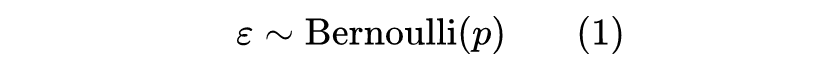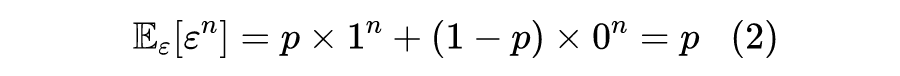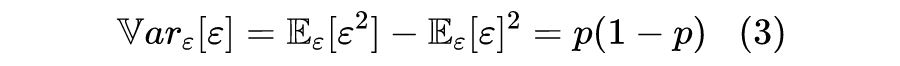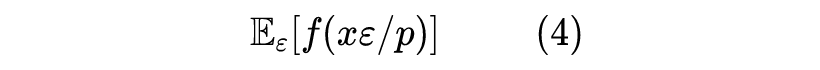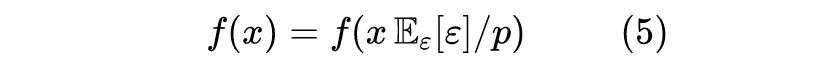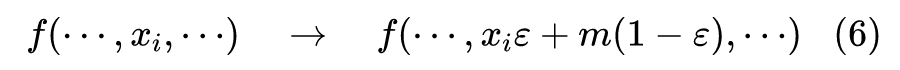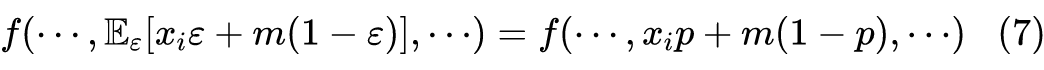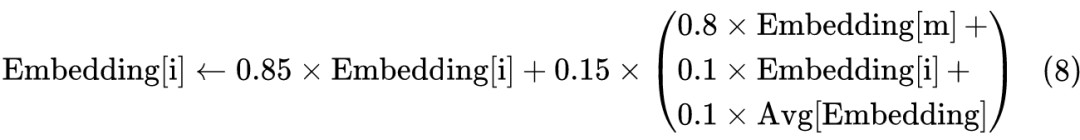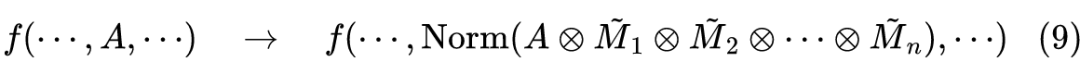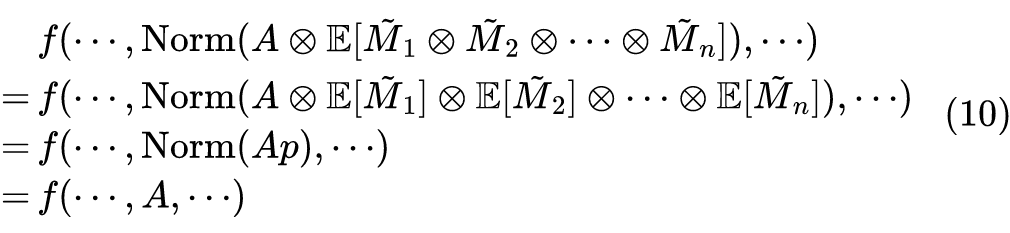![]()
©PaperWeekly 原创 · 作者 |苏剑林
单位 |追一科技
研究方向 |NLP、神经网络
大家都知道,BERT 的 MLM(Masked Language Model)任务在预训练和微调时的不一致,也就是预训练出现了 [MASK] 而下游任务微调时没有 [MASK],是经常被吐槽的问题,很多工作都认为这是影响 BERT 微调性能的重要原因,并针对性地提出了很多改进,如 XL-NET [1]、ELECTRA [2]、MacBERT [3] 等。
本文我们将从 Dropout 的角度来分析 MLM 的这种不一致性,并且提出一种简单的操作来修正这种不一致性。
同样的分析还可以用于何凯明最近提出的比较热门的 MAE(Masked Autoencoder)模型,结果是 MAE 相比 MLM 确实具有更好的一致性,由此我们可以引出一种可以能加快训练速度的正则化手段。
Dropout
首先,我们重温一下 Dropout。从数学上来看,Dropout 是通过伯努利分布来为模型引入随机噪声的操作,所以我们也简单复习一下伯努利分布。
![]()
伯努利分布(Bernoulli Distribution)算得上是最简单的概率分布了,它是一个二元分布,取值空间是
,其中
取 1 的概率为
,取 0 的概率为
,记为
![]()
伯努利分布的一个有趣的性质是它的任意阶矩都为
,即
![]()
![]()
Dropout 在训练阶段,将会以
将某些值置零,而其余值则除以
,所以 Dropout 事实上是引入了随机变量
,使得模型从
变成
。其中
可以有多个分量,对应多个独立的伯努利分布,但大多数情况下其结果跟
是标量是没有本质区别,所以我们只需要针对
是标量时进行推导。
![]()
这意味着我们应该要不关闭 Dropout 地预测多次,然后将预测结果进行平均来作为最终的预测结果,即进行“模型平均”。但很显然这样做计算量很大,所以实际中我们很少会用这种做法,更多的是直接关闭 Dropout,即将
改为 1。而我们知道
![]()
所以关闭 Dropout 事实上是一种“权重平均”(将
视为模型的随机权重)。也就是说,理论的最优解是“模型平均”,但由于计算量的原因,我们通常用“权重平均”来近似,它可以视为“模型平均”的一阶近似。
![]()
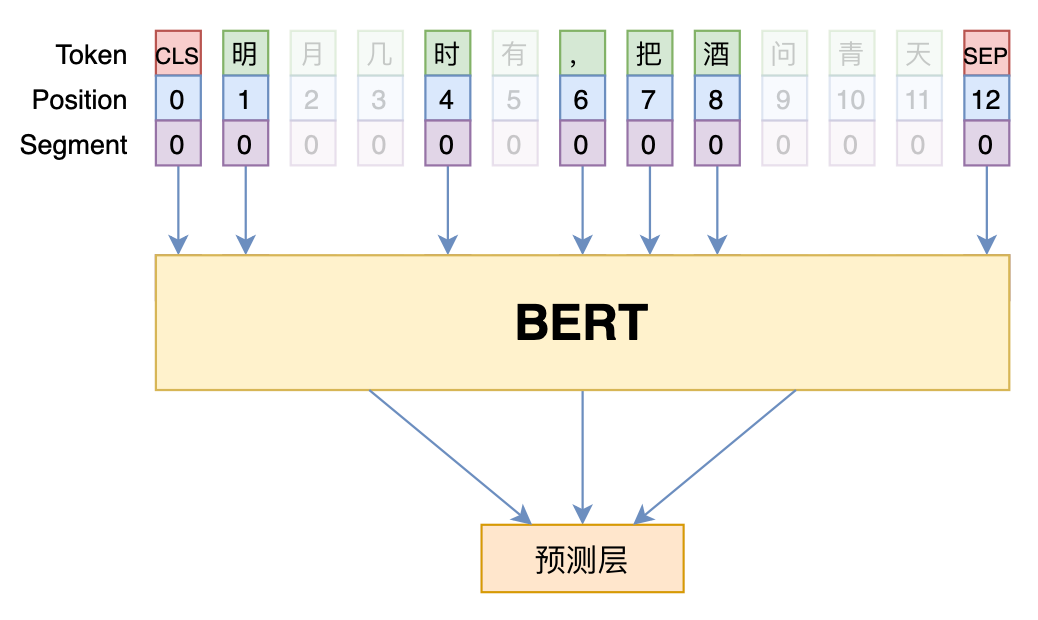
在这一节中,我们将 MLM 模型视为一种特殊的 Dropout,由此可以清楚描述地预训练和微调的不一致之处,并且可以导出一个简单的修正策略,可以更好地缓解这种不一致性。
![]()
简单起见,我们先来分析一个简化版本的 MLM:假设在预训练阶段,每个 token 以
的概率保持不变,以
的概率被替换为 [MASK],并且第
个 token 的 Embedding 记为
,[MASK] 的 Embedding 记为
,那么我们可以同样引入随机变量
,将 MLM 的模型记为
![]()
这样,MLM 跟 Dropout 本质是相同的,它们都是通过伯努利分布给模型引入了随机扰动。现在,按照 Dropout 的常规用法,它的预测模型应该是“权重平均”,即
![]()
此时,MLM 在微调阶段的不一致性就体现出来了:我们将预训练的 MLM 视为一种特殊的 Dropout,那么微调阶段对应的是“取消 Dropout”,按照常规做法,此时我们应该将每个 token 的 Embedding 改为
,但事实上我们没有,而是保留了原始的
。
![]()
按照 BERT 的默认设置,在训练 MLM 的时候,会有 15% 的 token 被选中来做 MLM 预测,而在这 15% 的 token 中,有 80% 的概率被替换为[MASK],有 10% 的概率保持不变,剩下10%的概率则随机替换为一个随机 token,这样根据上述分析,我们在 MLM 预训练完成之后,应该对 Embedding 进行如下调整:
