论文笔记+代码实现 | Vision GNN: An Image is Worth Graph of Nodes

目前,主流的基于深度学习的计算机视觉特征提取器主要分为经典的卷积神经网络、发展较快的Vision Transformer,以及较新的MLP,鲜有工作将图神经网络用于计算机视觉的特征提取(骨干网络)。而上个月中科大华为北大等团队合作提交的这篇论文《Vision GNN: An Image is Worth Graph of Nodes》里,提出了ViG系列网络,将图神经网络用于特征提取任务。个人觉得这项工作比较有创新性,细读了一遍并整理了一下思想。
原文地址:https://arxiv.org/abs/2206.00272
原文代码:https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/vig_pytorch
相关工作


正如我们所知,图像在计算机中以二维离散的像素构成,这相当于在欧几里得空间里的有规律的网格信息。卷积神经网络以滑窗的形式,引入了平移不变性。Vision Transformer和MLP则将图像分成了一个个块,对它们进行位置嵌入后得到一个序列作为输入。而这些方法都是基于欧几里得空间的像素或块进行处理。而图像中的物体往往是形状不规则的,所以会不会有一种更灵活的方式来提取图像的特征呢?例如在识别人体的任务中,一个人可以大致分为头部、上半身、手臂和腿。这些由关节连接的部分自然就形成了一个图结构。
早期的图神经网络通常用于图数据,例如社交网络或者分子结构。图神经网络在计算机视觉领域的应用,目前也仅限于点云分类、场景图生成和人体动作识别。也就是说,目前的图神经网络只能处理自然形成的图的特定视觉任务。对于计算机视觉的一般应用,作者提出了一个基于图神经网络的骨干网络,直接处理图像数据。
模型结构
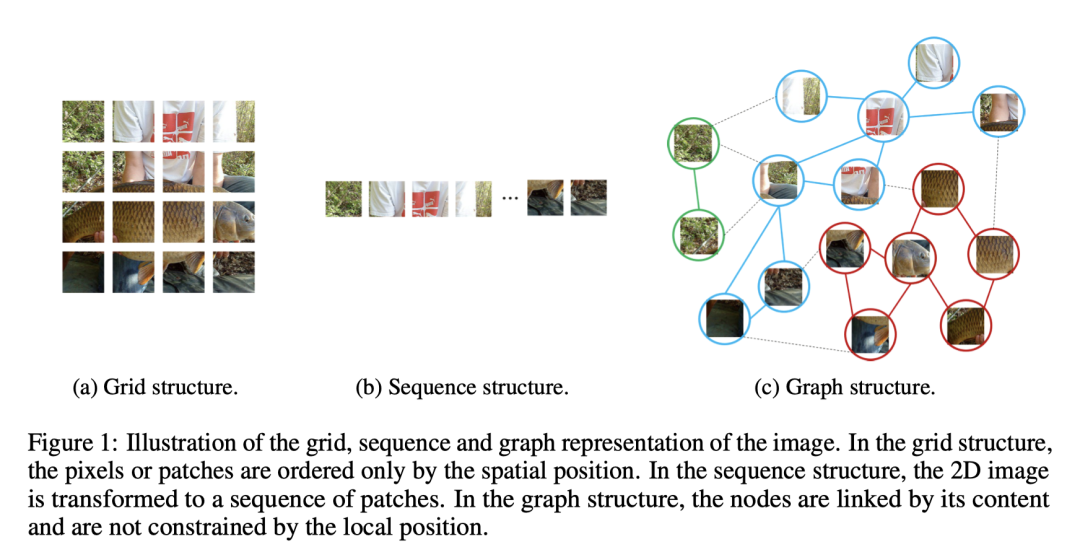
