
计算机视觉顶会 CVPR 2019 的论文接前几天公布了接受论文:在超过 5100 篇投稿中,共有 1300 篇被接收,达到了接近 25.2% 的接收率。近期结合图卷积网络相关的应用论文非常多,CVPR最新发布的论文也有很多篇,专知小编专门整理了最新五篇图卷积网络相关视觉应用论文—零样本学习、姿态估计、人脸聚类、交互式目标标注和视频异常检测。
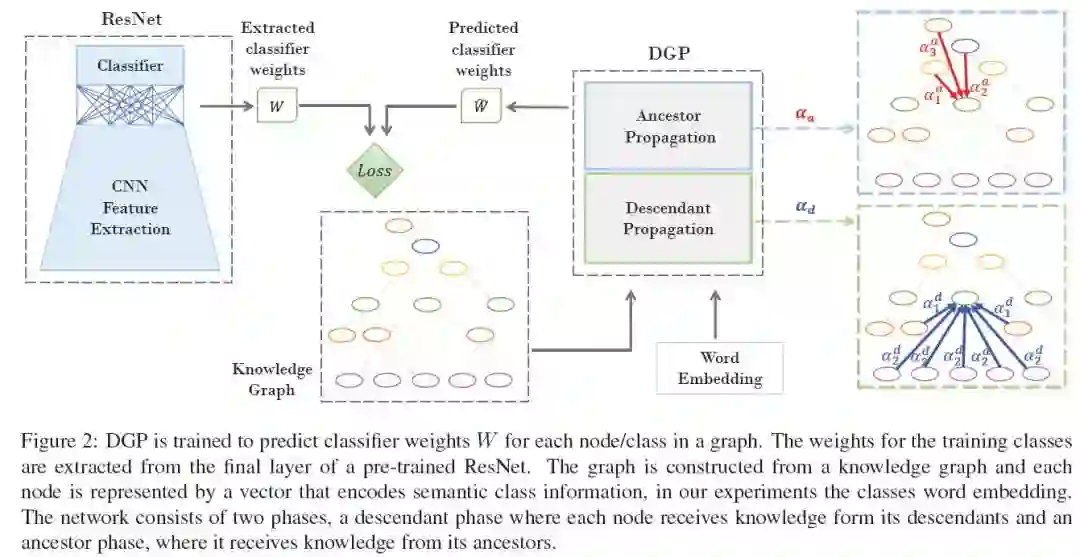
1、Rethinking Knowledge Graph Propagation for Zero-Shot Learning(零样本学习中知识图传播的再思考)
作者:Michael Kampffmeyer, Yinbo Chen, Xiaodan Liang, Hao Wang, Yujia Zhang, Eric P. Xing
摘要:最近,图卷积神经网络在零样本学习任务中显示出了巨大的潜力。这些模型具有高度的采样效率,因为图结构中的相关概念共享statistical strength,允许在缺少数据时对新类进行泛化。然而,由于多层架构需要将知识传播到图中较远的节点,因此在每一层都进行了广泛的拉普拉斯平滑来稀释知识,从而降低了性能。为了仍然享受图结构带来的好处,同时防止远距离节点的知识被稀释,我们提出了一种密集图传播(DGP)模块,该模块在远端节点之间精心设计了直接链接。DGP允许我们通过附加连接利用知识图的层次图结构。这些连接是根据节点与其祖先和后代的关系添加的。为了提高图中信息的传播速度,进一步采用加权方案,根据到节点的距离对它们的贡献进行加权。结合两阶段训练方法中的表示的微调,我们的方法优于目前最先进的零样本学习方法。
网址: http://www.zhuanzhi.ai/paper/dd4945166583a26685faaad5322162f0
代码链接: https://github.com/cyvius96/adgpm
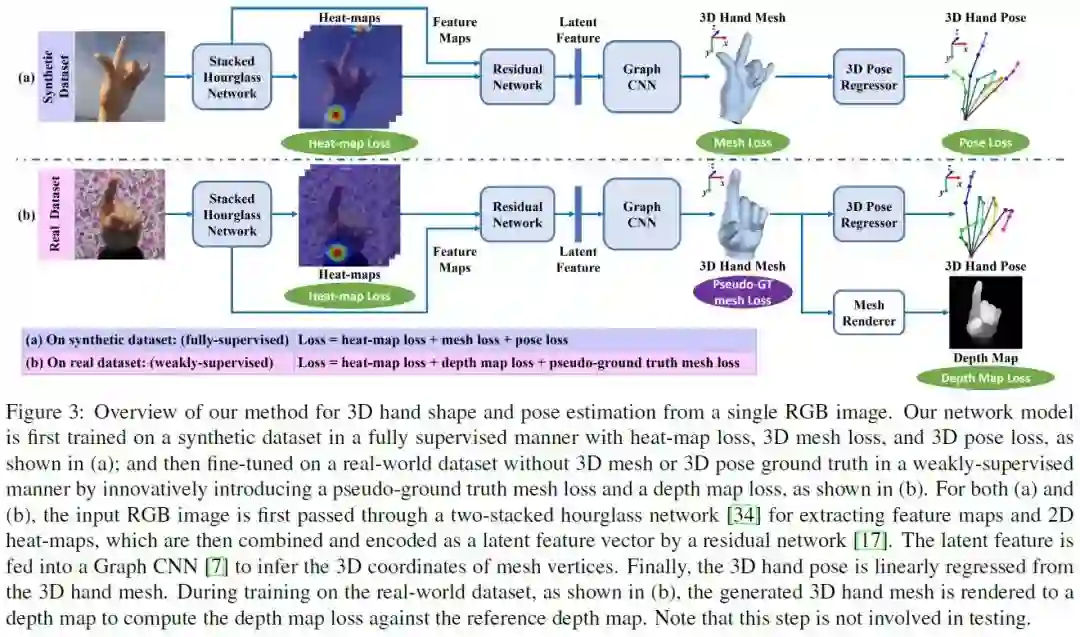
2、3D Hand Shape and Pose Estimation from a Single RGB Image(单一RGB图像的3D手形和姿态估计)
CVPR 2019 Oral
作者:Liuhao Ge, Zhou Ren, Yuncheng Li, Zehao Xue, Yingying Wang, Jianfei Cai, Junsong Yuan
