图注意力网络

在论文笔记《Inductive Representation Learning on Large Graphs》中,我们介绍了一种归纳式学习图节点特征表示的算法--GraphSAGE。 在该笔记的最后提到了该方法的一些不足,如1)为了计算方便,每个节点采样同等数量的邻居节点;2)邻居的特征通过Mean、 LSTM、Max-Pooling等方式聚集,平等对待所有邻居节点。基于GraphSAGE,本篇论文引入了注意力机制,通过学习赋予不同邻居节点差异化的重要性且避免了采用过程。同时,邻居节点的特征是根据权值来聚集的,即相似的节点贡献更大。
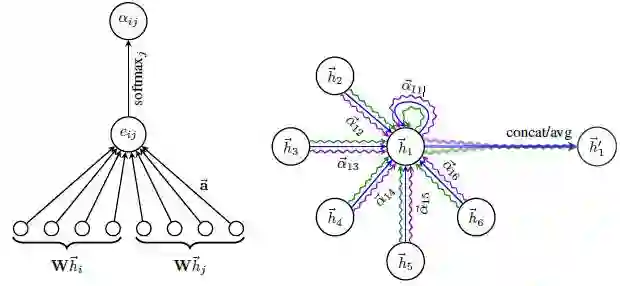
模型:
给定图上所有节点在当前层的输入h,假设我们当前需要更新节点i的表示,j表示节点i的一个邻居。那么节点j对i的重要性系数的计算公式如下:
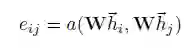
其中,a为注意力模型,线性变换参数W为可学习的权值矩阵,h_i和h_j分别是i和j节点在上一层的输出,亦即本层的输入。在上面的计算中,节点i是可以attend到全部的节点。考虑图本身的结构特征后,使用掩码将节点i的非邻居节点全部掩盖。由于下面的公式使用了softmax函数,mask中非i邻居节点的位置可以置为负无穷。
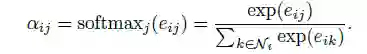
N_i表示节点i的所有邻居。本篇论文中,注意力机制是由一层全连接网络实现的,如下:

Alpha为权值向量。在最终的聚集过程中,按注意力机制得到的权值进行加权求和并紧跟一层非线性变换,如下:
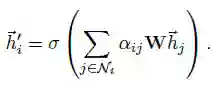
进一步,参考谷歌机器翻译中采用的“multi-head self attention",本文也使用了“multi-head”机制,最后将各个头attention的结果进行拼接或取平均(本文实验用了拼接)。
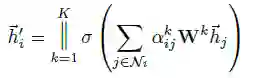
模型的优点:
计算高效。模型中的注意力机制可以在所有的边上并行,节点的特征计算也是可以并行的。模型不需要类似特征分解这样高复杂度的矩阵操作。
不同于GCN,模型允许为不同的邻居赋予不同的权值。对注意力权值的分析可以增加模型的解释性。
注意力机制的参数是共享的,且可以区分对待有向边,因此可以扩展到有向图上。同时,使用局部邻居聚集的方式也保证了模型可以扩展到训练过程未见过的节点。
避免了GraphSAGE中采用固定数量的邻居。
模型的缺点:
因为attention本质上是在所有的节点(不仅仅是邻居节点)上计算的,当图的节点数目过大时,计算会变得非常低效。作者在论文中提出了这个问题,并留作未来的工作。
评估:
使用的数据集有:Cora,Citeseer和PPI。 在transductive learning任务上,GAT相比之前的state-of-the-art GCN有显著提升。 在inductive learning任务航,GAT相比GraphSAGE的提升更为明显,micro-averaged F1由0.612提升到0.942。
总结:
本篇论文提出的方法能够有效的进行邻居特征聚集,但是问题是还不能在大规模图上应用(全局attention的限制)。




