【论文导读】2021年论文导读第二十一期,7篇「视觉语言表示、图嵌入」TIP等论文


论文导读
2021年论文导读第二十一期(总第三十七期)
目 录
|
1 |
Adaptive Spatio-Temporal Graph Enhanced Vision-Language Representation |
|
2 |
SPADE-E2VID: Spatially-Adaptive Denormalization for Event-Based Video Reconstruction |
|
3 |
Flexible Multi-View Unsupervised Graph Embedding |
|
4 |
Efficient Center Voting for Object Detection and 6D Pose Estimation in 3D Point Cloud |
|
5 |
Enhancing ISAR Image Efficiently via Convolutional Reweighted l1 Minimization |
|
6 |
Adaptive Linear Span Network for Object Skeleton Detection |
|
7 |
Modeling Sub-Actions for Weakly Supervised Temporal Action Localization |
01
Adaptive Spatio-Temporal Graph Enhanced Vision-Language Representation
作者:金韦克1,赵洲1,操晓春2,朱杰明3,何秀强3,庄越挺1
单位:1浙江大学,2中国科学院信息工程研究所, 3华为诺亚方舟实验室
邮箱:
weikejin@zju.edu.cn;
zhaozhou@zju.edu.cn;
caoxiaochun@iie.ac.cn;
jamie.zhu@huawei.com;
hexiuqiang1@huawei.com;
yzhuang@zju.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9424429
由于自然语言处理和计算机视觉技术的快速发展,联合视觉-语言研究已经变得非常流行,其重点在于理解视觉内容、语言语义以及它们之间的关联关系。视频问答(Video QA)就是这样一个典型的视觉-语言任务,它旨在学习一个模型可以根据视频内容推断给定问题的正确答案。它比基于图像的问答更具挑战性,因为视频的额外时间结构带来了复杂的动态视觉信息。最年来,BERT和 GPT 等语言预训练模型在自然语言表示学习方面取得了巨大成功。受其启发,研究人员将这些模型扩展到视觉和语言等跨模式表示,提出了几种视觉语言预训练方法,如ViLBERT、LXMERT、videoBERT等。但是,也存在一些问题。首先,这些方法的输入特征大多是全局的和粗粒度的。由于视频的内容更加动态和丰富,更结构化的细粒度视频表示可能会更有帮助,例如一些图像-语言预训练模型会将静态对象区域作为细粒度信息输入,因此我们可以通过考虑每个对象的时间动态和时空关系来为视频加入对象级表示。另外,这些方法使用的视频数据中的文本信息(通常由ASR或自动翻译生成)包含大量噪声,导致文本描述与视频内容的匹配度不高,影响训练效率。因此,预训练过程通常需要海量的数据和计算资源。
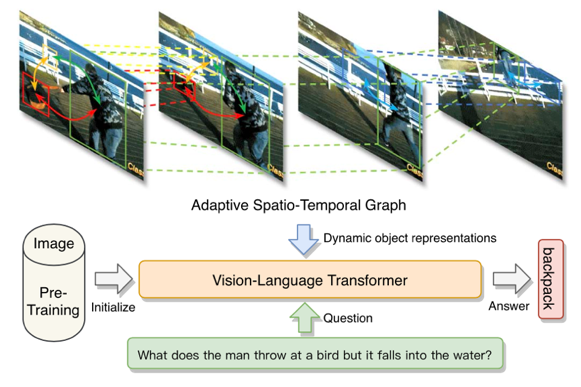
图1 模型流程示意图
在这项工作中,我们尝试利用Vision-Language Transformer架构来解决视频问答任务。然而,考虑到计算资源和时间成本的限制,我们没有像以前的工作那样使用视频数据对其进行预训练。相反,我们站在一个新的角度试图通过共享一个通用的模块设计,利用图像-语言预训练来帮助视频-语言建模。新的方法继承了现有高质量图像-语言数据和预训练模型的优点,提供了丰富的静态视觉语言交互信息。此外,我们引入了一个自适应时空图模块来增强视觉-语言的表示学习,它可以根据显著对象的时空关系自适应地修改对象的时空链接表征。如图 1 所示,示例是关于“一个人向一只鸟扔背包”。人、背包和鸟之间的相对时空关系有助于捕捉每个物体的详细时空动态。通过利用分层图卷积网络和时序GRU,我们最终可以获得许多细粒度的动态视频对象表示,作为视觉-语言Transformer模块的视觉输入信息。图2展示了更多模型细节。
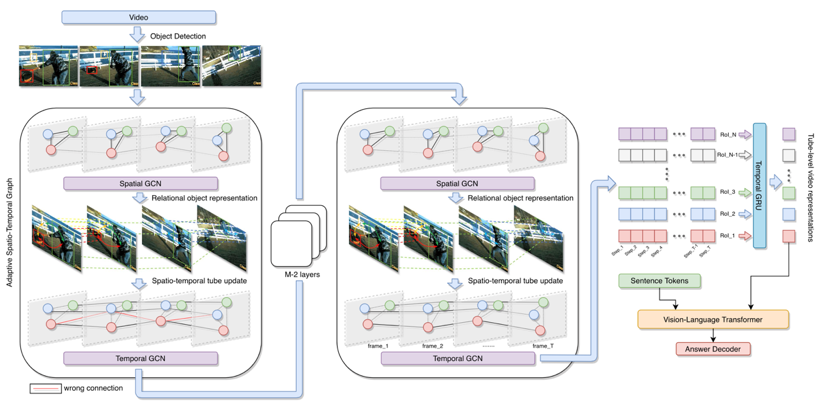
图 2 模型细节结构
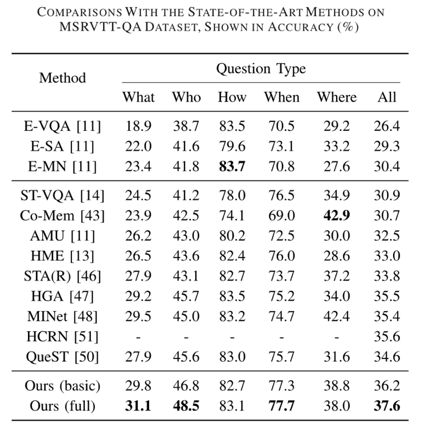
在三个广泛使用的视频问答数据集(MSRVTT-QA、MSVD-QA和TGIF-QA)上的实验结果表明,我们的模型相较于其他方法均获得了一定提升,下图展示了部分结果,完整结果可参考原文。

02
SPADE-E2VID: Spatially-Adaptive Denormalization for Event-Based Video Reconstruction
作者: Pablo Rodrigo Gantier Cadena1; 钱烨强2;王春香1; 杨明1
单位:1上海交通大学自动化系;2上海交通大学密西根学院
邮箱:
rodrigo.gantier.c@gmail.com;
qianyeqiang@sjtu.edu.cn;
wangcx@sjtu.edu.cn;
mingyang@sjtu.edu.cn
论文:
https://www.researchgate.net/publication/348821777_SPADE-E2VID_Spatially-Adaptive_Denormalization_for_Event-based_Video_Reconstruction
代码:
https://github.com/RodrigoGantier/SPADE_E2VID
训练数据:
http://rpg.ifi.uzh.ch/data/E2VID/datasets/ecoco_depthmaps_test.zip
演示视频:
https://www.youtube.com/watch?v=Dk1L0LeF7jQ&t
https://www.bilibili.com/video/BV13q4y1L7GR?share_source=copy_web
SPADE-E2VID的工作主要是事件相机的图像重建。事件相机是一种新型传感器,它的每一个像素都充当一个单独的传感器,每当感知到的亮度发生变化时就会发出信息。由于以上特性,事件相机具有高动态范围(HDR)的优势,普通相机的动态范围为60dB,而事件相机则为120dB,如图1所示,事件相机没有运动模糊同时具有非常高的刷新率。

图 1 图(a)是普通相机(华为P20 pro)拍摄的图像,图(b)是事件相机重建的图像(可以通过HDR观察到细节)
虽然事件相机具有HDR、无运动模糊,几乎连续的高刷新率等优势,但是它也有自己的劣势。由于其每个像素仅捕获光的变化,因此所生成的图像仅包含边缘,类似图像的导数,与应用在(x, y)轴上的Sobel滤波器生成的图像很相似,如图2所示。

图 2 图(a)是重建图像,图(b)是事件相机生成的图像,图 (c) 是Sobel滤波器生成的图像
