1、3D Point Cloud Generative Adversarial Network Based on Tree Structured Graph Convolutions
作者:Dong Wook Shu, Sung Woo Park, Junseok Kwon;
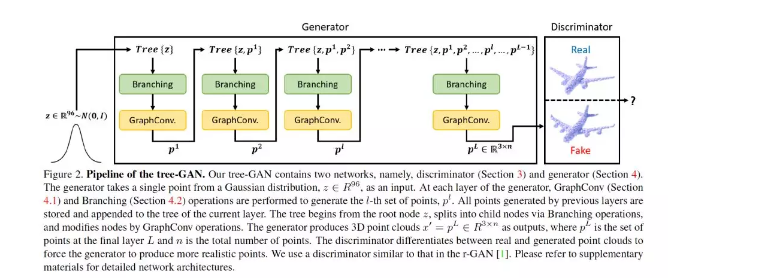
摘要:本文提出了一种新的三维点云生成对抗网络(GAN),称为tree-GAN。为了实现多类三维点云生成的最优性能,引入了一种树状图卷积网络(TreeGCN)作为tree-GAN的生成工具。因为TreeGCN在树中执行图卷积,所以它可以使用ancestor信息来增强特性的表示能力。为了准确评估三维点云的GAN,我们提出了一种新的评价指标,称为Fr'echet点云距离(FPD)。实验结果表明,所提出的tree-GAN在传统度量和FPD方面都优于最先进的GAN,并且可以在不需要先验知识的情况下为不同的语义部分生成点云。
网址:https://www.zhuanzhi.ai/paper/ade9cbf39f5984d62fb0569c60038853
2、Exploiting Spatial-temporal Relationships for 3D Pose Estimation via Graph Convolutional Networks
作者:Yujun Cai, Liuhao Ge, Jun Liu, Jianfei Cai, Tat-Jen Cham, Junsong Yuan, Nadia Magnenat Thalmann;
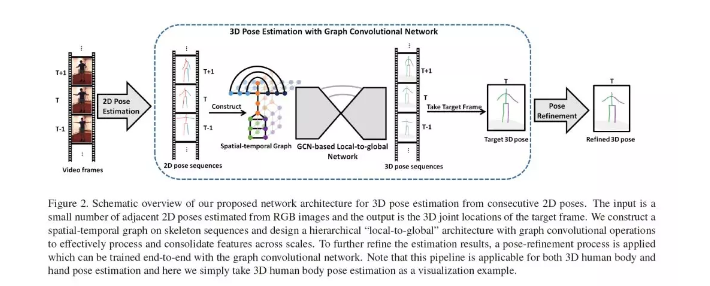
摘要:尽管单视图图像或视频的三维姿态估计取得了很大的进展,但由于深度模糊和严重的自聚焦,这仍然是一个具有挑战性的任务。为了有效地结合空间相关性和时间一致性来缓解这些问题,我们提出了一种新的基于图的方法来解决短序列二维关节检测的三维人体和三维手部姿态估计问题。特别是将人手(身体)构型的领域知识显式地融入到图卷积运算中,以满足三维姿态估计的特定需求。此外,我们还介绍了一个从局部到全局的网络架构,该架构能够学习基于图表示的多尺度特性。我们评估了所提出的方法在具有挑战性的基准数据集的三维手部姿态估计和三维身体位姿估计。实验结果表明,我们的方法在两种任务上都达到了最先进的性能。
3、Graph Convolutional Networks for Temporal Action Localization
作者:Runhao Zeng, Wenbing Huang, Mingkui Tan, Yu Rong, Peilin Zhao, Junzhou Huang, Chuang Gan;
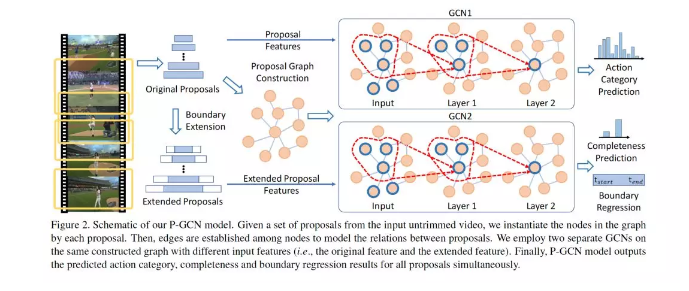
