【论文笔记】Graph U-Nets
【导读】卷积神经网络可以在图像(image)上随意操作,并且像U-Nets这种编码-解码框架已经成功地应用在许多图像像素级预测任务中,但是在图(graph)数据上具有很大的挑战。为了解决这些挑战,我们提出了一个新颖的图池化(gPool)和图上采样((gUnpool))操作。图池化层(gPool)根据节点在可训练投影向量上的标量投影值,自适应地选择一些节点形成较小的图。我们也提出了gUnpool层作为gPool的反操作,利用在相应的gPool层中选择的节点的位置信息,将图恢复到原来的结构中。并且基于我们提出的gPool层与gUnpool层,我们提出了一个在图上的编码-解码模型,称为图U-Nets。在节点分类以及图分类任务中取得比以前的模型更好的性能。

动机
Graph U-Nets
图池化层
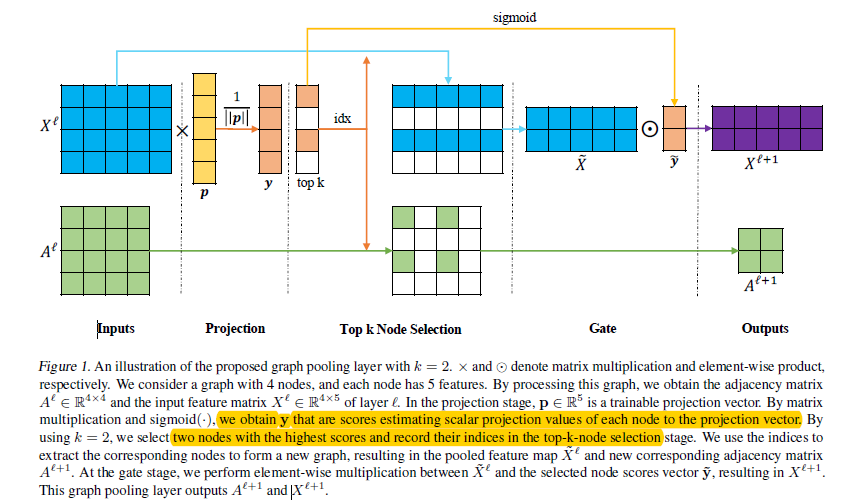
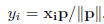
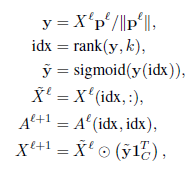
-
k是新图中被选择的节点数量 -
rank(y; k)是节点排名操作,返回y中排名靠前的k个值对应的索引 -
idx是在新图中被选择节点的索引 -
X^l_{idx,:}是在特征矩阵中通过idx逐行索引 -
A^l_{idx,idx}是在特征矩阵中通过idx逐行、逐列索引 -
y(idx)提取y中对应索引的值 -
1_C∈R^C是由1组成的大小为C的向量
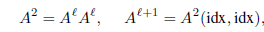
Graph Unpooling 层(上采样)
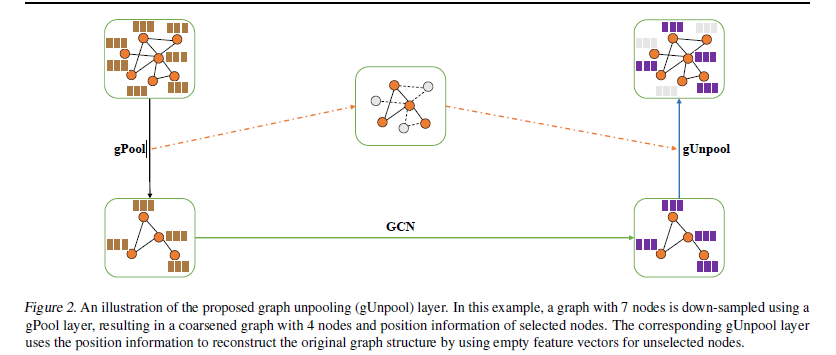
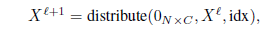
-
idx∈Z^{*k}包含相应gPool层(将图形大小从N个节点减少到k个节点)中选定节点的索引。 -
Xl∈R{N×C}是当前图的特征矩阵 -
0_{N×C}是新图的初始空特征矩阵
U-Nets框架
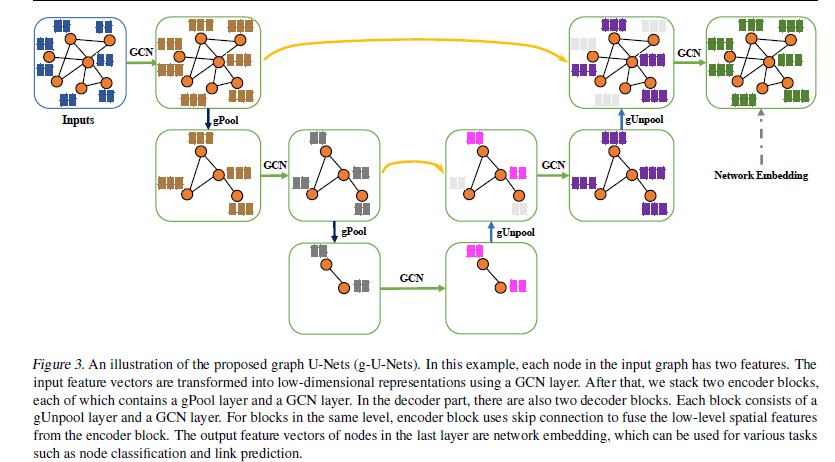
实验
-
将文中中提出的g-U-Nets与节点分类和图分类任务的最新模型进行比较。 -
进行了一些消融研究,以对比gPool层、gUnpool层和图形连接增强对性能改进的贡献。 -
对网络深度与节点分类性能之间的关系进行研究。
数据集
-
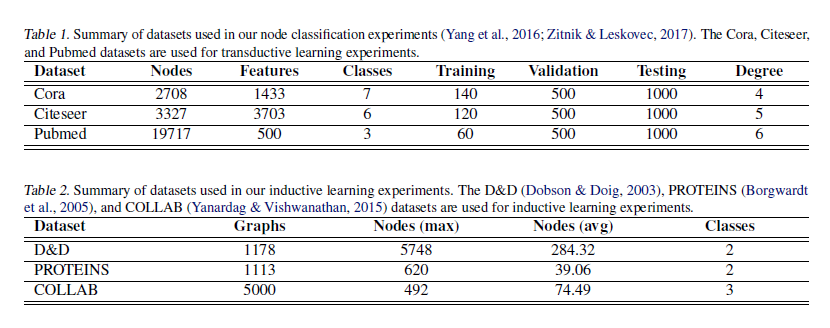
转导学习(transductive learning)设置下,选择Cora,Citeseer和Pubmed(Kipf&Welling,2017年),总结在表1中。 数据集是引文网络,每个节点和每个边分别代表文档和引文。 每个节点的特征向量是词袋表示,其大小由字典大小决定。 有20个用于训练的节点,500个用于验证的节点和1000个用于测试的节点。 -
在归纳学习设置(inductive learning ),使用蛋白质数据集D&D、PROTEINS,科学合作数据集COLLAB。 这些数据总结在表2中。
实验设置
-
GCN层将输入简化为低维表示 -
在编码器部分,堆叠四个块,每个块由一个gPool层和一个GCN层组成。 别在四个gPool层中采样2000、1000、500、200个节点。 -
解码器部分也包含四个块。 每个解码器块均由gUnpool层和GCN层组成 -
skip 连接: 使用加法运算。 -
dropout: 应用于邻接矩阵和特征矩阵,保持率分别为0.8和0.08。
实验结果
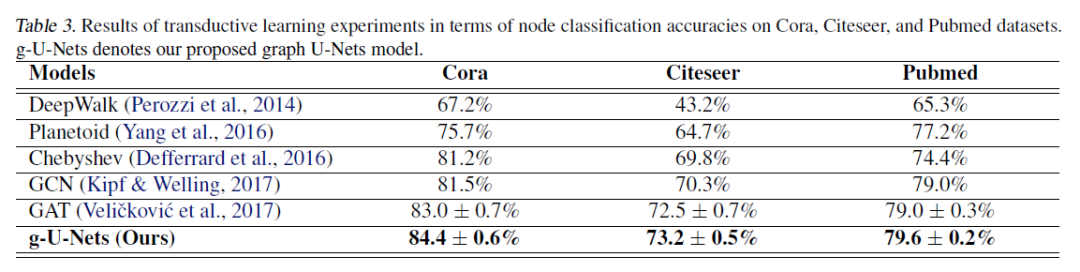
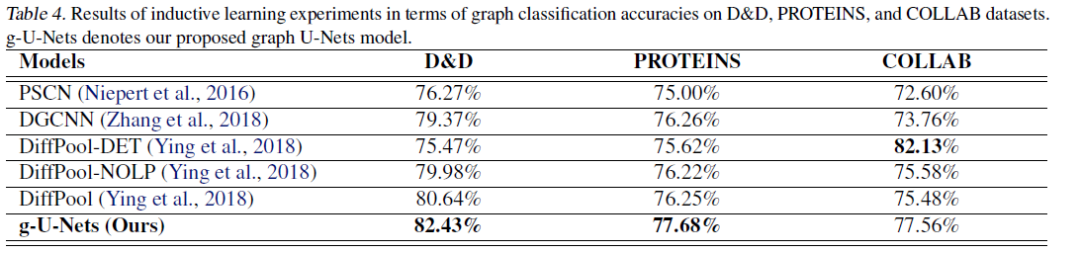