理论上,由于这个特性,可以对事件相机生成的图像进行数学积分来恢复所有像素的值。但实际上,事件相机存在很多内部噪声。不过近年来由于神经网络的使用,这个问题得到了解决。开展基于事件的高质量视频重建的第一个工作是E2VID。SPADE-E2VID基于E2VID,并做出了一些有趣的改进。我们在第一帧中进行了更好的重建,如图3所示,并减少了训练时间,增加了对比度和时间一致性;并且使用非极性事件进行图像重建。

图3 SPADE-E2VID和E2VID的前5帧的结果比较
具体来说,SPADE-E2VID是一个RNN采用之前生产的图像 并将像素转换(调制)为照片般逼真的图像。如图4所示,Batch Normalization以一种特殊的方式使用,调节γ和 β 参数根据先前的图像调制(denormalizing)新的重建图像。此外,SPADE-E2VID 使用many-to-one训练模式,将训练时间减少了 40%。类似于风格转移的概念,利用之前网络生产的图像风格 Ik-1用于生成当前图像Ik ,这个过程提高了时间一致性;同样,也增加了图像对比度,可通过图5中的直方图来展示此效果,也可在演示视频查看。
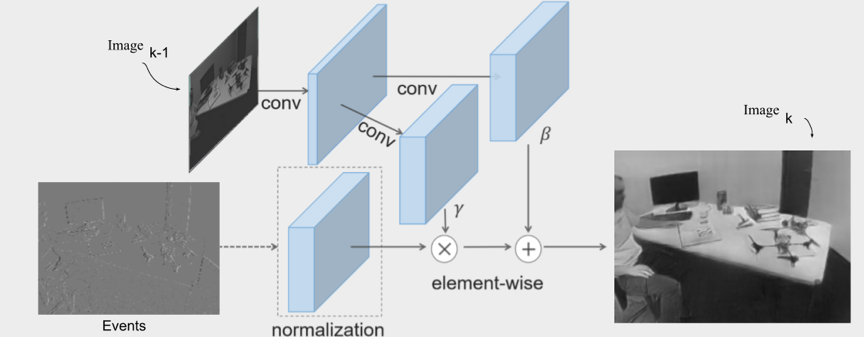
图4 空间归一化的SPADE层,利用图像k-1的像素调制图像k的像素的生成
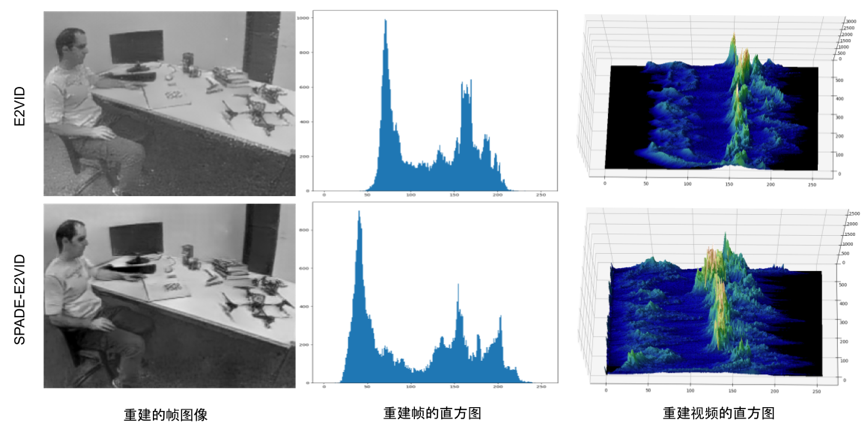
图5 SPADE-E2VID和E2VID的直方图比较
有几种类型的事件相机,一些事件相机具有更高的分辨率(CeleX5为1M像素),但不能产生极性数据。SPADE-E2VID 的另一个贡献是使用非极性事件进行图像重建。不过由于它生成的事件没有极性,因此在没有光信号方向的情况下执行图像重建按照数学理论是不可以的。但是我们的方法可以执行图像重建,然后在这些图像重建上执行对象检测和分类任务,如图6所示。

图6 使用CeleX5 事件相机的非极性事件的图像重建。基于YOLOv4目标检测算法,引人注目的是所有的狗都被识别为猫。
03
Flexible Multi-View Unsupervised Graph Embedding
作者:张斌1,强倩瑶1,王飞2,聂飞平3
单位:1西安交通大学软件学院,2西安交通大学电信学院,3西北工业大学光学影像分析与学习中心
邮箱:
bzhang.xjtu@gmail.com;
qiangqianyao@stu.xjtu.edu.cn;
wfx@mail.xjtu.edu.cn;
feipingnie@gmail.com
论文:
https://ieeexplore.ieee.org/document/9371411
面对日益增长的数据多样性和特征维数,多视图降维已经成为计算机视觉、数据挖掘和多媒体应用中的一项重要技术。由于收集有标记的数据既困难又昂贵,因此无监督学习具有重要意义。通常,在多视图学习中探索不同特征空间的互补性或独立性至关重要。如何找到一个可以保持原始未标记高维多视图数据内在结构的低维子空间仍然具有挑战性。此外,真实数据集复杂多样,噪声和异常值总是出现在真实数据中。从高维空间到低维空间的非线性映射规则无法处理噪声和异常值;虽然线性映射规则解决了噪声和异常值的处理问题,但真实数据的复杂性又对此提出了质疑。
针对以上问题,本文提出了一个灵活的多视图无监督图嵌入(Flexible Multi-View Unsupervised Graph Embedding,FMUGE)模型。引入了一个灵活的回归残差项,以松弛严格的线性映射关系、更好地处理噪声和异常值,并且保证原始数据与低维表示相互协商;为了保证多视图之间的一致性,FMUGE自适应地加权不同视图的相似度图,并学习得到了一个最优的多视图共识相似度图,帮助高质量的图嵌入。

图1 FMUGE概述