摘要:大多数最先进的行为定位系统都是单独处理每个动作proposal,而不是在学习过程中显式地利用它们之间的关系。然而,proposal之间的关系实际上在行动定位中扮演着重要的角色,因为一个有意义的行动总是由一个视频中的多个proposal组成。在本文中,我们提出利用图卷积网络(GCNs)来挖掘proposal - proposal关系。首先,我们构造一个action proposal图,其中每个proposal表示为一个节点,两个proposal之间的关系表示为一条边。这里,我们使用两种类型的关系,一种用于捕获每个proposal的上下文信息,另一种用于描述不同action之间的关联。我们在图上应用GCN,以对不同proposal之间的关系进行建模,学习了动作分类和定位的强大表示。实验结果表明,我们的方法在THUMOS14上显著优于最先进的方法(49.1% versus42.8%)。此外,ActivityNet上的增强实验也验证了action proposal关系建模的有效性。代码可以在https://github.com/alvinzeng/pgcn上找到。
网址:<https://www.zhuanzhi.ai/paper/a537a2f765073948121b7b4eee4a2070 >
4、Graph-Based Object Classification for Neuromorphic Vision Sensing
作者:Yin Bi, Aaron Chadha, Alhabib Abbas, Eirina Bourtsoulatze, Yiannis Andreopoulos;
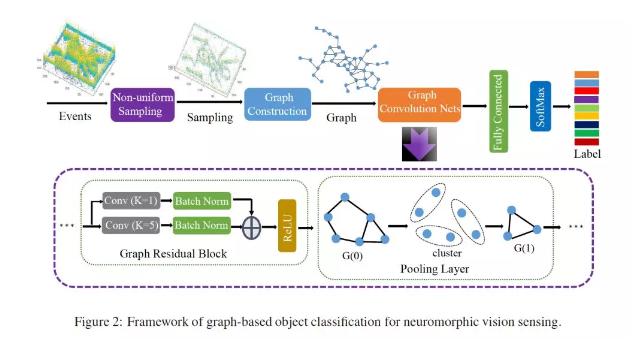
摘要:神经形态视觉传感(NVS)设备将视觉信息表示为异步离散事件的序列(也称为“spikes”),以响应场景反射率的变化。与传统的有源像素传感器(APS)不同,NVS允许更高的事件采样率,大大提高了能源效率和对光照变化的鲁棒性。然而,使用NVS流的对象分类不能利用最先进的卷积神经网络(CNNs),因为NVS不产生帧表示。为了避免感知和处理与CNNs之间的不匹配,我们提出了一种用于NVS的紧凑图表示方法。我们将其与新颖的残差图CNN体系结构相结合,结果表明,当对时空NVS数据进行训练用于对象分类时,这种残差图CNN保持了spike事件的时空一致性,同时所需的计算和内存更少。最后,为了解决缺乏用于复杂识别任务的大型真实世界NVS数据集的问题,我们提出并提供了一个100k的美国手语字母NVS记录数据集,该数据集是在真实世界条件下使用iniLabs DAVIS240c设备获得的。
网址:<https://www.zhuanzhi.ai/paper/51c73c6d562857328fac4166392bf720 >
