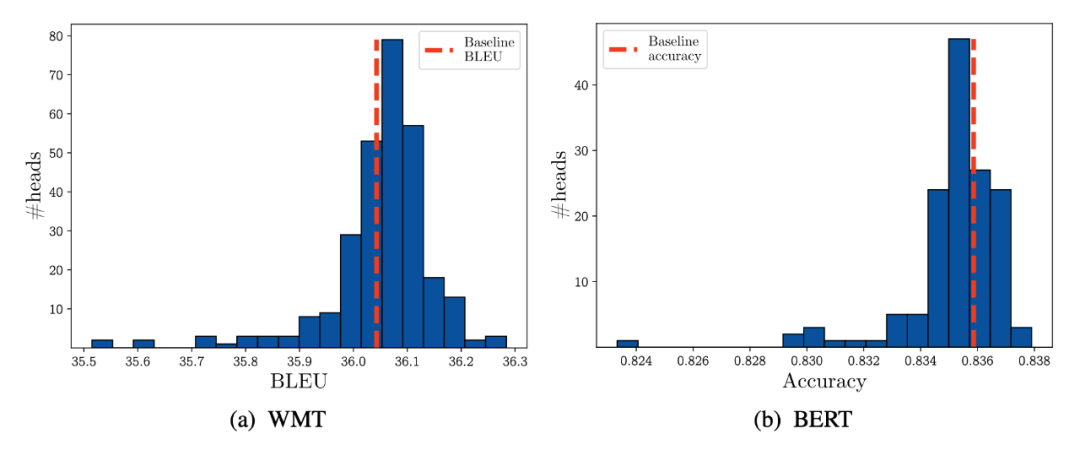
在 WMT 模型中的 encoder 部分,分别将其中96(16heads*6 层)个单独去掉。绝大部分的 head 被单独去掉BLEU 反而有所提升,极少数的几个(4 个)去掉之后效果会稍差。论文还做了一组实验,证明了:在 inference 阶段,绝大部分的head 被单独去掉不会对效果有什么太大影响;BERT 中,同样单独去掉 head,大概有 50 个 head,在去掉其中一个的时候效果反而要好于原始 bert 模型。
大部分的 head 在被单独的去掉的时候,效果不会损失太多。
只留下一个 head
96 个 head 去掉一个直观上一想确实不会有太大影响。作者又进一步删除掉更多的 heads:在某个 layer 内只保留一个 head。结果,无论是 BERT 还是 NMT,对实验效果都没什么太大的影响。
需要注意的是,机器翻译中,self attention 保留一个 head 影响不大,但是 Encoder-Decoder 的 attention 则需要更多的 head。
不同的数据集,head 的重要程度相同吗?
论文给出的答案是基本呈正相关的。这里的是去掉某个 head,然后分别在两个不同的数据集(MNLI-matched 和 MNLI-mismatche)中进行测试,观察这个 head 对效果的影响是否在两个数据集的表现一致。当然,这里的实验做的可能做的不够充分。
启发式迭代剪枝 head
那么如果想在不同层之间同时去掉一些 head 呢?作者给出了一种启发式的策略。
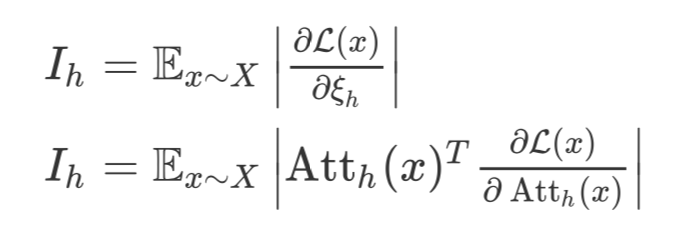
根据求导得到的,每次去掉 10% 的 head。
之前知乎上有个问题:为什么 Transformer 需要进行 Multi-head Attention? [3] 相信这篇文章可以某种程度上回答一下此问题。当然,对 head 数量的探索,肯定不止于此。


对 head 数量剪枝的还有 ACL 2019 的这一篇。作者十分良心,写了篇博客 [4] 解释自己的论文。本文的实验非常非常详尽,如果看了上一篇文章还对 head 剪枝感兴趣不妨先看看这篇文章对应的博客。
文章的结论大概如下:
只有一小部分头对于翻译任务似乎很重要(上一篇文章也得到了类似的结论);
重要的头有一到多个功能:位置、句法、低频词等;
Encoder 端的 head 很多都可以被减掉(是不是又似曾相识);
总结与思考
-
目前的 Transformer 结构,encoder 端的 head 是存在冗余的,Multi-Head 其实不是必须的; -
丢掉一些 head 反而能提升性能,大概有点像 dropout? -
不同的 head 似乎有不同的分工; -
结构信息对文本建模很重要,无论是什么方法即使是 Transformer; -
目前对 SANs 的改造还比较浅层,不够大刀阔斧。
相关链接

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐




