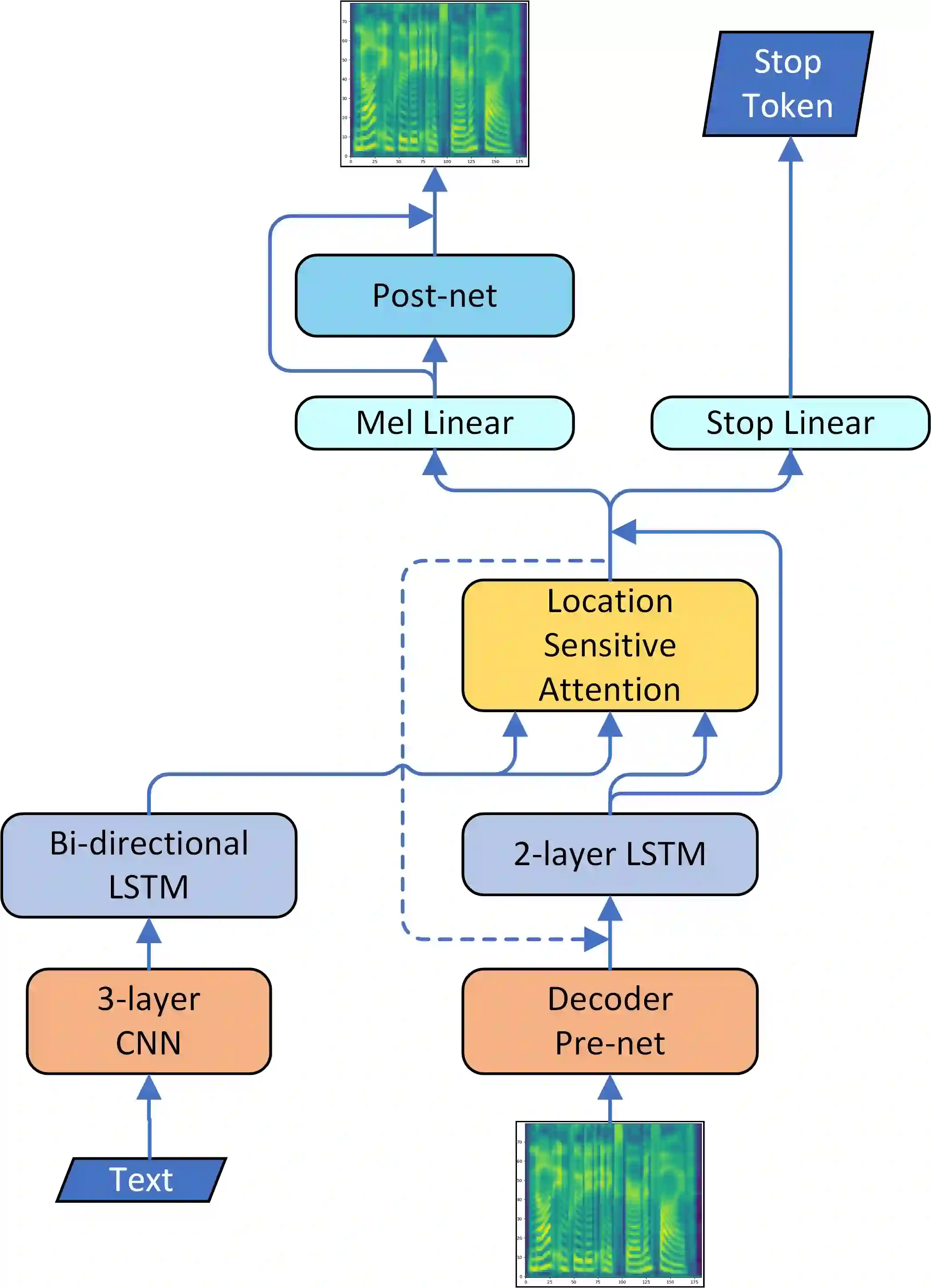
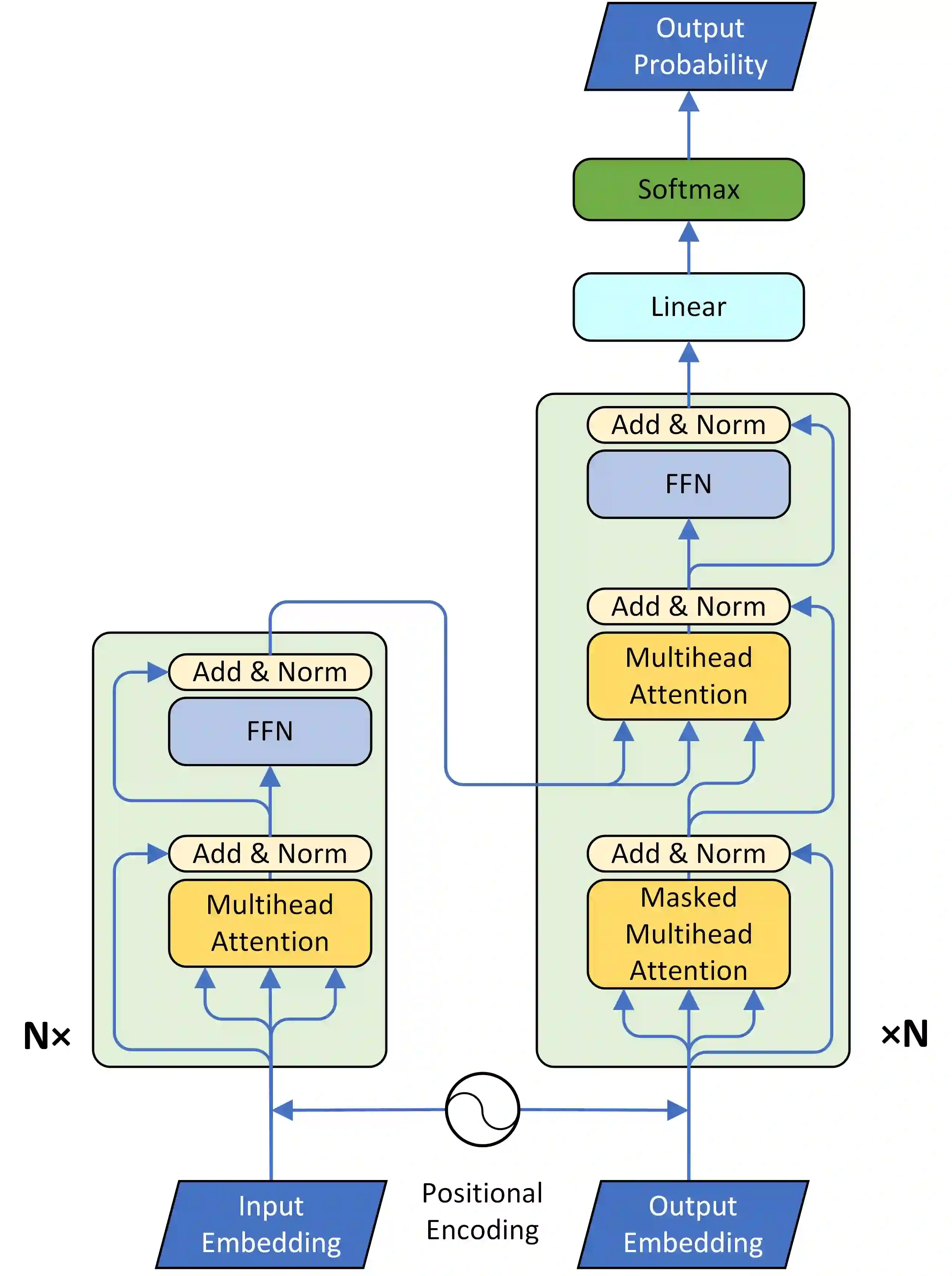
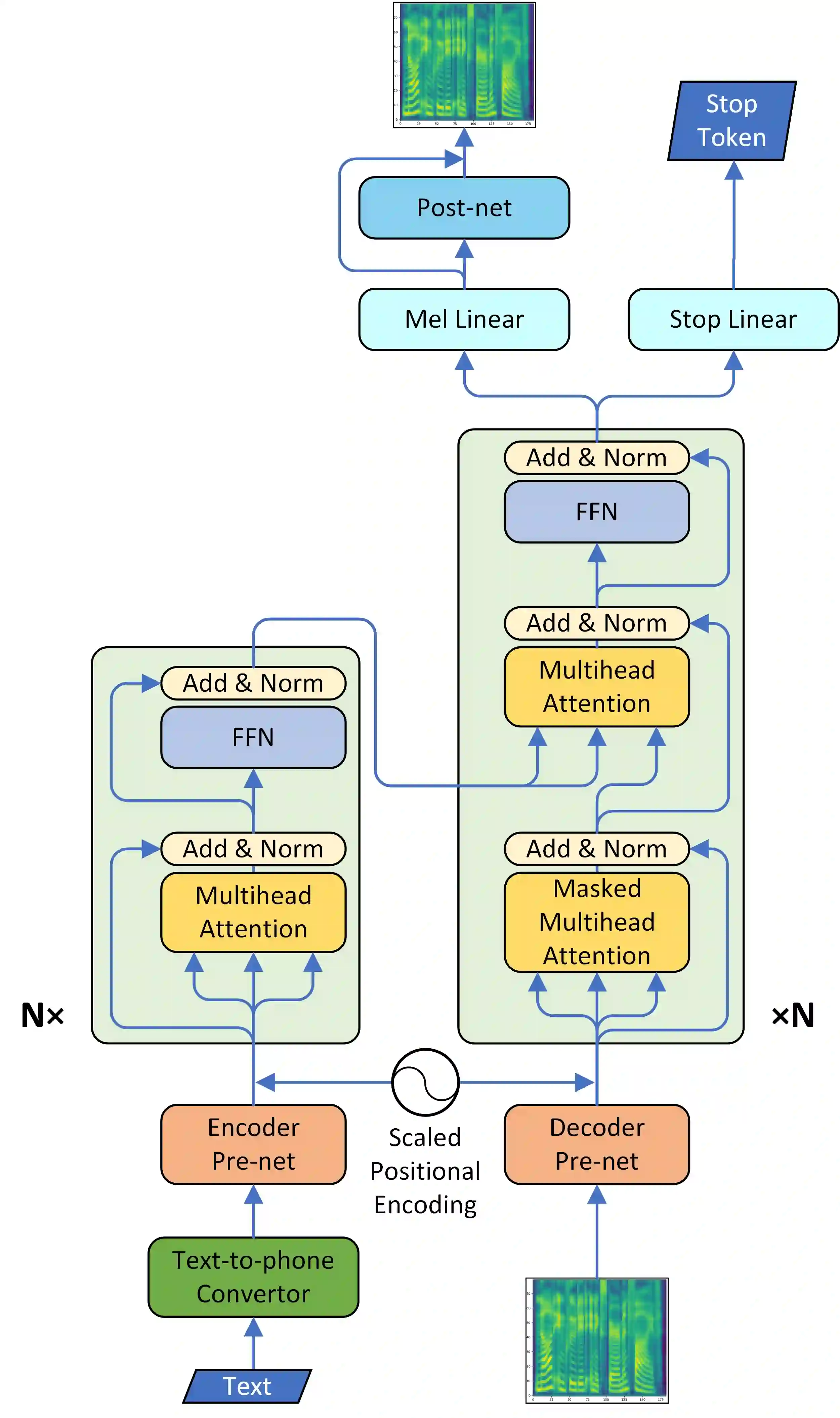
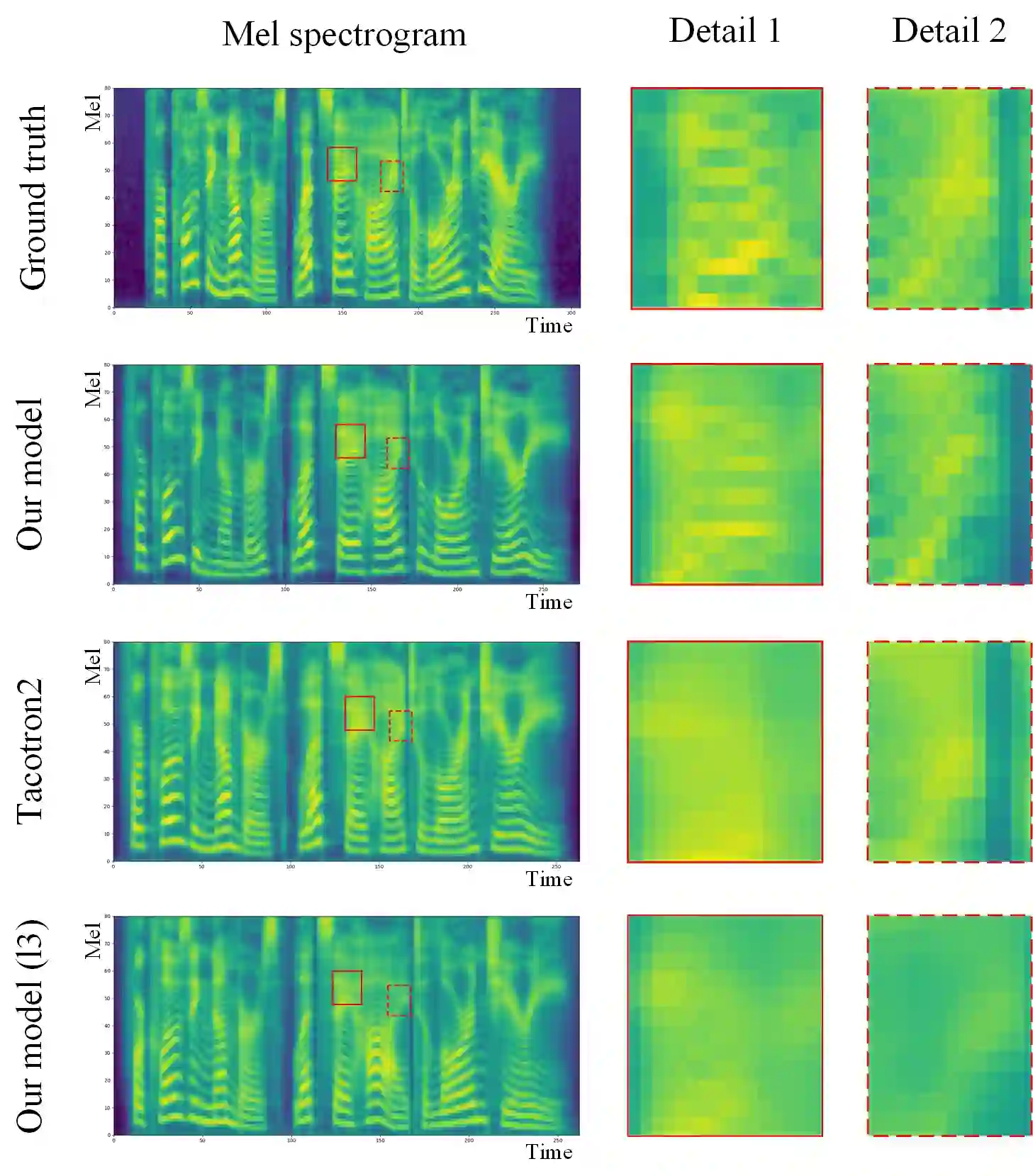
Although end-to-end neural text-to-speech (TTS) methods (such as Tacotron2) are proposed and achieve state-of-the-art performance, they still suffer from two problems: 1) low efficiency during training and inference; 2) hard to model long dependency using current recurrent neural networks (RNNs). Inspired by the success