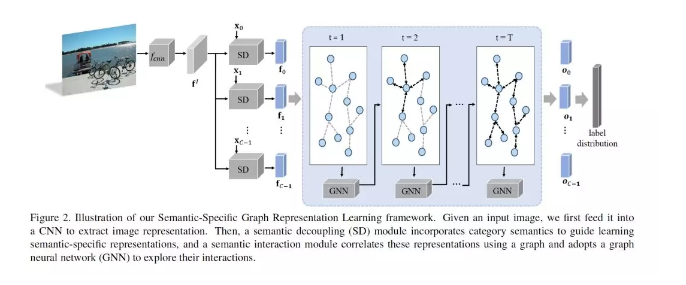
5、Learning Semantic-Specific Graph Representation for Multi-Label Image Recognition
作者:Tianshui Chen, Muxin Xu, Xiaolu Hui, Hefeng Wu, Liang Lin;
摘要:识别图像中的多个标签是一项现实而富有挑战性的任务,通过搜索语义感知区域和对标签依赖关系建模,已经取得了显著的进展。然而,由于缺乏局部层次的监督和语义指导,现有的方法无法准确定位语义区域。此外,它们不能充分挖掘语义区域之间的相互作用,也不能显式地对标签的共现进行建模。为了解决这些问题,我们提出了一个语义特定的图表示学习(SSGRL)框架,该框架由两个关键模块组成:1)一个语义解耦模块,该模块集成了范畴语义以指导学习语义特定的表示;2)一个语义交互模块。它将这些表示与建立在统计标签共现上的图相关联,并通过图传播机制探索它们的交互作用。在公共基准上的大量实验表明,我们的SSGRL框架在很大程度上优于当前最先进的方法,例如,在PASCAL VOC 2007 & 2012, Microsoft-COCO and Visual Genome benchmarks数据集上,mAP的性能分别提高了2.5%、2.6%、6.7%和3.1%。我们的代码和模型可以在https://github. com/HCPLab-SYSU/SSGRL上获得。
网址:<https://www.zhuanzhi.ai/paper/267160da377a31b8978cdde8775c359e >
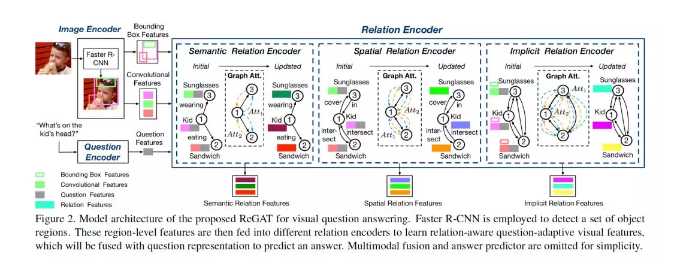
6、Relation-Aware Graph Attention Network for Visual Question Answering
作者:Linjie Li, Zhe Gan, Yu Cheng, Jingjing Liu;
摘要:为了解决图像的语义复杂问题,视觉问答模型需要充分理解图像中的视觉场景,特别是不同对象之间的交互动态。我们提出了一个关系感知图注意网络(ReGAT),它通过图注意机制将每个图像编码成一个图,并建立多类型的对象间关系模型,以学习问题的自适应关系表示。研究了两种类型的视觉对象关系:(1)表示几何位置的显式关系和对象之间的语义交互;(2)捕捉图像区域间隐藏动态的隐式关系。实验表明,ReGAT在VQA2.0和VQA2-CP v2数据集上的性能都优于现有的最新方法。我们进一步证明了ReGAT与现有的VQA体系结构兼容,可以作为一个通用的关系编码器来提高VQA的模型性能。
网址:<https://www.zhuanzhi.ai/paper/dadba65800545e02199beffbef4004bc >
