
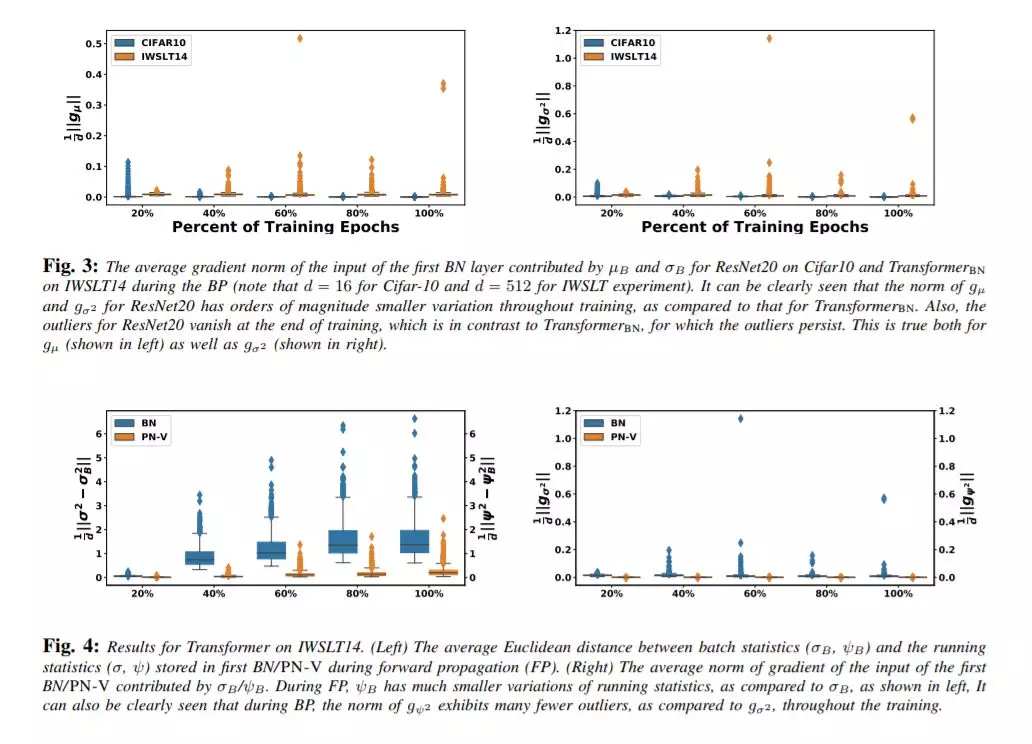
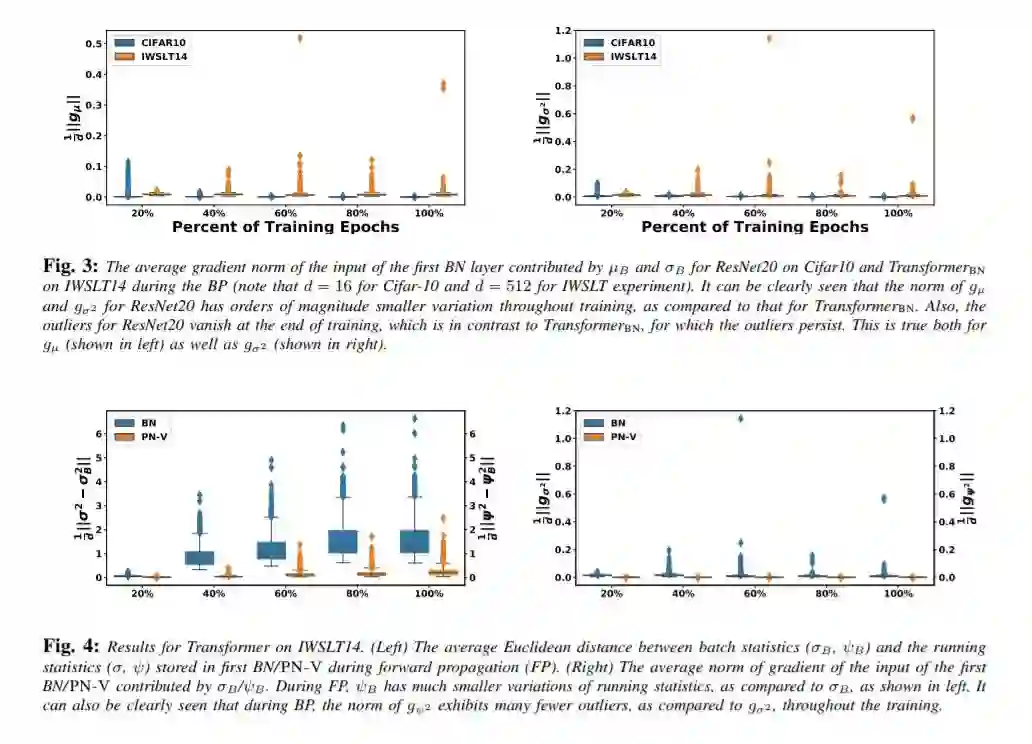
自然语言处理(NLP)中神经网络模型的标准归一化方法是层归一化(LN)。这不同于计算机视觉中广泛采用的批量归一化(BN)。LN在NLP中的优先使用主要是由于经验观察,使用BN会导致NLP任务的性能显著下降;然而,对其根本原因的透彻理解并不总是显而易见的。在本文中,我们对NLP transformers 模型进行了系统的研究,以了解为什么BN与LN相比性能较差。我们发现,整个批处理维度的NLP数据统计在整个训练过程中呈现出较大的波动。这导致不稳定,如果BN是天真地执行。为了解决这个问题,我们提出Power 归一化(PN),一种新的归一化方案, 解决这个问题(i)放松零均值归一化的BN, (ii) 将运行二次平均,而不是每批统计数据稳定的波动,和(iii)使用一个近似反向传播。在温和的假设下,我们从理论上证明了PN相对于BN会导致更小的Lipschitz常数的损失。此外,我们证明了近似的反向传播方案会导致有界梯度。我们在一系列NLP任务中对Transformer的PN进行了广泛的测试,结果表明它的性能显著优于LN和BN。特别是,PN在IWSLT14/WMT14上的表现比LN好0.4/0.6个BLEU,在PTB/WikiText-103上的表现比LN好5.6/3.0个PPL。
成为VIP会员查看完整内容
相关内容

加州大学伯克利分校(University of California, Berkeley),是美国最负盛名且是最顶尖的一所公立研究型大学,位于旧金山东湾伯克利市的山丘上。创建于1868年,是加州大学十个分校中历史最悠久的一所。加州大学伯克利分校在世界范围内拥有崇高的学术声誉,拥有丰富的教学资源,研究水平非常坚厚,与斯坦福大学、麻省理工学院等一同被誉为美国工程科技界的学术领袖。

相关VIP内容
相关资讯
相关论文