![]()
其中
是 [MASK] 的 Embedding,而
的全体 token 的平均 Embedding。在 bert4keras 中,参考代码如下:
embeddings = model.get_weights()[0] # 一般第一个权重就是Token Embedding
v1 = embeddings[tokenizer._token_mask_id][None] # [MASK]的Embedding
v2 = embeddings.mean(0)[None] # 平均Embedding
embeddings = 0.85 * embeddings + 0.15 * (0.8 * v1 + 0.1 * embeddings + 0.1 * v2) # 加权平均
K.set_value(model.weights[0], embeddings) # 重新赋值
那么,该修改是否跟我们期望的那样有所提升呢?笔者在 CLUE 上对比了 BERT 和 RoBERTa 修改前后的实验结果(baseline代码参考《bert4keras在手,baseline我有:CLUE基准代码》
[4]
),结论是“没有显著变化”。
看到这里,读者也许会感到失望:敢情你前面说那么多都是白说了?笔者认为,上述操作确实是可以缓解预训练和微调的不一致性的(否则我们不是否定了Dropout?);至于修改后的效果没有提升,意味着这种不一致性的问题并没有我们想象中那么严重,至少在 CLUE 的任务上是这样。
一个类似的结果出现的 MacBERT 中,它在预训练阶段用近义词来代替 [MASK] 来修正这种不一致性,但笔者也在用同样的 baseline 代码测试过 MacBERT,结果显示它跟 RoBERTa 也没显著差别。因此,也许只有在特定的任务或者更大的 mask 比例下,才能显示出修正这种不一致性的必要性。
![]()
不少读者可能已经听说过何凯明最近提出的 MAE(Masked Autoencoder)
[5]
模型,它以一种简单高效的方式将 MLM 任务引入到图像的预训练之中,并获得了有效的提升。在这一节中,我们将会看到,MAE 同样可以作为一种特殊的 Dropout 来理解,从中我们可以得到一种防止过拟合的新方法。
![]()