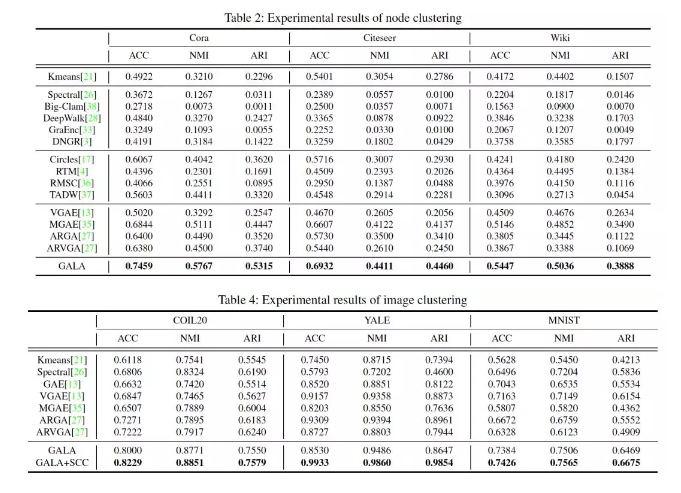
7、Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning
作者:Jiwoong Park, Minsik Lee, Hyung Jin Chang, Kyuewang Lee, Jin Young Choi;
摘要:我们提出了一种对称图卷积自编码器,它能从图中产生低维的潜在表示。与现有的具有非对称解码部分的图自编码器相比,本文提出的图自动编码器有一个新的解码器,它构建了一个完全对称的图自编码器形式。针对节点特征的重构,设计了一种基于拉普拉斯锐化的解码器,作为编码器拉普拉斯平滑的对应,使图结构在所提出的自编码体系结构的整个过程中得到充分利用。为了避免拉普拉斯锐化引入网络的数值不稳定性,我们进一步提出了一种新的结合符号图的拉普拉斯锐化的数值稳定形式。此外,为了提高图像聚类任务的性能,设计了一种新的成本函数,该函数能同时发现一个潜在的表示形式和一个潜在的affinity矩阵。在聚类、链路预测和可视化任务上的实验结果表明,我们所提出的模型是稳定的,并且性能优于各种最先进的算法。
网址:<https://www.zhuanzhi.ai/paper/52860855eb72bb6deb51e9be8cafa73d >
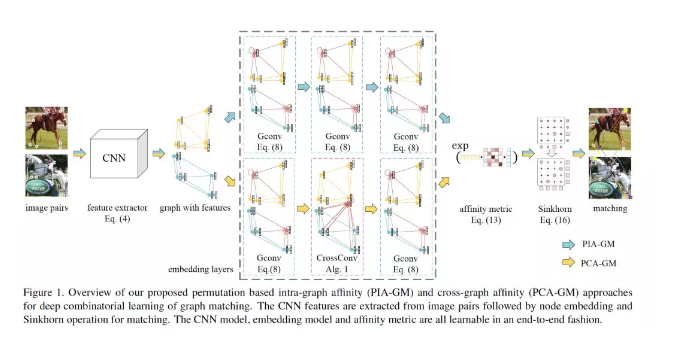
8、Learning Combinatorial Embedding Networks for Deep Graph Matching
作者:Runzhong Wang, Junchi Yan, Xiaokang Yang;
摘要:图匹配是指寻找图之间的节点对应关系,使对应的节点与边的亲和性(affinity)最大化。此外,由于NP完备性的性质之外,另一个重要的挑战是对图之间的节点和结构亲和性及其结果目标进行有效建模,以指导匹配过程有效地找到针对噪声的真实匹配。为此,本文设计了一个端到端可微的深度网络pipeline来学习图匹配的亲和性。它涉及与节点对应有关的有监督置换损失,以捕捉图匹配的组合性质。同时采用深度图嵌入模型来参数化图内和图间亲和性函数,而不是传统的如高斯核等浅层、简单的参数化形式。嵌入也能有效地捕获二阶边缘以外的高阶结构。置换损失模型与节点数量无关,嵌入模型在节点之间共享,这样网络就允许在图中使用不同数量的节点进行训练和推理。此外,我们的网络是类不可知的,具有跨不同类别的泛化能力。所有这些特性在实际应用中都受到欢迎。实验表明,该方法优于目前最先进的图匹配学习方法。
网址:<https://www.zhuanzhi.ai/paper/527a4ecad51e741f25b5dbc42e97b3e8 >