图1总结了FMUGE的工作原理。给定多视图数据{Xv}v=1V,我们首先构造各视图的相似度图{Av}v=1V。在降维过程中,FMUGE自适应地分配权重{αv}v=1V以融合多个视图,并根据{Av}v=1V所编码的样本间相似性和学习到的低维嵌入Y共同优化得到一个多视图共识相似度图S。随后,基于S实施图嵌入,通过交替优化得到最优的低维嵌入Y。Y可代替原始高维数据用于实际应用。
本文在八个基准数据集上进行了降维性能验证、参数敏感度分析和收敛性分析实验。图2中的第一行分别为使用真实标签呈现的MSRC-v1数据集各视图特征的t-SNE可视化,第二行为使用结果标签呈现的FMUGE在MSRC-v1数据集上学习到的不同维度低维嵌入的t-SNE可视化。可以观察到原始数据的分布是混乱的,学习到的不同低维嵌入中不同类别样本分布紧凑、区分明显。图3为FMUGE和所有比较方法学习到的不同维度低维嵌入的聚类准确率。可以观察到,FMUGE可以在所有数据集的不同潜在低维子空间取得比较稳健的降维结果。图4为FMUGE关于均衡参数的敏感性分析结果。我们发现,FMUGE虽然在不同参数设置上结果略有不同,但整体均可以保持较高的性能。图5为FMUGE在不同数据集上的目标值收敛曲线。观察图5可以发现,FMUGE的目标值在每次迭代中单调递减,且通常在30次迭代内收敛。结果验证了本文模型可以快速收敛。
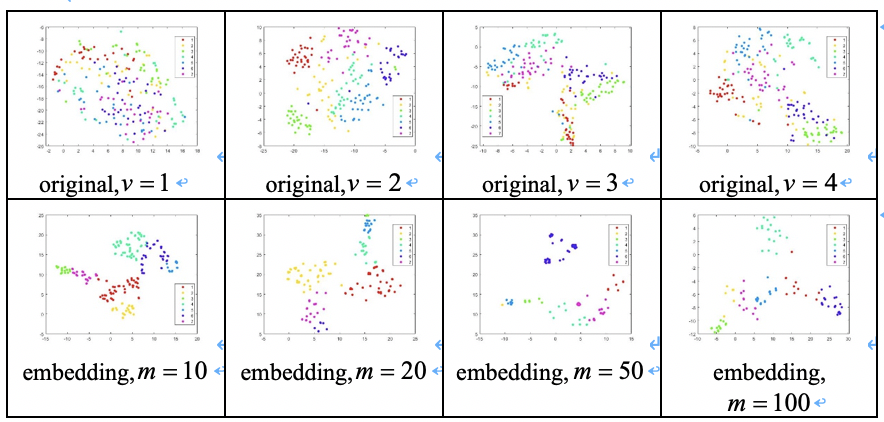
图2 MSRC-v1数据集各视图特征和FMUGE在MSRC-v1数据集上学习到的不同维度低维嵌入的t-SNE可视化。上面一行是原始数据的四个视图,下面一行分别是学习到的多视图嵌入。
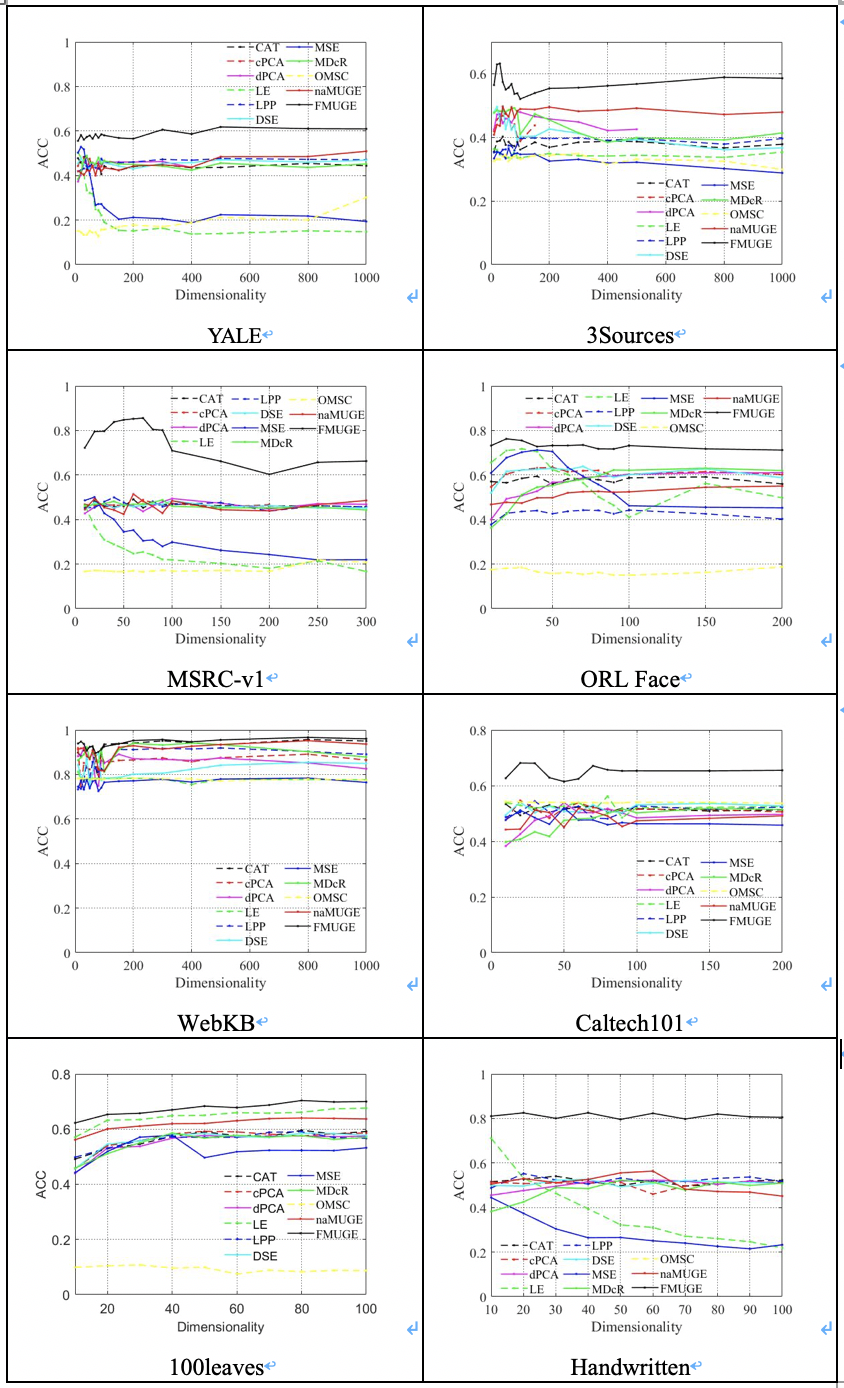
图3 FMUGE和所有比较方法在不同数据集上学习到的不同维度低维嵌入的聚类准确率。
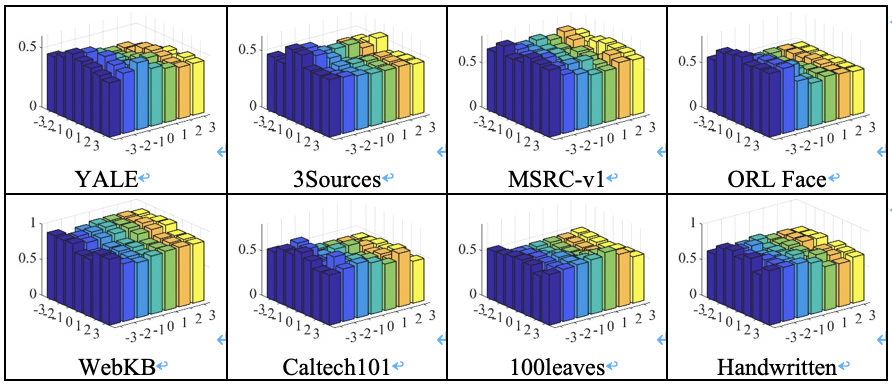
图4 均衡参数λ1和λ2取不同值时,FMUGE在不同数据集上学习到的低维嵌入的聚类准确率(x、y和z轴分别代表λ2、λ1和聚类准确率)。
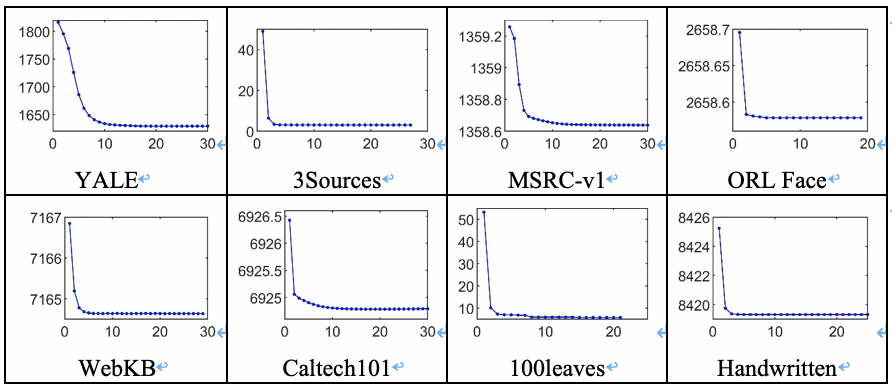
图5 FMUGE在不同数据集上的目标值收敛曲线(x、y轴分别代表迭代次数和目标值)。
04
Efficient Center Voting for Object Detection and 6D Pose Estimation in 3D Point Cloud
作者:郭建伟1,邢学军2,1,全卫泽1,严冬明1,顾庆毅1,刘扬3,张晓鹏1
单位:1中国科学院自动化研究所,2中国科学院大学,3苏州中科行智智能科技有限公司
邮箱:
jianwei.guo@nlpr.ia.ac.cn;
yandongming@gmail.com;
xiaopeng.zhang@ia.ac.cn
论文:
https://ieeexplore.ieee.org/document/9405457
代码:
https://ieeexplore.ieee.org/document/9429889
6D姿态估计在场景三维定位、机器人3D无序抓取、虚拟现实和增强现实等领域有广泛应用。早期工作主要集中在以特征描述子建立目标对象与场景实例之间的对应关系生成目标实例的位姿,但是这种方法的通用性和鲁棒性较差,难以满足对象表面特征分辨力低时的位姿估计需求。近期,涌现一些基于深度学习的位姿估计新方法,然而由于6D位姿估计训练数据标注难度大、硬件设备要求高和自监督深度学习算法预测精度低等原因限制了其在工业领域的应用。
针对以上问题,本文研究利用点对特征和模型中心之间的几何关系,提出基于中心点投票机制的6D位姿估计新方法,在3D工业点云场景中,其性能优于现有的方法。主要创新点包括:(1) 提出基于点对特征(PPF)的复杂点云场景物体检测及6D位姿估计方法,相比传统的点云场景位姿估计方法更加高效、鲁棒;(2) 为了更加准确地估计备选6D位姿,基于物体中心和点云点对特征之间的几何关系提出一种中心点投票策略;(3)提出一种新的备选位姿聚类和验证方法。