图像的图结构的表示:作者首先对图像的图结构的表示,首先将图片按照Vision Transformer任务的方法分成N个块,随后按照块的K个近邻,将块的D维嵌入以无向图的方式连接起来(相同类别的块用边连接),最后得到图的表示。在图结构的表示中,节点是基于其类别连接的,而不是基于相邻位置。图结构比欧氏空间的网格或序列更容易为复杂的物体建模,并且基于图的最近研究(GraphSAGE,GIN等)带来的特性也能更好的用于视觉任务中。
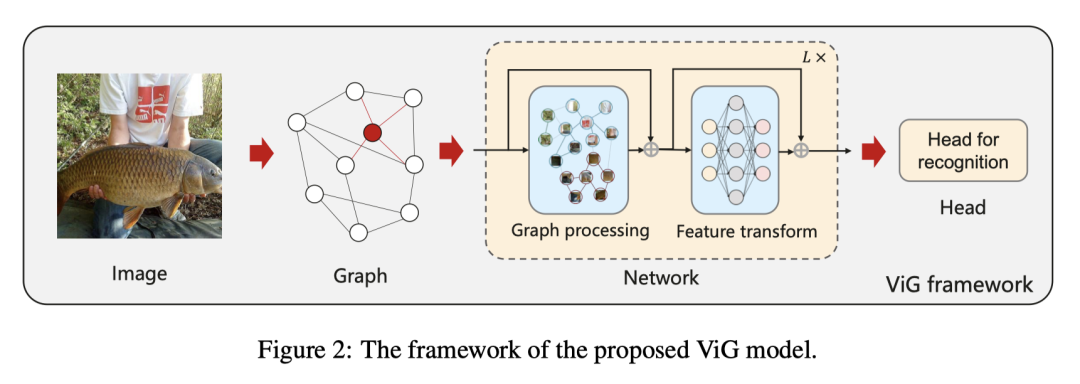
ViG块:作者提出了ViG模型,在对图像进行图结构的表示后,送入由ViG块构成的网络中。如图所示,每一个ViG块都由图处理(Graph Processing)和特征变换(Feature Transform)组成,对于图处理部分,和使用图神经网络处理一般的图数据一致,都是聚合(Aggregate)特征和更新(Update)特征这两个操作。作者在这里提出了多头更新(Multi-head Update),即将聚合的特征分为h个头,分别更新并串联。这样保证了特征的多样性。
视觉任务一定会使用更深的网络,而基于图网络的任务为了防止过平滑现象,为了解决这个问题,作者在ViG块中引入了更多的特征变换和非线性激活操作。在图卷积的前后都加入了线性层,在图卷机后面再增加一个激活层。作者在每个节点上又都添加了含有两个全连接层的前馈网络,进一步提高了特征转换能力,缓解了过度平滑现象。公式如下:
作者用ResGCN做了比较,证明了ViG可以保持特征的多样性。
两种模型结构:目前的特征提取模型有各向同性(isotropic)结构和金字塔(pyramid)结构两种,各向同性结构指主干在整个网络中具有同等大小和形状的特征,例如ViT和ResMLP,作者提出了ViG- Ti(ny),ViG-S(mall)和ViG-B(ase)三个结构,块数N=196,节点近邻K随着深度从9到18不等,多头结构的h=4,得到三个模型如下结构:
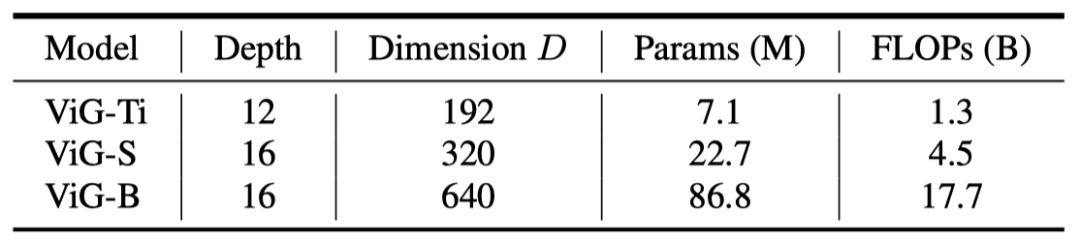