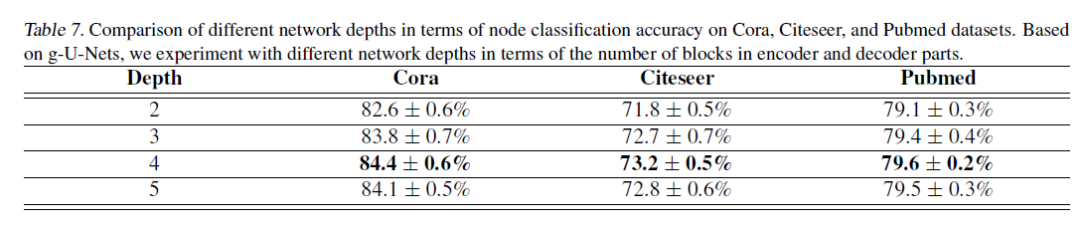



登录查看更多
相关内容
专知会员服务
99+阅读 · 2020年7月6日
专知会员服务
101+阅读 · 2020年6月28日
专知会员服务
108+阅读 · 2020年3月29日
专知会员服务
24+阅读 · 2019年11月20日
Arxiv
5+阅读 · 2018年11月1日




相关VIP内容
专知会员服务
99+阅读 · 2020年7月6日
专知会员服务
101+阅读 · 2020年6月28日
专知会员服务
108+阅读 · 2020年3月29日
专知会员服务
24+阅读 · 2019年11月20日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年11月1日