本文拟采样的技术方案主要分为目标对象离线建模、基于PPF中心投票估计备选位姿、备选位姿验证3个步骤。
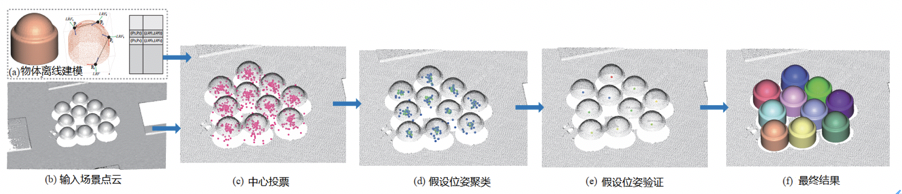
图1 技术路线图
(1)步骤一:物体离线建模。首先对输入目标对象点云进行下采样,生成一个稀疏采样点集。然后利用由稀疏采样点集组成的点对特征建立特征哈希表描述模型。具体来说,我们计算目标对象下采样点组成每组点对的PPF向量值,分别用距离离散尺度和角度离散尺度来离散PPF向量值的距离和角度元素,将离散特征向量将点对散列到哈希表中。
(2)步骤二:基于物体中心投票估计备选位姿。本文首先投票生成一组目标实例的中心点,然后对其中心点聚类分组,最后基于聚类分组生成相应的一个假设位姿。该方法主要基于模型PPF和场景中实例中心之间直观的几何关系,这种几何关系具有简单清晰的特点,既可以提高对噪音的鲁棒性也可在一定程度上减少计算的复杂性。此外,虽然一些目标实例位姿是不固定但其中心是恒定的,因此本文方法更能适合几何外形简单的工业器件的检测和6D位姿估计。
(3)步骤三:假设位姿验证。我们提出了基于模型包含盒顶点及其中心点组成三元组的聚类方法和基于重合度的假设位姿验证方法。基于三元组的聚类方法的量纲是唯一的,解决了由于变换矩阵需要利用角度量纲和距离量纲共同决定聚类结果,聚类过程复杂的问题。重合度验证策略解决了工业应用环境种绝大部分工业器件6D位姿评价问题。
实验结果:本文在UWA、Toshiba CAD和DTU等多个公开数据集上做了定量和定性对比试验,并取得了最优性能。
表1 DTU 数据集上的定量比较

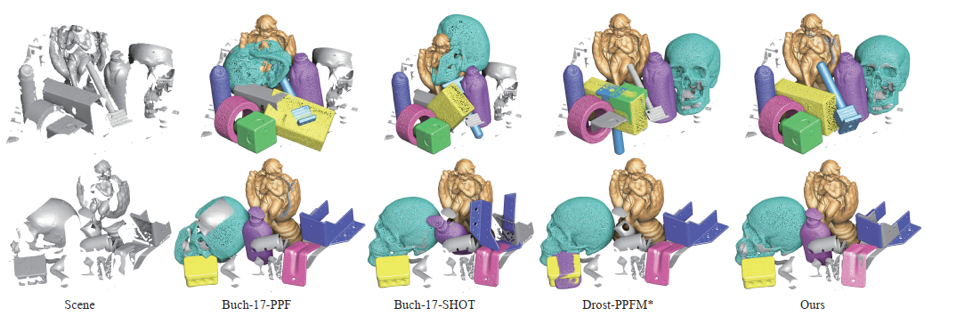
图2 DTU 数据集上的定性比较


图3 在实际点云数据上的物体检测结果
05
Enhancing ISAR Image Efficiently via Convolutional Reweighted l1Minimization
作者:张双辉、刘永祥、黎湘、胡德文
单位:国防科技大学
邮箱:
shzhang3@126.com;
lyx_bible@sina.com;
lixiang01@vip.sina.com;
dwhu@nudt.edu.cn
论文:
https://ieeexplore.ieee.org/document/9398563
逆合成孔径雷达(ISAR)成像技术可以获取运动目标高分辨雷达图像,与光学成像相比,具有全天时、全天候、强穿透等优势,已广泛应用于空间监视、导弹防御、岸基监视、雷达天文学等领域。在实际应用中,雷达回波可能不完整,如强噪声或干扰导致部分回波脉冲失效、多功能雷达发射功率受限导致回波脉冲稀疏、压缩感知雷达获取低于奈奎斯特采样率的欠采样雷达回波等,这些不完整的雷达回波统称为稀疏孔径回波。在稀疏孔径条件下,传统距离-多普勒(RD)ISAR成像方法所得图像受到较强旁瓣、栅瓣干扰,分辨率降低,无法满足工程实际需求。
稀疏孔径ISAR成像的数学本质是约束条件下的欠定逆问题求解,一般通过压缩感知技术实现。传统基于压缩感知的稀疏孔径ISAR成像方法一般仅利用目标散射点稀疏先验信息,而忽略各散射点之间的关联性,导致所得ISAR图像过于稀疏,图像视觉效果较差。已有方法考虑目标散射点之间关系,将目标结构化稀疏特性引入压缩感知框架,获取了视觉效果较好的ISAR图像。然而这些方法在迭代求解过程中均涉及大矩阵求逆计算,运算效率低,无法满足实时ISAR成像要求。研究基于目标结构化稀疏的稀疏孔径ISAR成像快速实现方法,可提升稀疏孔径条件下ISAR图像质量,同时满足ISAR成像系统的实时性要求,具有重要工程应用价值。