而对于金字塔结构大家一定不难理解,ResNet,PVT,Swin等等都有这个结构,即随着stage的增加,特征图的长宽越来越小,特征通道数越来越大。作者提出了pyramidViG- Ti(ny),pyramidViG-S(mall),pyramidViG-M(edium)和pyramidViG-B(ase)四个结构,如下:
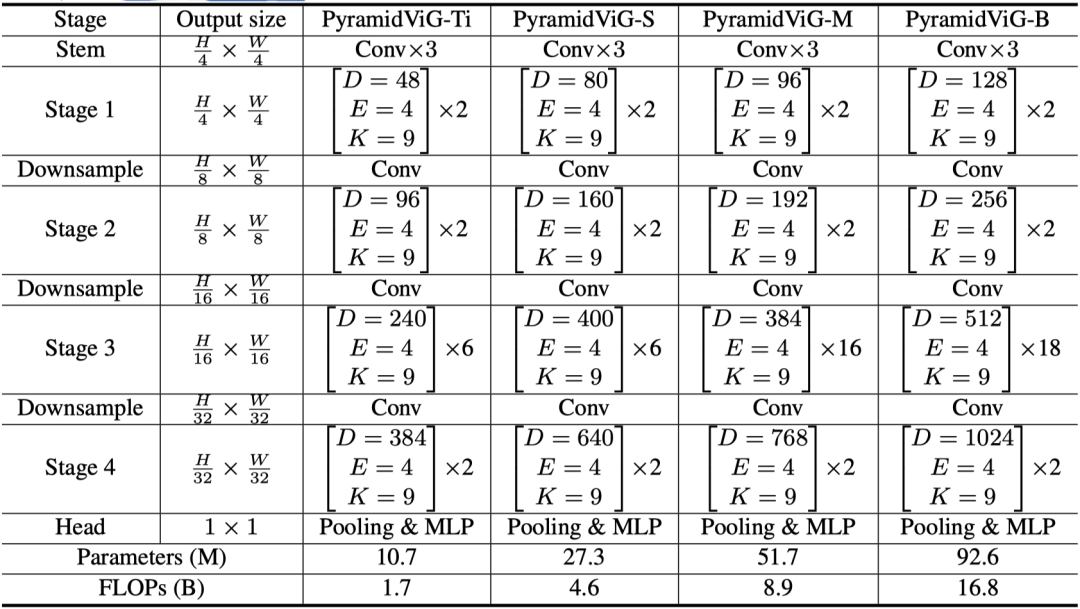
借鉴Vision Transformer,ViG也使用了位置编码,而对于pyramidViG,作者借鉴了Swin-Transforwer使用了相对位置编码,并在图表示中加入到特征距离中。
实验结果
在策略上,对于所有的ViG模型,作者都是用了ResGCN中的dilated aggregation,使用GELU作为激活函数。使用ImageNet数据集时,使用和DeiT一致的训练策略,在使用COCO数据集时,使用RetinaNet和Mask R-CNN的检测模型结构。
实验结果就放在这里了:
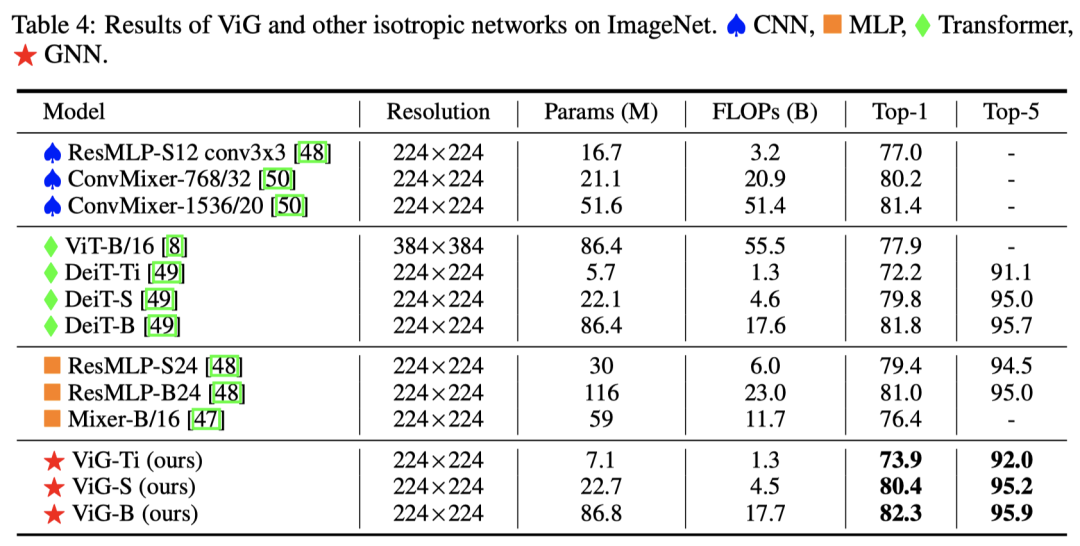
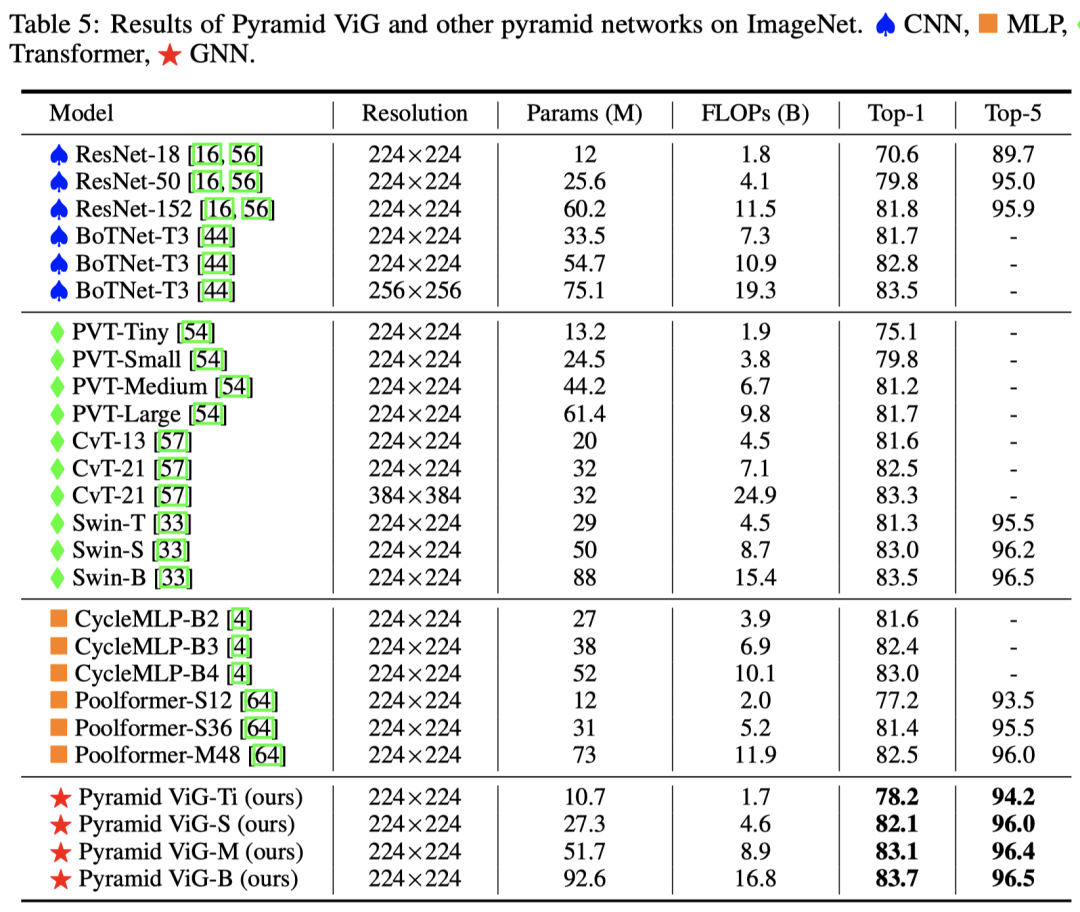
可以说ViG模型是达到了不错的效果。
此外,作者还对不同的图神经网络种类做了对比实验,并对是否添加线性层和前馈网络层进行了消融实验:
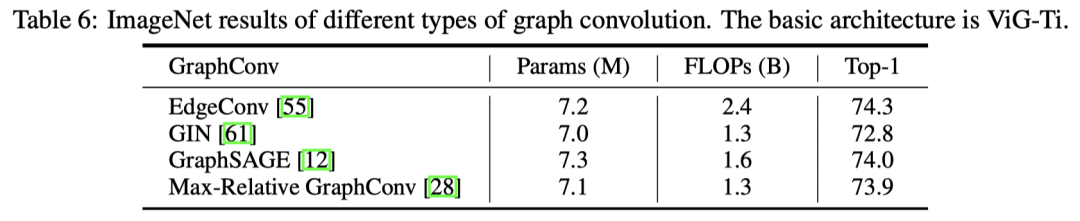

对于确定最佳的近邻数,作者也进行了实验:

(检测实验就不提了hhh
此外,作者还对不同层的图像的块进行了可视化,可以发现:在浅层,邻居节点往往是根据低层次和局部特征来选择的,如颜色和纹理。在深层,中心节点的邻居更具语义性,属于同一类别。这说明,ViG网络可以通过其内容和语义表示逐渐将节点联系起来,并帮助更好地识别物体。

代码示例
import torch.nn as nn
from gcn_lib.dense.torch_vertex import DynConv2d
