论文笔记之attention mechanism专题1:SA-Net(CVPR 2018)
发表于CVPR2018
原文链接:https://arxiv.org/abs/1802.08817
“ 作者观察发现分类任务学习语义特征,相似度匹配任务学习表观特征,利用表观特征和语义特征的互补性来构建跟踪器。因此,作者通过构建双重双胞胎网络SA-Net来实现。SA-Net由表观分支和语义分支组成,其中每个分支都是一个双胞胎网络。另外为语义分支提出一个通道注意力机制。”
01总揽
—
一般来说,设计一个高性能跟踪器的关键是找到同时具有判别性和泛化性的特征表达和相应的分类器。
判别性要求跟踪器能很好的区分背景和目标,哪怕背景中有与目标相似的目标存在;泛化性要求跟踪器在目标表观发生变化的时候也依旧能找到目标。通常,判别性和泛化性需要在跟踪的过程中被加强,但是在线更新导致跟踪器不具实时性,尤其是当存在大量参数时。
目前存在两种实时的基于CNN的跟踪器:GOTURN和SiamFC。GOTURN把跟踪问题视为目标框回归问题,SiamFC把跟踪问题视为相似学习问题。SiamFC表现出了比GOTURN更好的跟踪性能。这主要归功于全卷积网络结构,允许SiamFC充分利用离线数据而更具判别性,但是SiamFC的泛化性能不佳。本文致力于改善SiamFC的泛化性能。
分类任务中学习得到的特征具有强烈的语义信息,对物体的表观变化不敏感。而这些特征是对在相似性学习任务中学习到的表观特征的理想补充。为此,作者设计SA-Net,SA-Net由表观分支A-Net和语义分支S-Net组成,其中每个分支都是一个双胞胎网络。