摘要:这项工作解决了一个新颖且具有挑战性的问题,从单一RGB图像估计完整3D手形和姿势。目前对单目RGB图像进行三维手部分析的方法大多只注重对手部关键点的三维位置进行估计,无法完全表达手部的三维形态。相比之下,我们提出了一种基于图卷积神经网络(Graph CNN)的方法来重建一个完整的手部三维网格,其中包含了更丰富的手部三维形状和姿态信息。为了训练具有完全监督的网络,我们创建了一个包含ground truth三维网格和三维姿态的大规模合成数据集。当在真实世界数据集上微调网络时(没有三维ground truth),我们提出了一种利用深度图作为训练弱监督的方法。通过对所提出的新数据集和两个公共数据集的广泛评估,表明我们所提出的方法能够生成准确合理的三维手部网格,与现有方法相比,能够获得更高的三维手部姿态估计精度。
网址: http://www.zhuanzhi.ai/paper/d167eade544143625933886e5cb34cf6
代码链接: https://github.com/geliuhao/3DHandShapePosefromRGB
3、Linkage Based Face Clustering via Graph Convolution Network(通过图卷积网络实现基于链接的人脸聚类)
作者:Zhongdao Wang,Liang Zheng,Yali Li,Shengjin Wang
摘要:本文提出了一种精确、可扩展的人脸聚类方法。我们的目标是根据一组人脸的潜在身份对它们进行分组。我们将这个任务描述为一个链接预测问题:如果两个面孔具有相同的身份,那么它们之间就存在一个链接。关键思想是,我们在实例(face)周围的特征空间中找到本地上下文,其中包含关于该实例及其邻居之间链接关系的丰富信息。通过将每个实例周围的子图构造为描述局部上下文的输入数据,利用图卷积网络(GCN)进行推理,并推断出子图中对之间链接的可能性。实验表明,与传统方法相比,我们的方法对复杂的人脸分布具有更强的鲁棒性,在标准人脸聚类基准测试上与最先进的方法具有良好的可比性,并且可扩展到大型数据集。此外,我们证明了该方法不像以前那样需要事先知道簇的数量,能够识别噪声和异常值,并且可以扩展到多视图版本,以获得更精确的聚类精度。

网址: http://www.zhuanzhi.ai/paper/e7ace43c7aafec56171283988e34aa8b
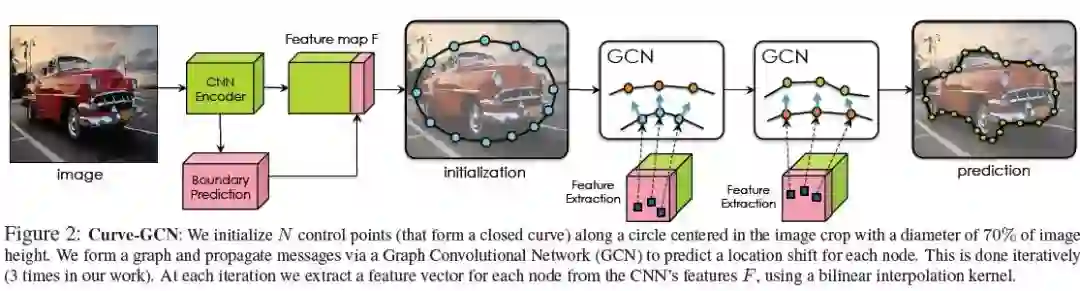
4、Fast Interactive Object Annotation with Curve-GCN(使用Curve-GCN进行快速交互式目标标注)
作者:Huan Ling, Jun Gao, Amlan Kar, Wenzheng Chen, Sanja Fidler
