矩阵视角下的Transformer详解(附代码)

©PaperWeekly 原创 · 作者 | 孙裕道
单位 | 北京邮电大学博士生
研究方向 | GAN图像生成、情绪对抗样本生成

引言


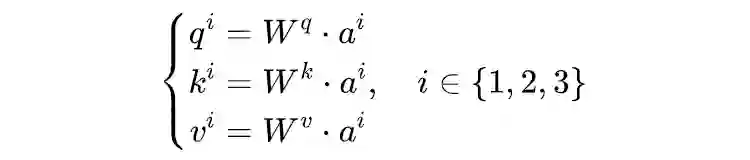
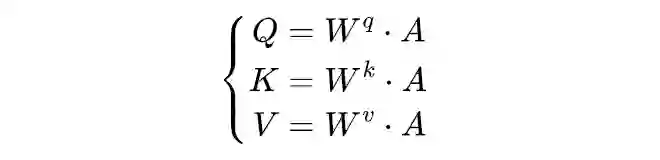
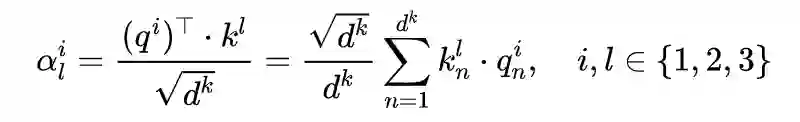
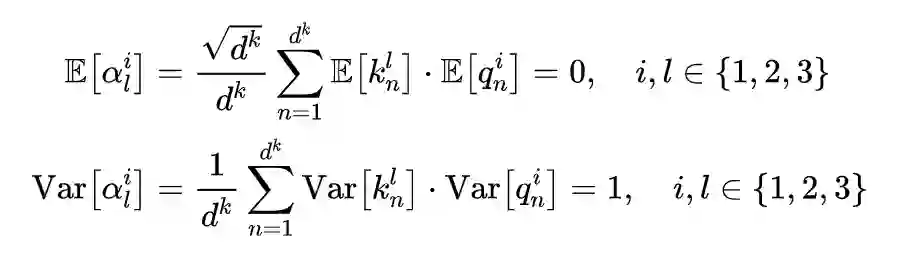
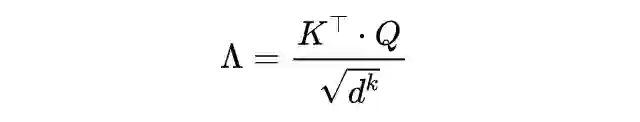
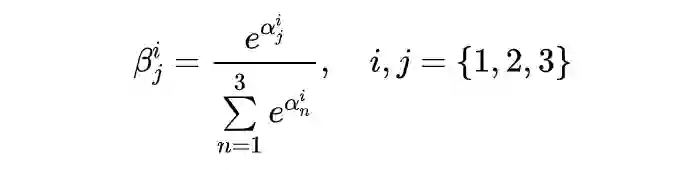
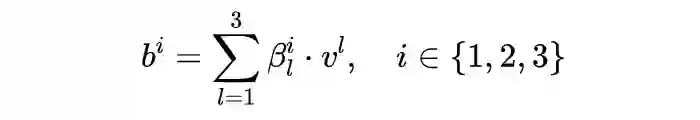
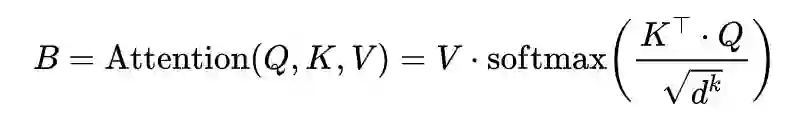
2.2 Multi-Head Attention
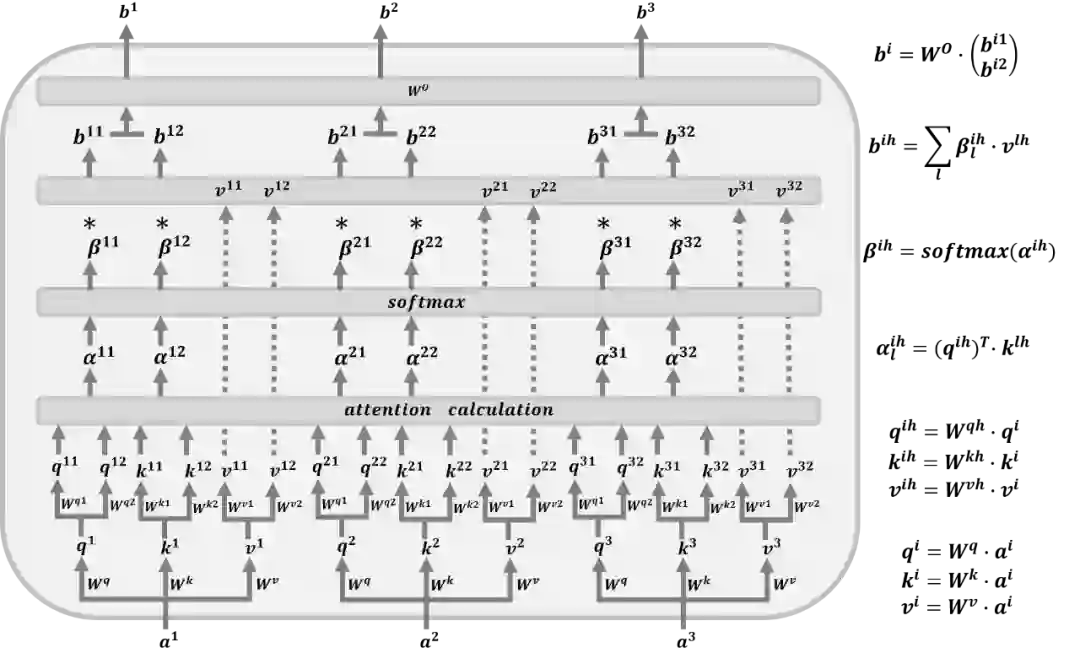
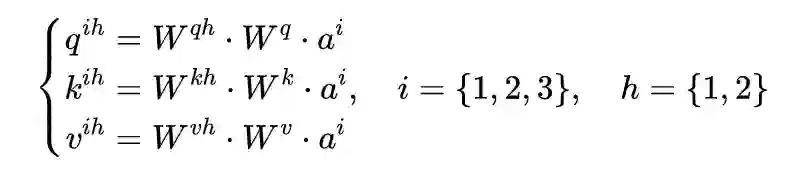
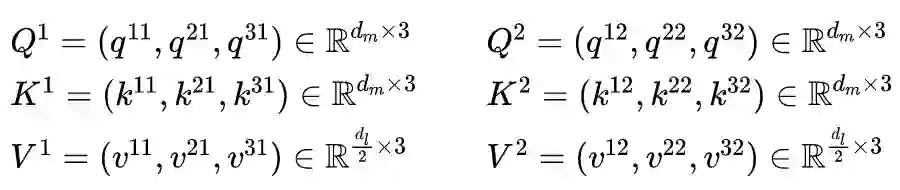
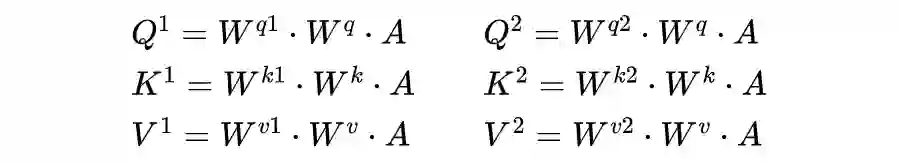
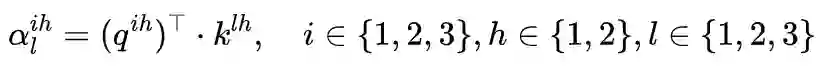
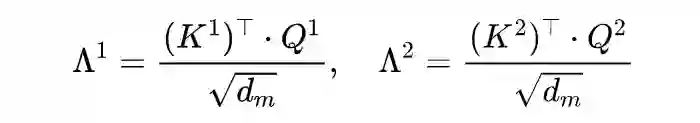
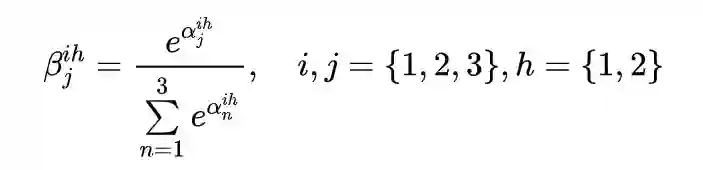
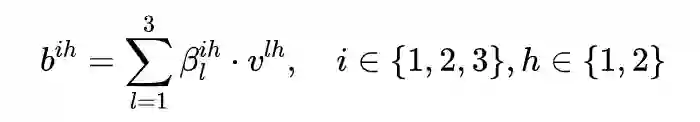
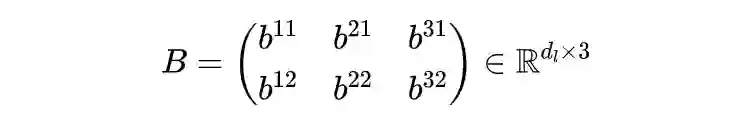
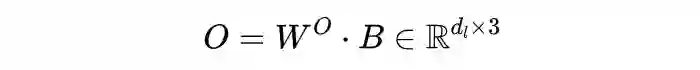
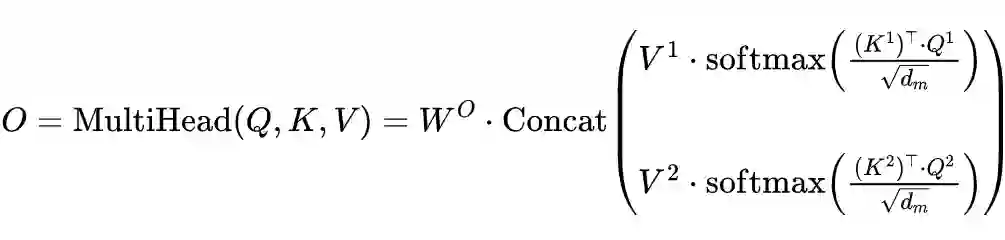
2.3 Mask Self-Attention
-
Transformer 的 Encoder 中如果输入一句话的 word 长度小于指定的长度,为了能够让长度一致往往会用 0 进行填充,此时则需要用 Mask Self-Attention 来计算注意力分布。 -
Transformer 的 Decoder 的输出是有时序关系的,当前的输出只与之前的输入有关,所以此时算注意力分布时需要用到 Mask Self-Attention。
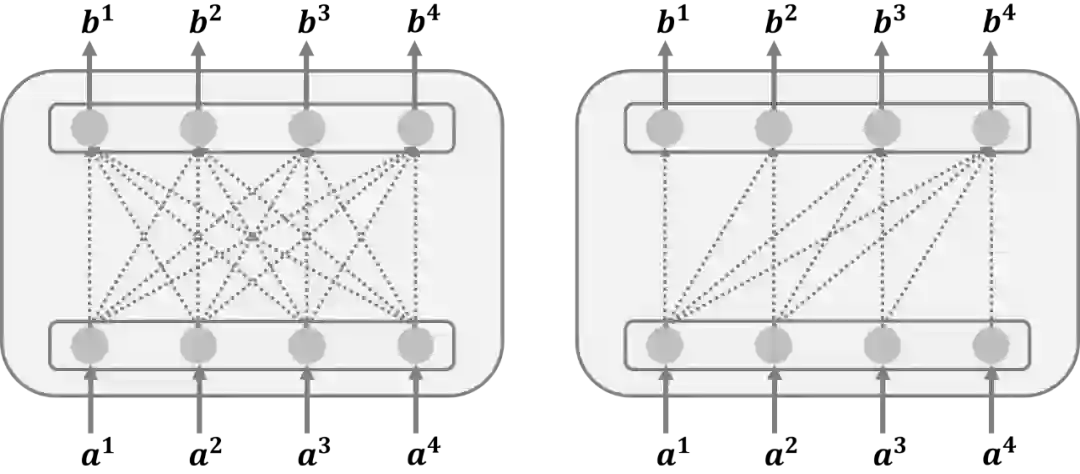