# gcn_lib is downloaded from https://github.com/lightaime/deep_gcns_torch
class GrapherModule(nn.Module):
"""Grapher module with graph conv and FC layers """
def __init__(self, in_channels, hidden_channels, k=9, dilation=1, drop_path=0.0):
super(GrapherModule, self).__init__()
self.fc1 = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 1, stride=1, padding=0),
nn.BatchNorm2d(in_channels),
)
self.graph_conv = nn.Sequential(
DynConv2d(in_channels, hidden_channels, k, dilation, act=None),
nn.BatchNorm2d(hidden_channels),
nn.GELU(),
)
self.fc2 = nn.Sequential(
nn.Conv2d(hidden_channels, in_channels, 1, stride=1, padding=0),
nn.BatchNorm2d(in_channels),
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
x = x.reshape(B, C, -1, 1).contiguous()
shortcut = x
x = self.fc1(x)
x = self.graph_conv(x)
x = self.fc2(x)
x = self.drop_path(x) + shortcut
return x.reshape(B, C, H, W)
class FFNModule(nn.Module):
"""Feed-forward Network """
def __init__(self, in_channels, hidden_channels, drop_path=0.0):
super(FFNModule, self).__init__()
self.fc1 = nn.Sequential(
nn.Conv2d(in_channels, hidden_channels, 1, stride=1, padding=0),
nn.BatchNorm2d(hidden_channels),
nn.GELU()
)
self.fc2 = nn.Sequential(
nn.Conv2d(hidden_channels, in_channels, 1, stride=1, padding=0),
nn.BatchNorm2d(in_channels),
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
shortcut = x
x = self.fc1(x)
x = self.fc2(x)
x = self.drop_path(x) + shortcut
return x
class ViGBlock(nn.Module):
"""ViG block with Grapher and FFN modules """
def __init__(self, channels, k, dilation, drop_path=0.0):
super(ViGBlock, self).__init__()
self.grapher = GrapherModule(channels, channels * 2, k, dilation, drop_path)
self.ffn = FFNModule(channels, channels * 4, drop_path)
def forward(self, x):
x = self.grapher(x)
x = self.ffn(x)
return x-END-
