

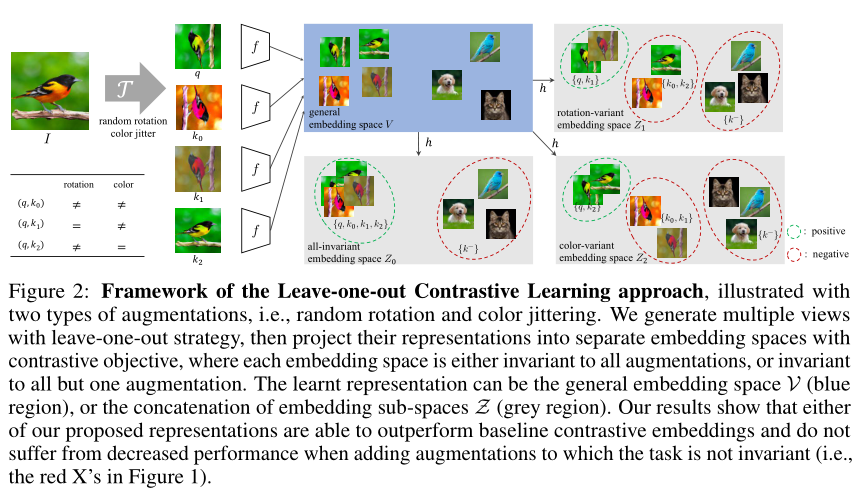
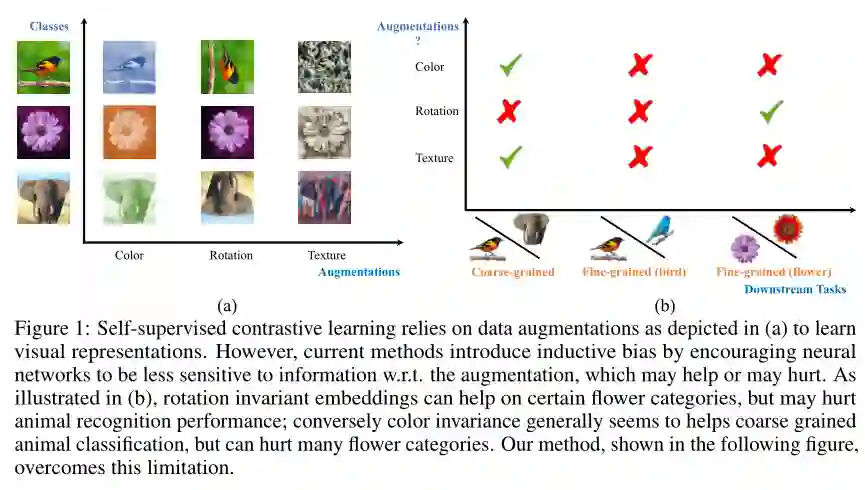
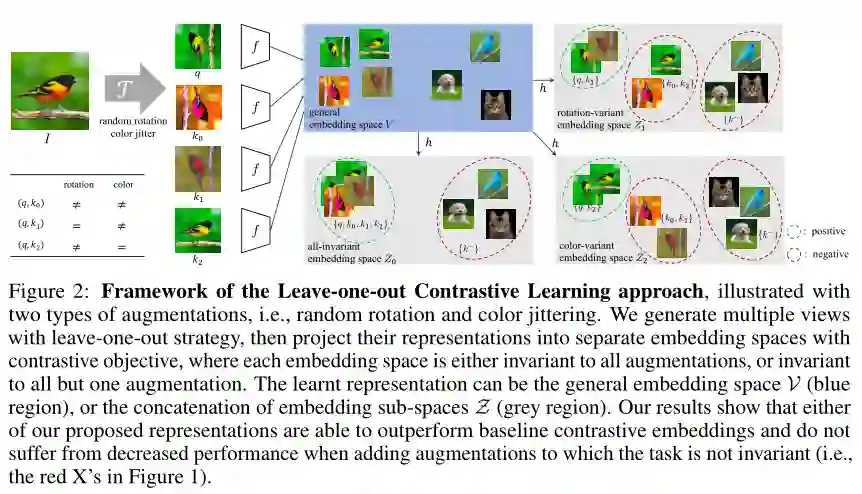
最近的自监督对比方法已经能够产生令人印象深刻的可转移的视觉表示通过学习对不同的数据增强保持不变。然而,这些方法隐式地假设了一组特定的表示不变性(例如,颜色不变性),并且当下游任务违反了这一假设时,它们的性能会很差(比如区分红色和黄色的汽车)。我们介绍了一个对比学习框架,它不需要特定的、任务相关的不变性的先验知识。我们的模型学会了通过构建单独的嵌入空间来捕捉变化的和不变的视觉表示因素,每个嵌入空间都是不变的,除了数据增强部分。我们使用一个共享主干的多头网络,它在每次扩展中捕获信息,单独在下游任务上优于所有基线方法。我们还发现,不变空间和变化空间的连接在我们研究的所有任务中性能最好,包括粗粒度、细粒度和较少的下游分类任务,以及各种数据破坏的情况下。


成为VIP会员查看完整内容

相关内容

Arxiv
4+阅读 · 2020年2月13日

相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2020年2月13日