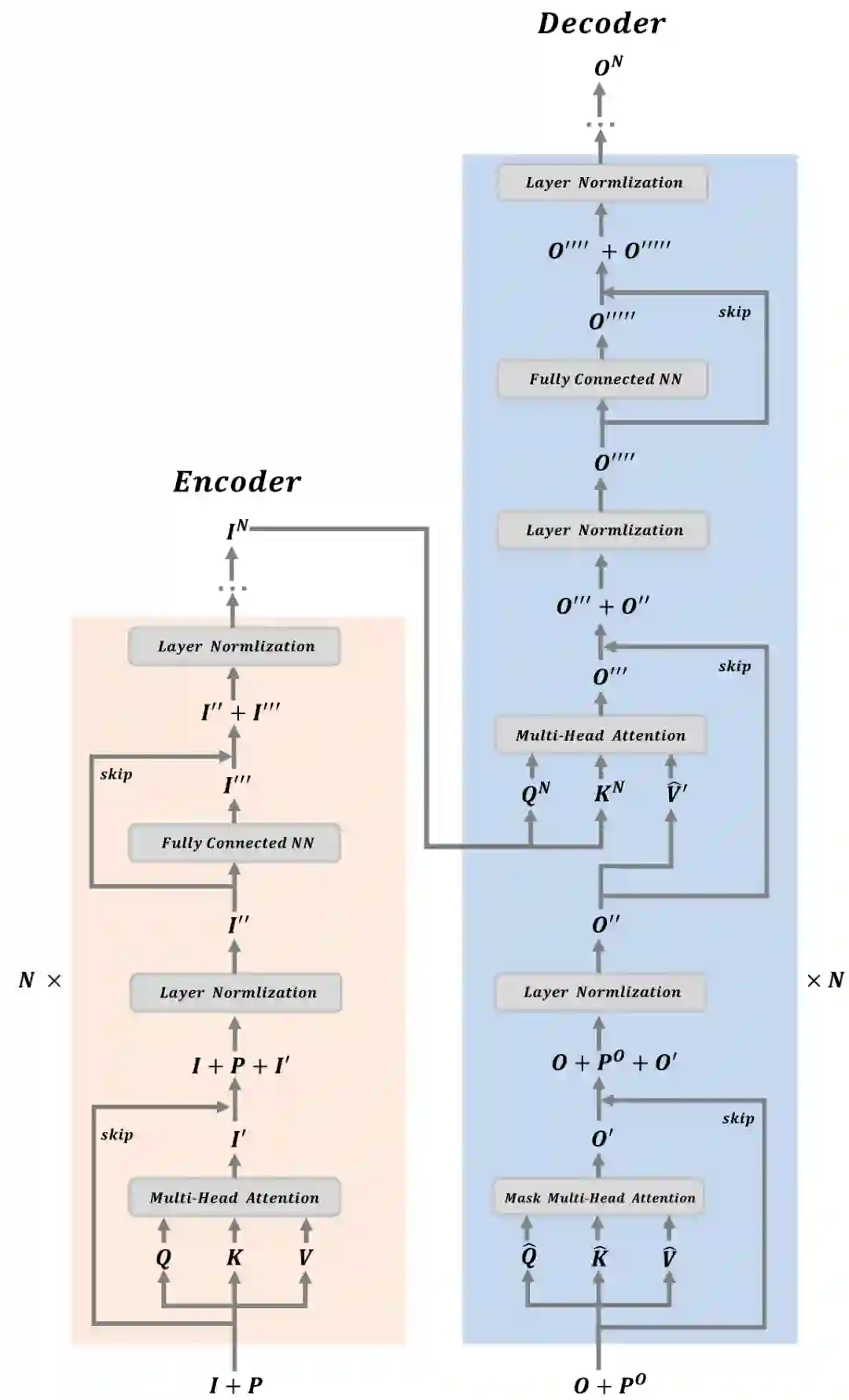
以上对 Transformer 中的核心内容即自注意力机制进行了详细解剖,接下来会对 Transformer 模型架构进行介绍。Transformer 模型是由 Encoder 和 Decoder 两个模块组成,具体的示意图如下所示,为了能够对 Transformer 内部的操作细节进行更清晰的展示,下图以矩阵运算的视角对 Transformer 的原理进行讲解。
Encoder 模块操作的具体流程如下所示:


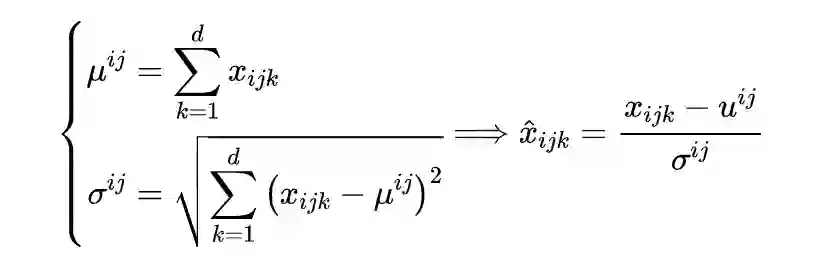
Decoder 模块操作的具体流程如下所示:
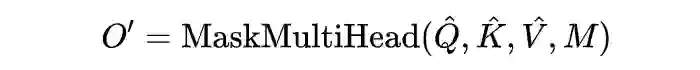
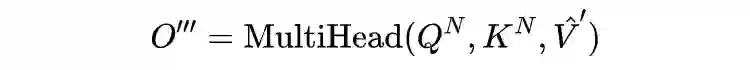

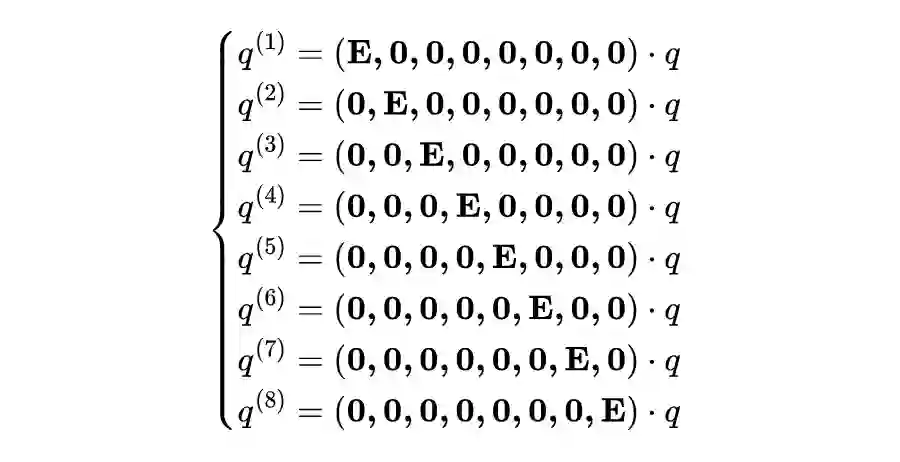

其中权重矩阵 。
import torch
import torch.nn as nn
import os
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (self.head_dim * heads == embed_size), "Embed size needs to be div by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N =query.shape[0]
value_len , key_len , query_len = values.shape[1], keys.shape[1], query.shape[1]
# split embedding into self.heads pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
energy = torch.einsum("nqhd,nkhd->nhqk", queries, keys)
# queries shape: (N, query_len, heads, heads_dim)
# keys shape : (N, key_len, heads, heads_dim)
# energy shape: (N, heads, query_len, key_len)
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy/ (self.embed_size ** (1/2)), dim=3)
