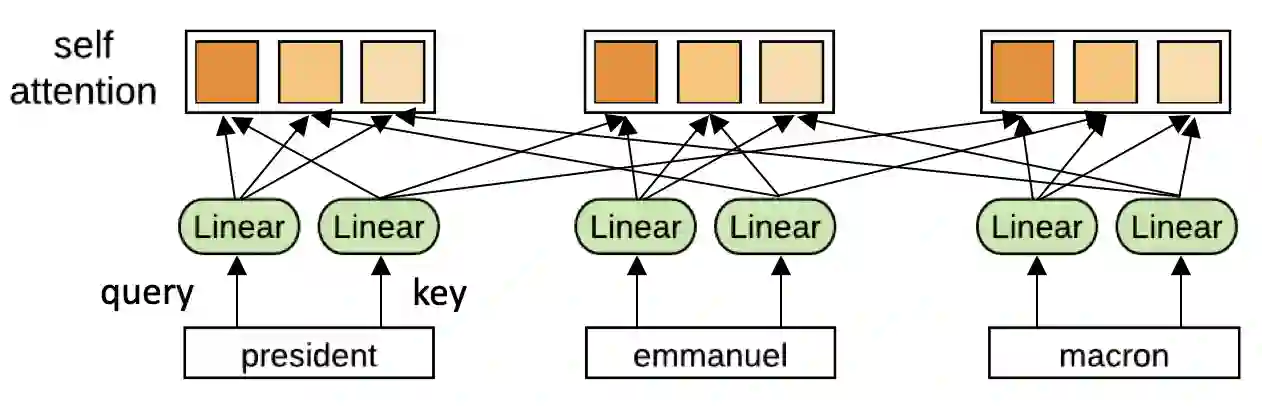
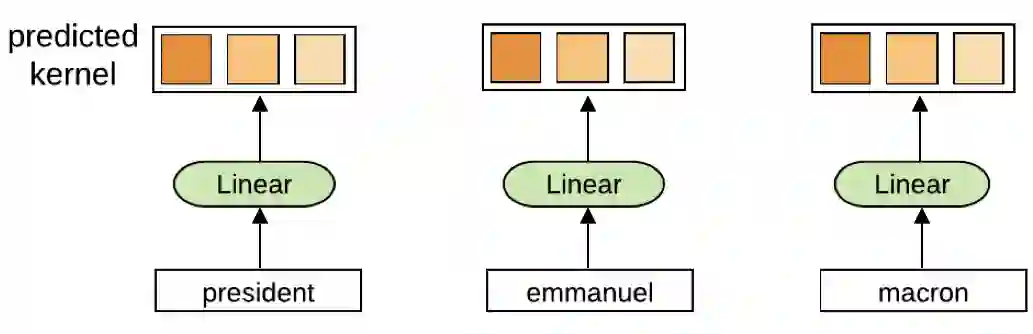
Self-attention is a useful mechanism to build generative models for language and images. It determines the importance of context elements by comparing each element to the current time step. In this paper, we show that a very lightweight convolution can perform competitively to the best reported self-attention results. Next, we introduce dynamic convolutions which are simpler and more efficient than self-attention. We predict separate convolution kernels based solely on the current time-step in order to determine the importance of context elements. The number of operations required by this approach scales linearly in the input length, whereas self-attention is quadratic. Experiments on large-scale machine translation, language modeling and abstractive summarization show that dynamic convolutions improve over strong self-attention models. On the WMT'14 English-German test set dynamic convolutions achieve a new state of the art of 29.7 BLEU.
翻译:自我注意是建立语言和图像基因模型的有用机制。 它通过比较每个元素与当前时间步骤来决定上下文要素的重要性。 在本文中, 我们显示, 极轻量级的演化可以与最佳报告自我注意结果相竞争。 接下来, 我们引入比自我注意更简单、更有效率的动态演化。 我们预测, 仅仅根据当前时间步骤来决定上下文要素的重要性 。 这个方法所需的演动内核分化数量在输入长度上线度的操作数量, 而自我注意是四面形的。 大规模机器翻译、 语言建模和抽象加和实验显示, 动态演动会比强的自我注意模型有所改进。 WMT' 14 英国- 德国测试设置了动态演进, 实现了29.7 BLEU 艺术的新状态 。