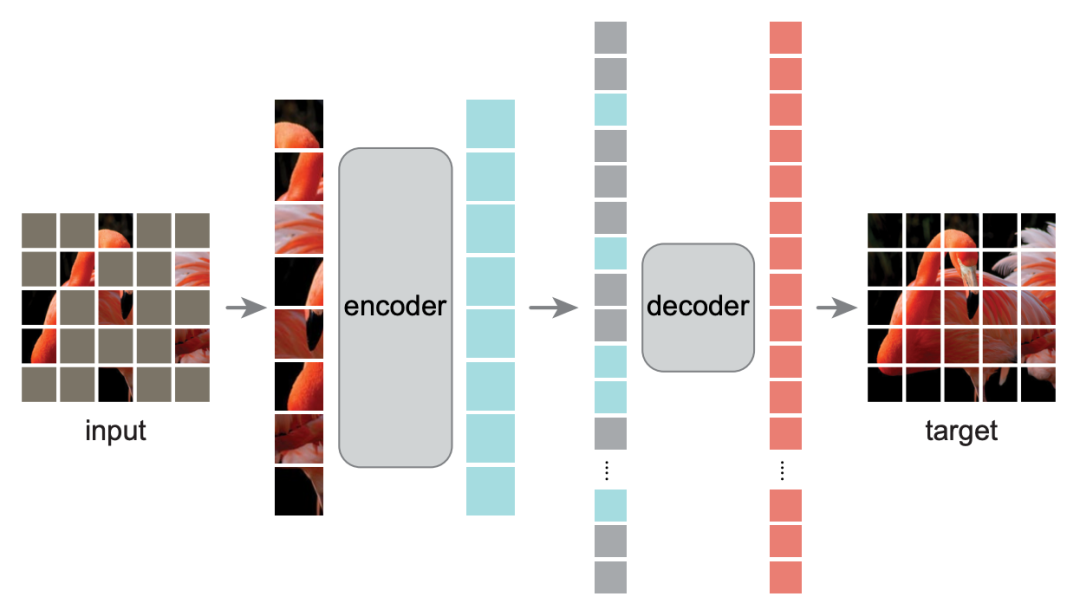
如下图所示,MAE 将模型分为 encoder 和 decoder 两部分,并且具有“encoder深、decoder 浅”的特点,然后它将 [MASK] 只放到 decoder 中,而 encoder 不处理 [MASK]。这样一来,encoder 要处理的序列就变短了,最关键的一步是,MAE 使用了 75% 的 mask 比例,这意味着 encoder 的序列长度只有通常的 1/4,加上“encoder 深、decoder 浅”的特点,总的来说模型的预训练速度快了 3 倍多!
▲ MAE模型示意图
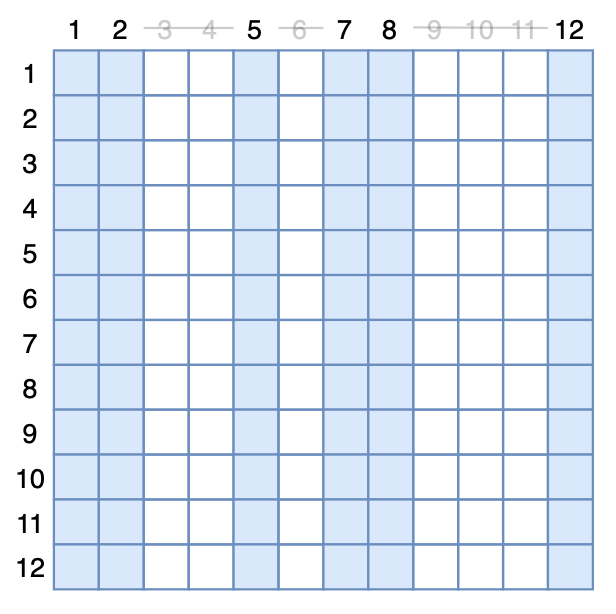
我们也可以从另一个角度来实现 MAE 模型:MAE 把 [MASK] 从 encoder 中移除,这等价于剩下的 token 不与被 mask 掉的 token 交互,而对于 Transformer 模型来说,token 之间的交互来源于Self Attention,所以我们依然可以保持原始输入,但在 Attention 矩阵中 mask 掉对应的列。如图所示,假设第
个 token 被 mask 掉,事实上就相当于 Attention 矩阵的第
列的所有元素被强制置 0:
▲ MAE的等价Attention Dropout示意图
当然,从实用的角度看,这种做法纯粹是浪费算力,但它有助于我们得到一个有意思的理论结果。我们设有
的输入 token,原始的 Attention 矩阵为
(softmax 后的),定义
为一个
矩阵,它的第
列为 0、其余都为 1,然后定义随机矩阵
,它以
的概率为全1矩阵,以
的概率为
,那么 MAE 模型可以写成
![]()
这里
是指将矩阵重新按行归一化;
时逐个元素对应相乘;当有多个 Attention 层时,各个 Attention 层共用同一批
。
这样,我们将 MAE 转换为了一种特殊的 Attention Dropout。那么同样按照微调阶段“取消 Dropout”的做法,我们知道它对应的模型应该是
![]()
其中第二个等号是因为
是一个第
列为
、其余为 1 的矩阵,那么 事实上就是一个全为
的矩阵,所以与
相乘的结果等价于
直接乘以常数
;第三个等号则是因为全体元素乘以同一个常数,不影响归一化结果。