out = torch.einsum("nhql, nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads*self.head_dim)
# attention shape: (N, heads, query_len, key_len)
# values shape: (N, value_len, heads, heads_dim)
# (N, query_len, heads, head_dim)
out = self.fc_out(out)
return out
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = SelfAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion*embed_size),
nn.ReLU(),
nn.Linear(forward_expansion*embed_size, embed_size)
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out
class Encoder(nn.Module):
def __init__(
self,
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length,
):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansion=forward_expansion,
)
for _ in range(num_layers)]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))
for layer in self.layers:
out = layer(out, out, out, mask)
return out
class DecoderBlock(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout, device):
super(DecoderBlock, self).__init__()
self.attention = SelfAttention(embed_size, heads)
self.norm = nn.LayerNorm(embed_size)
self.transformer_block = TransformerBlock(
embed_size, heads, dropout, forward_expansion
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, value, key, src_mask, trg_mask):
attention = self.attention(x, x, x, trg_mask)
query = self.dropout(self.norm(attention + x))
out = self.transformer_block(value, key, query, src_mask)
return out
class Decoder(nn.Module):
def __init__(
self,
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length,
):
super(Decoder, self).__init__()
self.device = device
self.word_embedding = nn.Embedding(trg_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[DecoderBlock(embed_size, heads, forward_expansion, dropout, device)
for _ in range(num_layers)]
)
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x ,enc_out , src_mask, trg_mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))
for layer in self.layers:
x = layer(x, enc_out, enc_out, src_mask, trg_mask)
out =self.fc_out(x)
return out
class Transformer(nn.Module):
def __init__(
self,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
trg_pad_idx,
embed_size = 256,
num_layers = 6,
forward_expansion = 4,
heads = 8,
dropout = 0,
device="cuda",
max_length=100
):
super(Transformer, self).__init__()
self.encoder = Encoder(
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length
)
self.decoder = Decoder(
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length
)
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
def make_src_mask(self, src):
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
# (N, 1, 1, src_len)
return src_mask.to(self.device)
def make_trg_mask(self, trg):
N, trg_len = trg.shape
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(
N, 1, trg_len, trg_len
)
return trg_mask.to(self.device)
def forward(self, src, trg):
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
enc_src = self.encoder(src, src_mask)
out = self.decoder(trg, enc_src, src_mask, trg_mask)
return out
if __name__ == '__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
x = torch.tensor([[1,5,6,4,3,9,5,2,0],[1,8,7,3,4,5,6,7,2]]).to(device)
trg = torch.tensor([[1,7,4,3,5,9,2,0],[1,5,6,2,4,7,6,2]]).to(device)
src_pad_idx = 0
trg_pad_idx = 0
src_vocab_size = 10
trg_vocab_size = 10
model = Transformer(src_vocab_size, trg_vocab_size, src_pad_idx, trg_pad_idx, device=device).to(device)
out = model(x, trg[:, : -1])
print(out.shape)
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧





