
【导读】最近小编推出CVPR2019图卷积网络相关论文、CVPR2019生成对抗网络相关视觉论文、【可解释性】相关论文和代码,CVPR视觉目标跟踪相关论文和代码,反响热烈。最近,视觉问答和推理这一领域也广泛受关注,出现了好多新方法、新数据集,CVPR 2019已经陆续放出很多篇篇相关文章。今天小编专门整理最新七篇视觉问答相关应用论文—多模态关系推理、视觉上下文、迁移学习、通用VQA模型、新数据集GQA等。

1、MUREL: Multimodal Relational Reasoning for Visual Question Answering (MUREL:视觉问答的多模态关系推理)
CVPR ’19
作者:Remi Cadene, Hedi Ben-younes, Matthieu Cord, Nicolas Thome
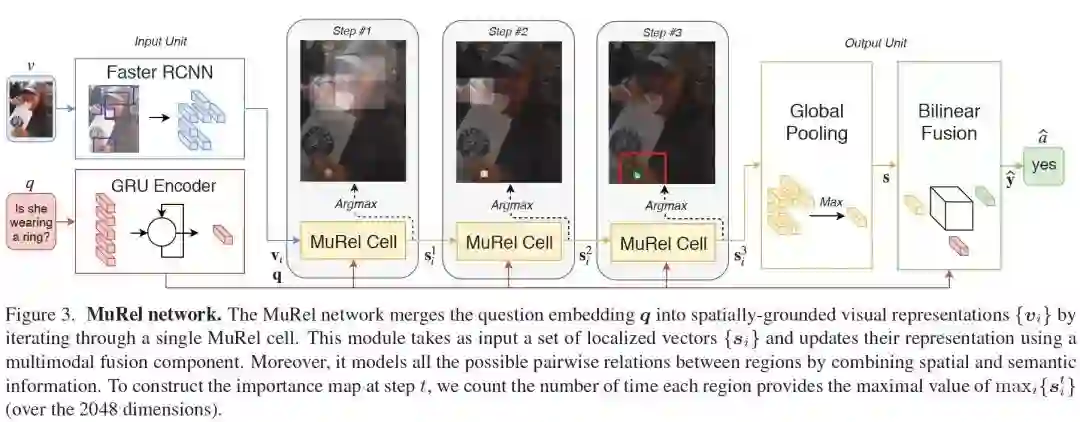
摘要:多模态注意力网络是目前用于涉及真实图像的视觉问答(VQA)任务的最先进的模型。尽管注意力集中在与问题相关的可视内容上,但这种简单的机制可能不足以模拟VQA或其他高级任务所需的复杂推理功能。在本文中,我们提出了MuRel,一种多模态关系网络,它通过真实图像进行端到端的学习。我们的第一个贡献是引入了MuRel单元,这是一个原子推理原语,通过丰富的向量表示来表示问题和图像区域之间的交互,并使用成对组合对区域关系建模。其次,我们将单元格合并到一个完整的MuRel网络中,该网络逐步细化了可视化和问题交互,并且可以用来定义比注意力更精细的可视化方案。我们验证了我们的方法与各种消融研究的相关性,并在三个数据集:VQA 2.0、VQA- cp v2和TDIUC上显示了它相对于基于注意力的方法的优势。我们的最终MuRel网络在这一具有挑战性的环境中具有竞争力或优于最先进的结果。
网址:
https://arxiv.org/abs/1902.09487
代码链接:
https://github.com/Cadene/murel.bootstrap.pytorch