从这个结果中看到,对于 MAE 来说,“取消Dropout”之后跟原模型一致,这说明了 MAE 相比原始的 MLM 模型,不仅仅是速度上的提升,还具有更好的预训练与微调的一致性。
![]()
反过来想,既然 MAE 也可以视为一种 Dropout,而 Dropout 有防止过拟合的作用,那么我们能不能将 MAE 的做法当作一种防止过拟合的正则化手段来使用呢?如下图所示,在训练阶段,我们可以随机扔掉一些 token,但要保持剩余 token 的原始位置,我们暂且称之为“DropToken”:
之所以会这样想,是因为常规的 Dropout 虽然通常被直接地理解为采样一个子网络训练,但那纯粹是直观的想象,实际上 Dropout 的加入还会降低训练速度,而 DropToken 由于显式了缩短了序列长度,是可以提高训练速度的,如果有效那必然是一种非常实用的技巧。此外,有些读者可能已经试过删除某些字词的方式来进行数据扩增,它跟 DropToken 的区别在于 DropToken 虽然删除了一些 Token,但依然保留了剩余 token 的原始位置,这个实现依赖于 Transformer 结构本身。
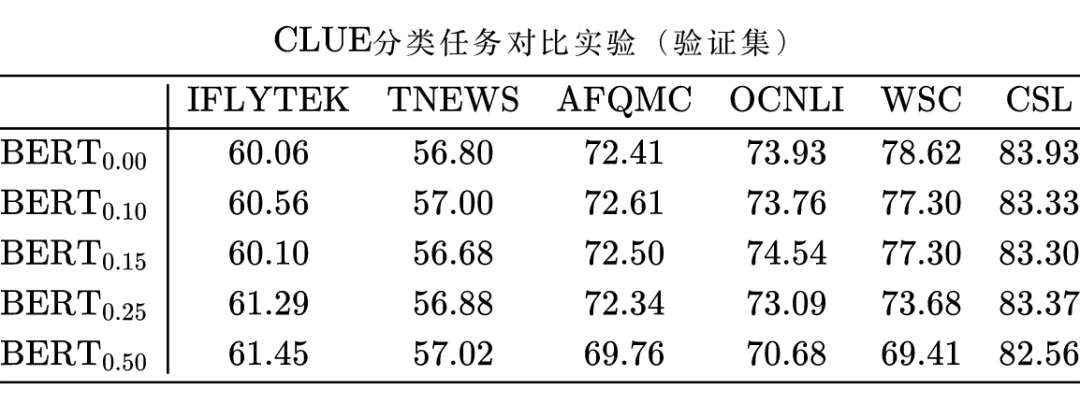
在 CLUE 上做的几个实验对比,基准模型为 BERT base,下标的数字是 drop 比例,最终的效果参差不齐,除了 IFLYTEK 明确有效外,其他看缘分(其实很多防止过拟合手段都这样),最优 drop 比例在 0.1~0.15 之间:
![]()
![]()
本文从 Dropout 的视角考察了MLM 和 MAE两个模型,它们均可视为特殊的 Dropout,从这个视角中,我们可以得到了一种修正 MLM 的不一致性的技巧,以及得到一种类似 MAE 的防止过拟合技巧。
[
1] https://arxiv.org/abs/1906.08237
[2] https://arxiv.org/abs/2003.10555
[3] https://arxiv.org/abs/2004.13922
[4] https://
kexue.fm/archives/8739
[5] https://arxiv.org/abs/2111.06377
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()