针对传统基于目标结构化稀疏先验的稀疏孔径ISAR成像方法运算效率低,提出了一种基于最小化卷积加权l1范数的稀疏孔径ISAR成像方法。传统基于最小化l1范数的稀疏孔径ISAR成像方法仅利用目标散射点稀疏特性,所得ISAR图像视觉效果难以满足工程实际需求。为充分利用各散射点之间的关联性,即目标结构化稀疏特性,所提方法将稀疏孔径ISAR成像建模为最小化卷积加权l1范数问题,在迭代过程中,分别将图像每一像素的四周像素的卷积作为下一次迭代中该像素的权值,所得ISAR图像质量优于传统基于最小化l1范数的稀疏孔径ISAR成像方法。进一步采用交替迭代乘子法(ADMM)求解该最小化卷积l1范数问题,以实现稀疏孔径ISAR成像快速运算。基于雷达实测数据的实验结果表明,本方法在ISAR成像过程中充分利用了目标结构化先验信息,可从目标稀疏孔径一维距离像中获取高质量ISAR图像,且运算效率高,有较高工程应用价值。
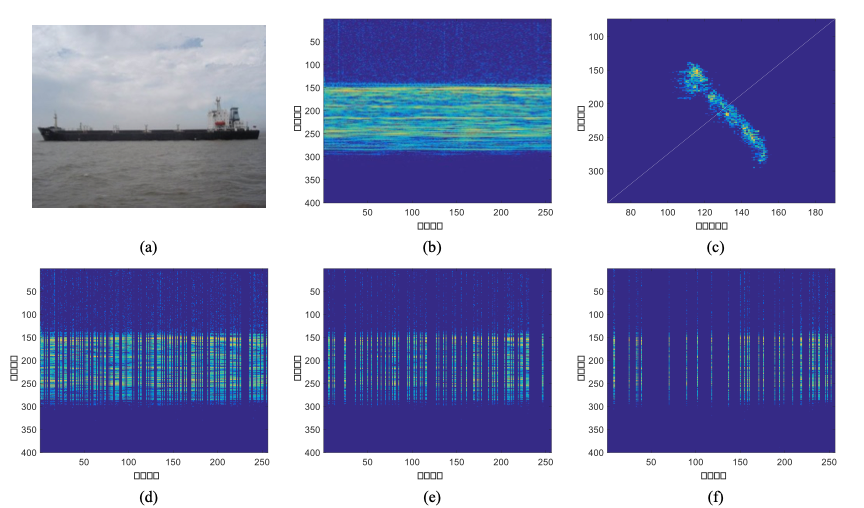
图1 雷达实测数据参照结果:(a)雷达目标;(b)全孔径一维距离像序列;(c)全孔径ISAR像;(d)-(f)稀疏度分别为50%、25%、12.5%的稀疏孔径一维距离像序列
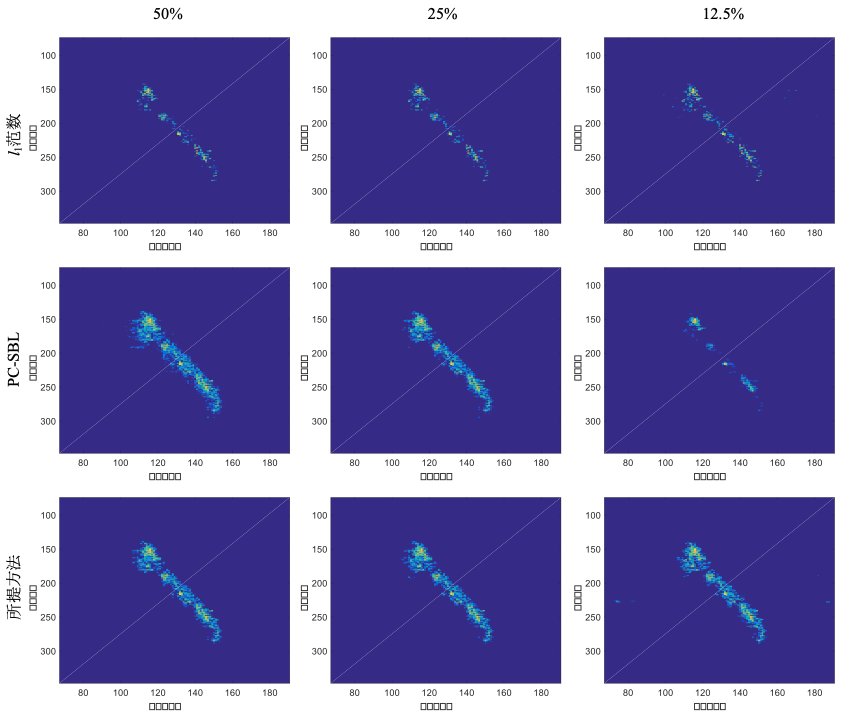
图2 稀疏孔径雷达实测数据ISAR成像结果
06
Adaptive Linear Span Network for Object Skeleton Detection
作者:刘畅,田运杰,焦建彬,叶齐祥
单位:中国科学院大学
邮箱:
liuchang615@mails.ucas.ac.cn;
tianyunjie19@mails.ucas.ac.cn;
jiaojb@ucas.ac.cn;
qxye@ucas.ac.cn
论文:
https://arxiv.org/pdf/2011.03972.pdf
代码:
https://github.com/sunsmarterjie/SDLSkeletongithub.com/sunsmarterjie/SDL-Skeleton
用于目标骨架检测的深度卷积神经网络通常是手工设计的,这些方法取得了一定的效果。但是由于缺乏理论指导,它们的设计严重依赖先验知识,制约了本领域的进一步发展。本文探索了骨架检测网络的理论建模和结构自动化搜索等问题。首先反思了骨架检测网络设计,将像素级二分类任务建模为线性重建问题,并得出结论:侧输出神经网络设计的关键是进行充分的特征空间扩展。基于此结论,我们提出了一种基于线性扩张理论的建模框架,为侧输出神经网络融合多尺度深度特征提供理论解释。
具体而言,我们提出了一个基于神经结构搜索技术的方法,称为自适应线性扩张网络(AdaLSN)。该方法为骨架检测任务配置和融合具有尺度感知特性的特征表示。自适应线性扩张网络方法的主体是一种混合了线性扩张单元和线性扩张金字塔的神经网络搜索空间。这种搜索空间的设计超越了许多仅使用单元级或特征金字塔级的搜索空间,见图1。在混合空间内,我们应用遗传结构搜索算法以联合优化单元级操作和用于自适应特征空间扩展的金字塔级连接,见图2。自适应线性扩张网络相比最先进方法能自动搜索到性能更优越的网络结构,见图3和表1。我们还将其应用在其他图像掩模生成任务上,生成结果均接近标注真值,验证了本方法的普遍适用性,见图4和图5。
一、问题回顾
卷积神经网络通常通过级联卷积层和下采样层等操作生成特征金字塔。在金字塔结构中,特征表示的语义层次、尺度粒度和分辨率变化交织在一起,给特征融合带来了以下挑战:
1) 如何用有限的卷积层应对视觉目标的外观、形状、姿势和比例的巨大变化,同时压制杂乱的背景?
2) 如何平衡由互补特征带来的好处和由在特征融合的分辨率对齐过程中上采样操作造成的特征退化?
3) 如何利用好不同层中蕴含丰富语义层次和尺度粒度的卷积特征?
4) 如何学习具有最大互补性的多层级尺度感知特征?
二、方法简介
我们定义了一个混合单元-金字塔搜索空间来进行子空间与和空间扩展。为了减少结构冗余,我们将线性扩张金字塔编码为基因片段以便进行遗传结构搜索。我们通过搜索优化去除了搜索空间中超网络的部分连接,从而减少了得到的子网络的特征子空间的交空间,增加了特征表示之间的互补性。
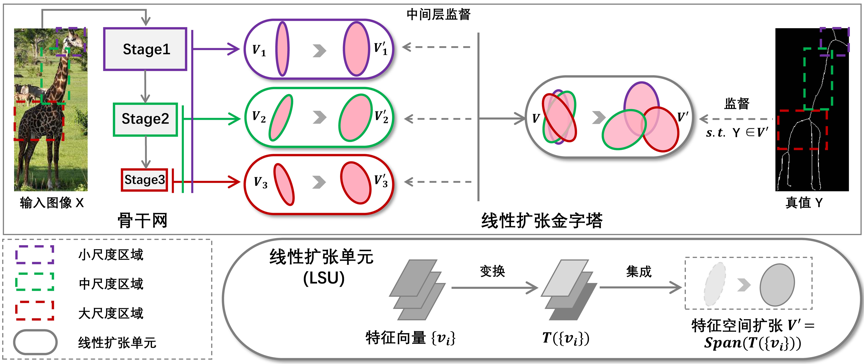
图 1 自适应线性扩张网络方法的结构搜索空间图示。
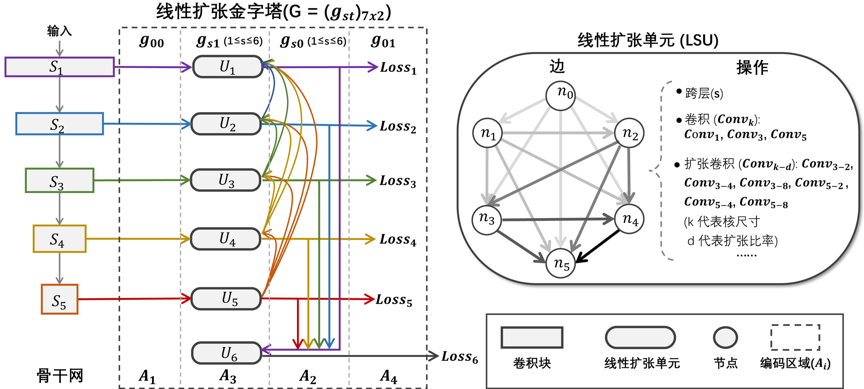
图2 线性扩张金字塔和线性扩张单元的结构示意图。
三、实验验证
我们将本方法应用于骨架检测和道路提取任务,均取得了显著的性能提升。
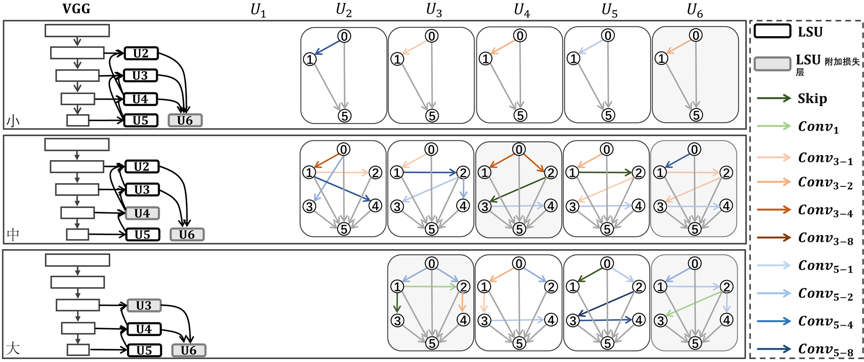
图3 搜索到的自适应线性扩张网络的结构示例。
表1 在常用骨架对称性检测数据集最新方法的性能比较。
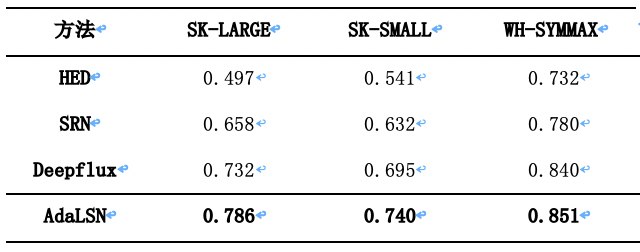

图4 在常用的骨架检测数据集上进行骨架检测的示例。

图5 道路提取结果示例。

07
Modeling Sub-Actions for Weakly Supervised Temporal Action Localization
作者:黄林江1,黄岩1,欧阳万里2,王亮1
单位:1中科院自动化所, 2悉尼大学
邮箱:
ljhuang524@gmail.com;
yhuang@nlpr.ia.ac.cn;
wanli.ouyang@sydney.edu.au;
wangliang@nlpr.ia.ac.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9430747
行为定位的目的是定位出未裁剪视频中行为发生的起止时间以及对应的行为类别。由于视频的标注耗时且十分昂贵,为了减少行为定位时所需要的标注成本,弱监督行为定位任务被提出并在近几年受到了广泛的关注。
通常来说,一个复杂的行为由一系列有序的子行为构成。如图1所示,由于子行为之间的差异性,弱监督行为定位方法在只采用整个视频的类别标签时,通常只能定位出行为内部某些显著的子行为,从而无法定位出完整的行为片段。基于这个问题,我们提出通过建模子行为的方式来建模整个行为片段。
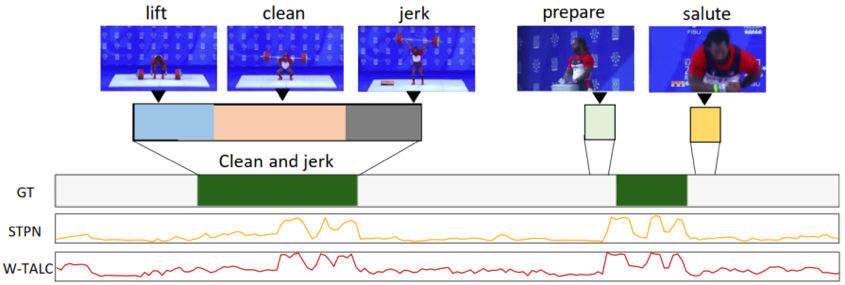
图1 由于子行为之间的差异,现有的方法通常只能定位出行为中具有显著信息的子行为
图2中展示了我们方法的网络框架。由于没有子行为标注,我们提出采用随机初始化的原型来代表子行为。我们通过原型网络将视频特征投影到子行为空间中,随后利用图卷积建模子行为之间的关系,通过图池化的方法建立子行为与真实行为类别之间的从属关系,从而将子行为空间中的预测结果转化为真实行为类别的预测结果。此外,我们提出了两种损失函数使学习到的子行为有区分性并具有一定的语义信息。

图2 子行为建模网络框架
我们的方法在两个常用的行为定位数据集上均取得了当时最好的结果。尤其在THUMOS14数据集上,在平均mAP评价指标上超过了最好的方法2.0%。
表1 THUMOS14数据集定位结果比较
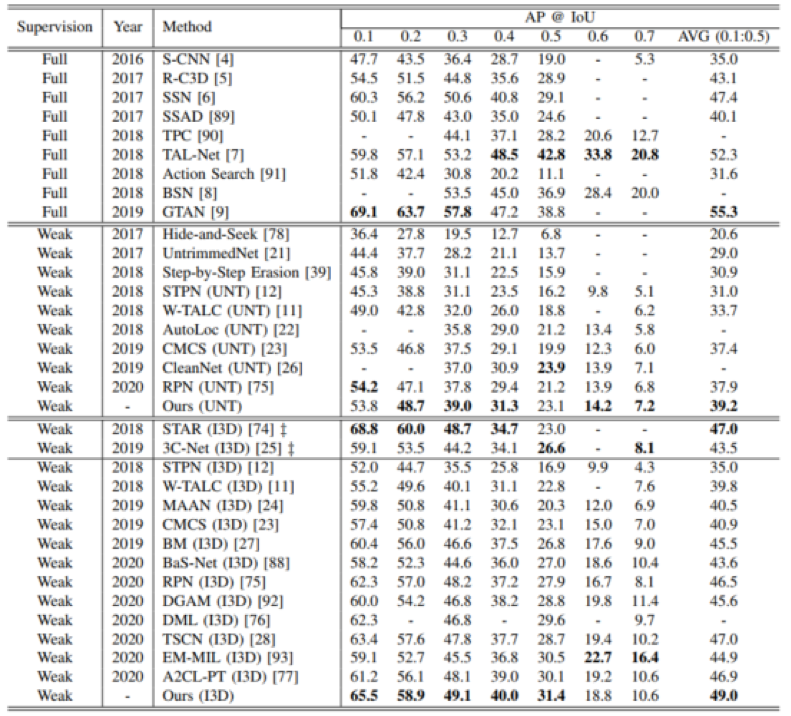
表2 ActivityNet1.3数据集定位结果比较
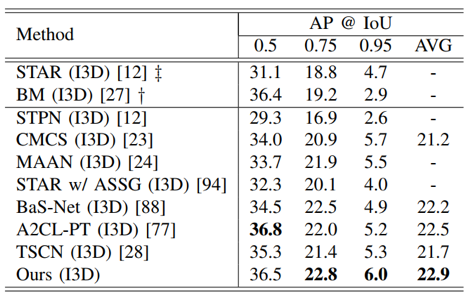
图3是定位结果的展示。绿色部分是真实标注,红色部分是我们的预测结果,可以看到我们方法的预测结果与真实值的误差很小。此外,蓝色的部分也展示出了该类别所对应的子行为的定位结果,可以看到学习到的子行为具有一定的语义信息,比如第一个例子的第二个子行为对应于挺举中的拉杠铃这一子行为。
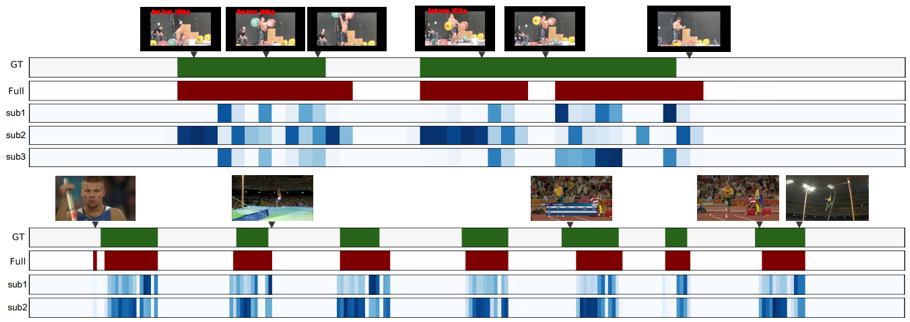
图3 定位结果展示

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“专知” 就可以获取《专知人工智能》专知下载链接