2、Image-Question-Answer Synergistic Network for Visual Dialog( 基于图像-问题-答案协同网络的视觉对话)
CVPR ’19
作者:Dalu Guo, Chang Xu, Dacheng Tao
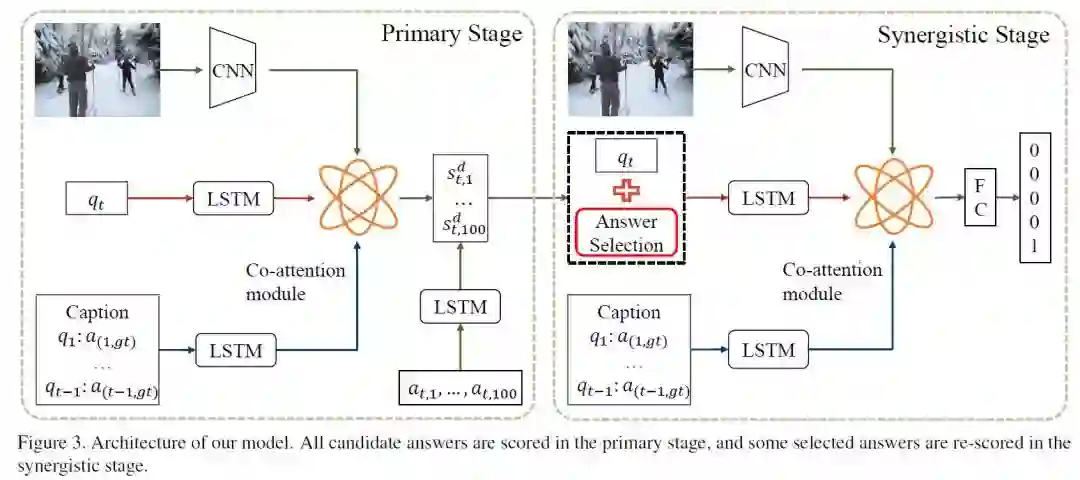
摘要:图像、问题(结合用于de-referencing的历史)和相应的答案是视觉对话的三个重要组成部分。经典的视觉对话系统集成了图像、问题和历史来搜索或生成最佳匹配的答案,因此,这种方法明显忽略了答案的作用。在本文中,我们设计了一个新颖的图像 - 问题 - 答案协同网络,以评估答案对精确视觉对话的作用。我们将传统的一阶段解决方案扩展为两阶段解决方案。在第一阶段,根据候选答案与图像和问题对的相关性对候选答案进行粗略评分。之后,在第二阶段,通过与图像和问题协同,对具有高正确概率的答案进行重新排序。在Visual Dialog v1.0数据集上,所提出的协同网络增强了判别性视觉对话模型,实现了57.88%的NDCG(normalized discounted cumulative gain)的最新的最优表现。
网址:
https://arxiv.org/abs/1902.09774
3、Learning to Compose Dynamic Tree Structures for Visual Contexts(学习为视觉上下文构建动态树结构)
CVPR ’19 Oral
作者:Kaihua Tang, Hanwang Zhang, Baoyuan Wu, Wenhan Luo, Wei Liu
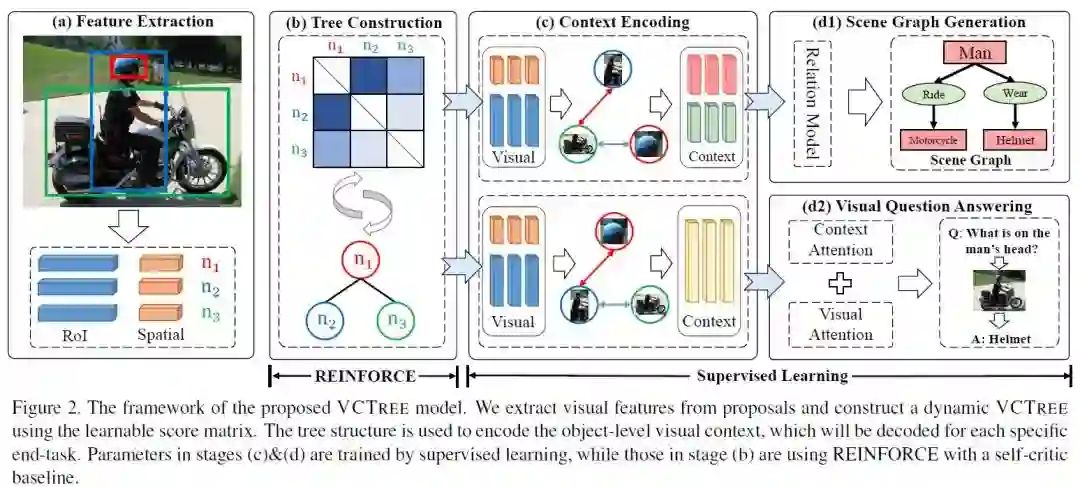
摘要:我们提出组合动态树结构,将图像中的对象放入视觉上下文中,帮助进行视觉推理任务,如场景图生成和视觉问答。我们的视觉上下文树模型(称为VCTree)与现有的结构化对象表示(包括链和全连接图)相比具有两个关键优势:1)高效且富有表现力的二叉树编码对象之间固有的并行/层次关系,例如“衣服”和“裤子”通常是共同出现的,属于“人”; 2)动态结构因图像和任务而异,允许在对象之间传递更多特定于任务的内容/消息。