摘要:通过跟踪边界来手动标记对象是一个繁重的过程。 在Polygon-RNN ++中,作者提出了Polygon-RNN,它使用CNN-RNN体系结构以一种循环的方式生成多边形注释,允许通过人在环中进行交互式校正。我们提出了一个新的框架,通过使用图卷积网络(GCN)同时预测所有顶点,减轻了Polygon-RNN的时序性。我们的模型是端到端训练的。 它支持多边形或样条线的对象标注,从而提高了基于线和曲线对象的标注效率。 结果表明,在自动模式下,curv- gcn的性能优于现有的所有方法,包括功能强大的PSP-DeepLab,并且在交互模式下,curv - gcn的效率明显高于Polygon-RNN++。我们的模型在自动模式下运行29.3ms,在交互模式下运行2.6ms,比polyicon - rnn ++分别快10倍和100倍。
网址: http://www.zhuanzhi.ai/paper/c1839ee852a4b9b402da2547508980d3
代码链接: https://github.com/fidler-lab/curve-gcn
5、Graph Convolutional Label Noise Cleaner: Train a Plug-and-play Action Classifier for Anomaly Detection(图卷积标签噪声清除器: 训练用于异常检测的Plug-and-play行为分类器)
作者:Jia-Xing Zhong, Nannan Li, Weijie Kong, Shan Liu, Thomas H. Li, Ge Li
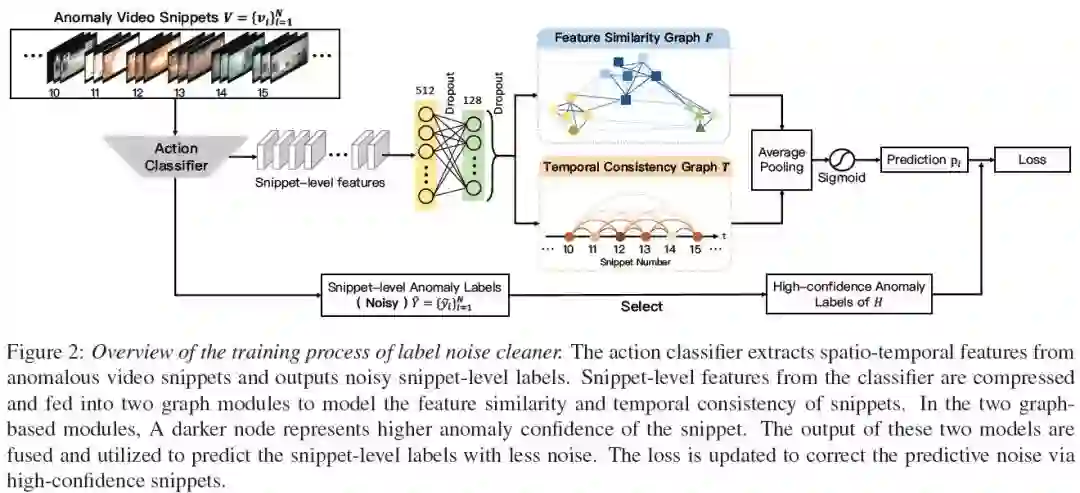
摘要:在以往的工作中,弱标签下的视频异常检测被描述为一个典型的多实例学习问题。在本文中,我们提供了一个新的视角,即在嘈杂标签下的监督学习任务。在这样的观点中,只要去除标签噪声,就可以直接将全监督的动作分类器应用到弱监督异常检测中,并最大限度地利用这些完善的分类器。为此,我们设计了一个图卷积网络来校正噪声标签。基于特征相似性和时间一致性,我们的网络将监控信号从高置信度的片段传播到低置信度的片段。以这种方式,网络能够为动作分类器提供清洁的监督。在测试阶段,我们只需要从动作分类器获得片段预测,而无需任何额外的后处理。使用2种类型的动作分类器对3个不同尺度的数据集进行了大量实验,证明了我们的方法的有效性。值得注意的是,我们在UCF-Crime上获得了82.12%的帧级AUC分数。
网址: http://www.zhuanzhi.ai/paper/12c28bd5fcdb4fa91e63b11055bdcc4d
代码链接: https://github.com/jx-zhong-for-academic-purpose/GCN-Anomaly-Detection
下载链接:https://pan.baidu.com/s/1bK1UMRspsNcx6FxrtzNr3A 提取码:34p8