of Transformer network in neural machine translation (NMT), in this paper, we introduce and adapt the multi-head attention mechanism to replace the RNN structures and also the original attention mechanism in Tacotron2. With the help of multi-head self-attention, the hidden states in the encoder and decoder are constructed in parallel, which improves the training efficiency. Meanwhile, any two inputs at different times are connected directly by self-attention mechanism, which solves the long range dependency problem effectively. Using phoneme sequences as input, our Transformer TTS network generates mel spectrograms, followed by a WaveNet vocoder to output the final audio results. Experiments are conducted to test the efficiency and performance of our new network. For the efficiency, our Transformer TTS network can speed up the training about 4.25 times faster compared with Tacotron2. For the performance, rigorous human tests show that our proposed model achieves state-of-the-art performance (outperforms Tacotron2 with a gap of 0.048) and is very close to human quality (4.39 vs 4.44 in MOS).
翻译:虽然提出了端到端神经文本到语音(TTS)方法(如Tacotron2),并实现了最新性能,但它们仍面临两个问题:(1) 培训和推断过程中效率低;(2) 很难用当前经常性神经网络(RNNS)模拟长期依赖性能。受神经机器翻译(NMT)中变压器网络的成功启发,我们在本文件中引入并调整多头关注机制,以取代RNN结构以及Tacotron的原始关注机制。2. 在多头自知的帮助下,在塔克坦和解码器中隐藏的状态是平行建造的,提高了培训效率。同时,在不同时间的任何两种投入都直接由自控机制连接,这可以有效解决远程依赖性问题。使用电话序列,我们的TTTS网络生成中线谱谱图,然后用波网电码输出最后音频结果。在多头盘中进行实验以测试我们新的网络的效率和性能。4.39 质量和解码的隐藏状态将测试我们新的网络的速率和性能测试。