为了构造一个VCTree,我们设计了一个score函数来计算每个对象对之间的任务依赖效度,这个VCTree是score矩阵中最大生成树的二进制版本。然后,视觉上下文由双向TreeLSTM编码,并由特定于任务的模型解码。本文提出了一种混合学习方法,将末端任务监督学习与树形结构强化学习相结合,前者的评估结果作为后者结构探索的self-critic。两个benchmark测试的实验结果,需要对上下文进行推理:用于场景图生成的Visual Genome和用于视觉Q&A的VQA2.0,表明VCTree在发现可解释的视觉上下文结构时优于最先进的结果。
网址:
https://arxiv.https://arxiv.org/abs/1812.01880
4、Transfer Learning via Unsupervised Task Discovery for Visual Question Answering(通过无监督的任务发现迁移学习以进行视觉问答)
CVPR ’19
作者:Hyeonwoo Noh, Taehoon Kim, Jonghwan Mun, Bohyung Han
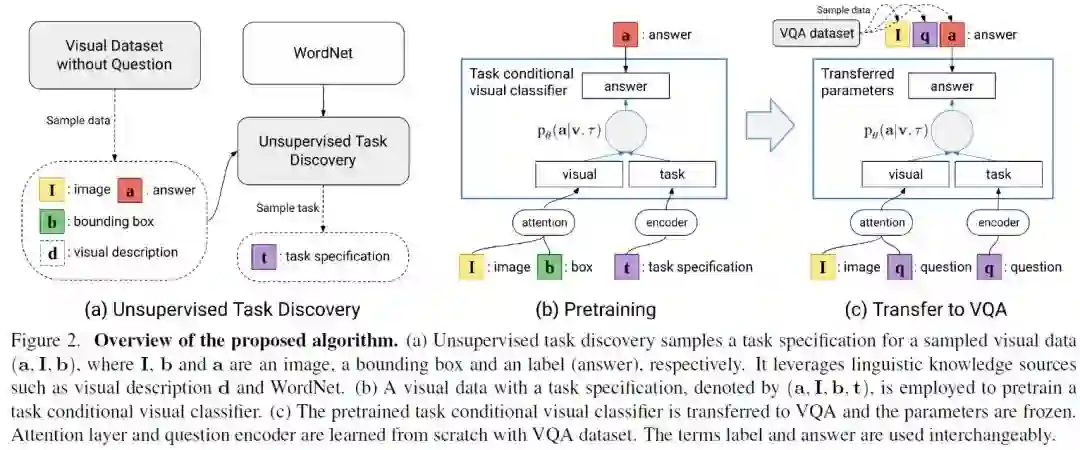
摘要:我们研究如何利用现成的视觉和语言数据来处理视觉问答任务中词汇量不足的问题。现有的带有图像类标签、边界框和区域描述等标注的大型可视化数据集是学习丰富多样的视觉概念的好资源。然而,由于依赖于问题的回答模型与无问题的视觉数据之间缺少联系,如何捕获视觉概念并将其转化为VQA模型并不简单。我们通过两个步骤来解决这个问题:1)学习一个任务条件视觉分类器,该分类器基于无监督任务发现,能够解决多种特定问题的视觉识别任务;2)将任务条件视觉分类器转化为视觉问答模型。具体来说,我们使用结构化词汇库(如WordNet)和视觉概念描述等语言知识资源来进行无监督任务发现,并将学习到的任务条件视觉分类器作为一个回答单元迁移到一个 VQA模型中。实验结果表明,该算法利用从视觉数据集中迁移的知识成功地推广到词汇表外的问题。
网址:
https://arxiv.org/abs/1810.02358