在语义分支中,不同的目标激活不同的通道组,所以赋予那些对跟踪特定目标发挥更重要作用的通道更高的权重以此增强跟踪器的判别能力。因此作者进一步提出通道关注机制,根据目标对象和周围环境的通道响应来计算每个通道的响应。对于语义分支,进一步提出通道关注机制来实现最小程度的目标适应。
为了维持这两个分支的异质性,对这两个分支分别训练,直到每个分支都得到相似性得分的时候才将这两个分支联合起来。
A-Net
—
A-Net:网络结构同SiamFC,但是模型是作者自己训练的。同SiamFC一样,采用logistic损失。
S-Net
—
S-Net:直接采用分类数据集预训练的网络作为S-Net的特征提取部分,并且连接conv4和conv5作为最终的特征。
之前分析过,高级语义信息对目标表观变化更鲁棒,因此使得跟踪器泛化能力更强,但是判别性不足。为了增强语义分支的判别能力,设计了一个通道注意模块。
注意模块的输入为:conv4和conv5连接之后的特征;输出为:通道权重。通道权重与对应通道相乘之后输入融合模块。注意模块先对特征进行max-pooling变成3*3大小,然后利用两层感知机产生通道系数,最终,使用sigmoid函数生成最终的输出权重。
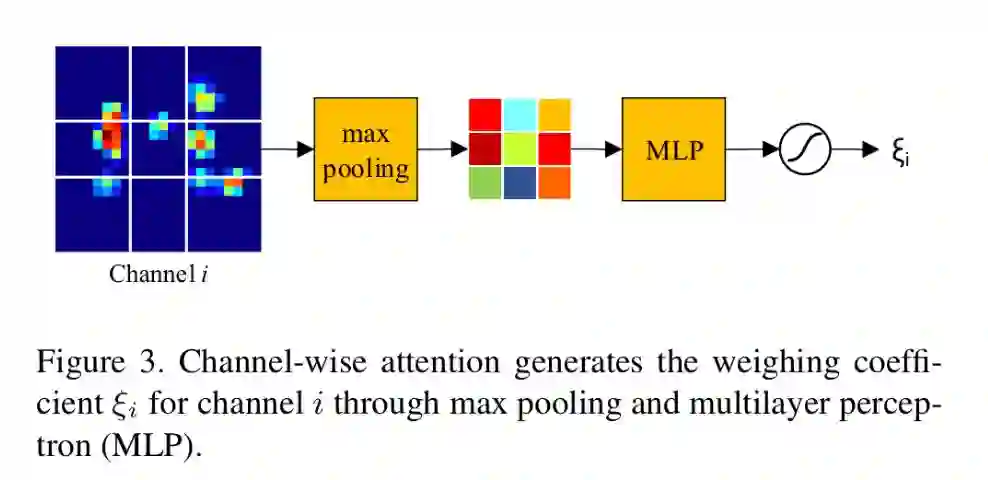
为了让语义特征适合相关操作,在注意模块之后还加了一个融合模块,融合模块是一个1*1的ConvNet,融合只在相同的层中进行。
PS:S-Net的搜索区域对应的那支没有注意模块,其他都一样。同A-Net一样,使用logistic损失。
疑问汇总
—
疑问1:为什么S-Net的输入不只包含目标区域也包含背景区域,或者说为什么注意模块的输入要有目标周围的区域 ?
直观上来讲,在跟踪不同物体的时候不同通道所起的作用不同。在跟踪某些物体时某些通道可能非常重要,但是在跟踪另外一些物体时,这些通道可能就不重要了。如果可以根据目标来适应通道的重要性,相应的也能提高跟踪器的性能,we achieve the minimum functionality of target adaptation. 因此,不止目标是相关的,背景也相关。因此,在注意模块中,输入的是目标和周围区域的特征而不只是目标的特征。
疑问2:为什么搜索区域提取特征的时候不加注意模块?
个人理解(论文中没有说明):(需要注意的是S-Net的CNN部分不进行微调)其实加不加效果都是一样的,因为注意模块做的工作是把某个通道的权重增大,而这个权重是学出来的,在一个通道上增加注意模块跟在两个通道上都加权重是一样的,只不过在一个通道上加注意模块学到的权重假设是w,那么在两个通道上加注意模块学到的权重可能是w/2。对于训练而言,可能就是收敛的速度不同。
疑问3:为什么要单独训练SA-Net的两支?
作者观察到,对于一些训练样本,利用语义线索进行跟踪比利用表观线索进行跟踪更容易,而对于另外一些样本则相反。用第一种情况来举例,即对于那些利用语义线索进行跟踪比利用表观线索进行跟踪更容易的样本而言,如果两分支同时训练,损失函数最小的时候相当于只有语义分支时。这个时候训练样本其实相当于没有优化表观层,所以同时训练两分支得到的模型不如分别训练得到的模型好。
疑问4:为什么不对S-Net进行微调?
因为如果对语义分支进行更新的话,两分支学习到的模型具有同质性,而且虽然微调可以改善S-Net的跟踪性能,但是整个网络结构的跟踪性能却变差了,这是因为两模型不具备互补性了,当两个模型具有异质性的时候,互补性最好,可以理解为利用一个物体的一个属性理解这个物体容易还是利用一个物体的两个属性理解这个物体容易,这里可以参考数据的异质性来理解模型的异质性。
研究的样本的重要属性上总是存在差异(Heteroskedasticity),比如人和人之间的消费习惯可能大相径庭,这样你记录1000个人10年的月消费数据,即便他们收入流和资产完全相同,消费流也可能截然不同。在统计性质上,这种不同表现为异方差。
出处:https://www.zhihu.com/question/22246294
作者通过实验验证这种设计选择。
疑问5:为什么不在A-Net中使用channel attention?
虽然使用多层特征和添加通道注意机制能显著改善A-Net的跟踪性能,但是作者并没有这么做,这是因为:
来自不同层的表观特征在表达能力方面没有明显的不同
高层的语义特征很稀疏,但是表观特征却很密集
简单的MaxPooling算子可以泛化语义特征的描述,对于表观特征却不是这样子的。A-Net可能需要一个更复杂的注意力机制,但是相对于付出的代价而言,增益可能并不值得。
实验
—
Ablation Analysis:

App.:表观模型。
Sem.:语义模型,只有融合模块,未使用多层特征,未使用注意模块。
ML:使用多层特征。
Att:使用注意模块。

验证:如果两分支不具异质性的话,效果也没啥提升。
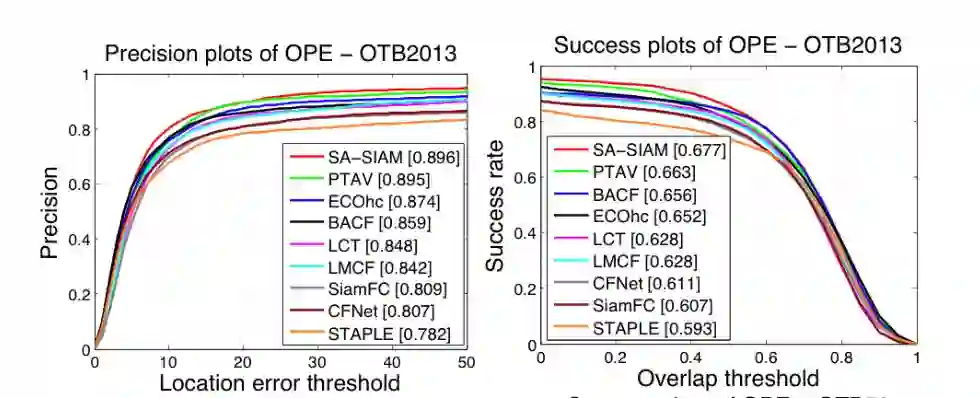
在CVPR2013上的结果。