代码链接:
https://github.com/HyeonwooNoh/VQA-Transfer-ExternalData
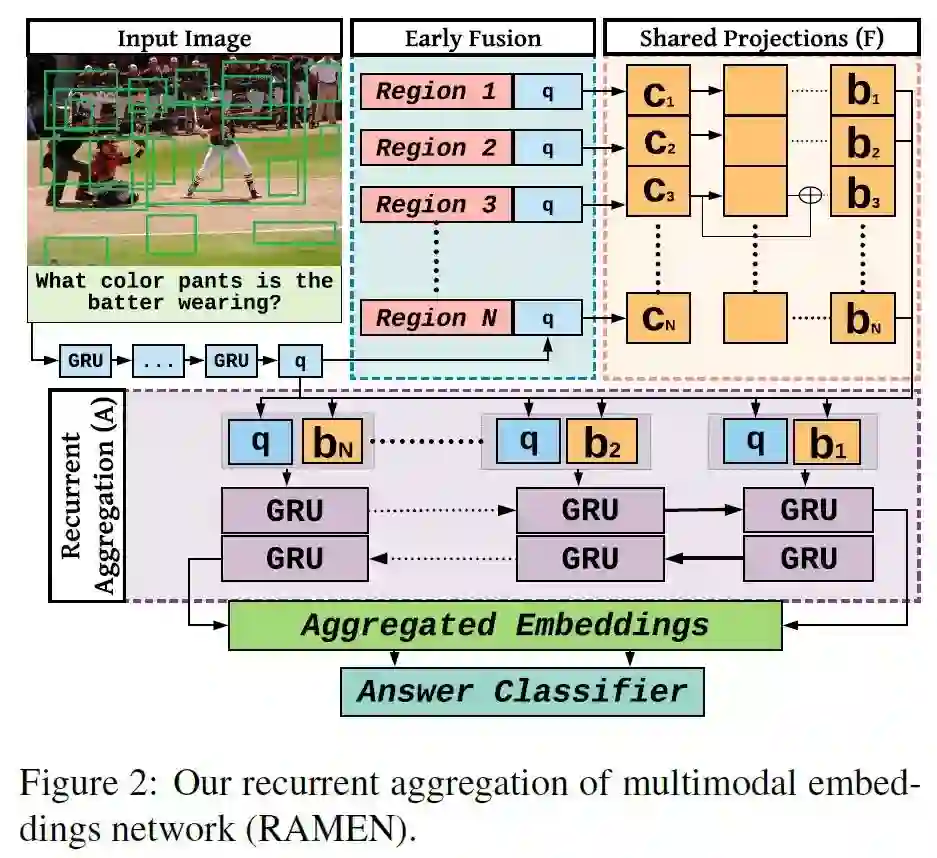
5、Answer Them All! Toward Universal Visual Question Answering Models(回答他们所有人!基于通用的视觉问答模型)
CVPR ’19
作者:Robik Shrestha, Kushal Kafle, Christopher Kanan
摘要:视觉问答(VQA)研究分为两个阵营:第一个阵营关注需要自然图像理解的VQA数据集,第二个阵营关注测试推理的合成数据集。一个好的VQA算法应该同时具备这两种功能,但是只有少数VQA算法是以这种方式进行测试的。我们比较了涵盖这两个领域的8个VQA数据集中的5种最先进的VQA算法。为了公平起见,所有的模型都尽可能标准化,例如,它们使用相同的视觉特性、答案词表等。我们发现,这些方法不能泛化到这两个领域。为了解决这一问题,我们提出了一种新的VQA算法,它可以与这两个领域的最先进算法相媲美或超过它们。
网址:
https://arxiv.org/abs/1903.00366
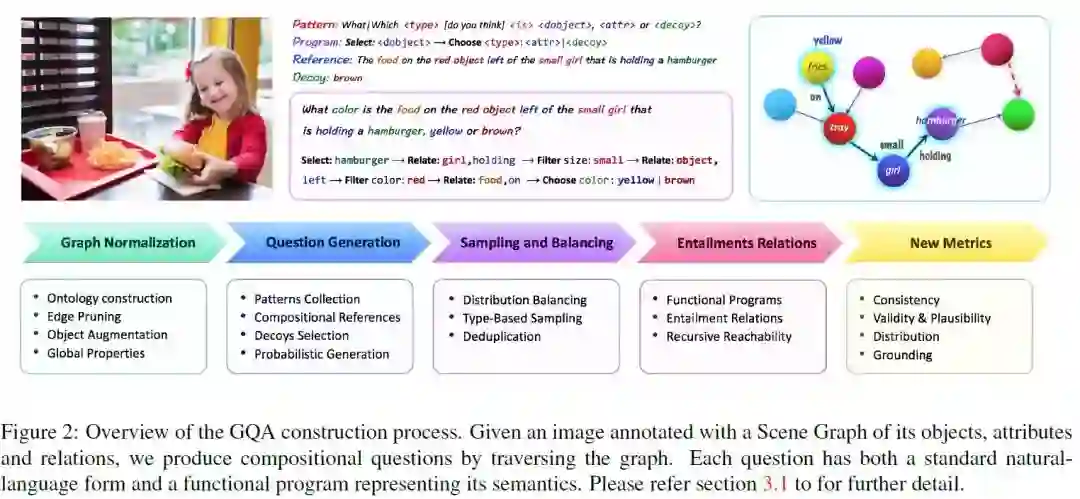
6、GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering(GQA: 一个用于真实世界的视觉推理和合成问题回答的新数据集)
CVPR ’19
作者:Drew A. Hudson, Christopher D. Manning
摘要:我们介绍了一个新的数据集GQA,用于真实世界的视觉推理和合成问题回答,试图解决以前的VQA数据集的关键缺陷。我们开发了一个强大而健壮的问题引擎,它利用场景图结构创建了2200万个不同的推理问题,所有这些问题都带有表示其语义的功能程序。我们使用这些程序来获得对答案分布的严格控制,并提出了一种新的可调平滑技术来减少问题的偏差。随数据集而来的是一套新的度量标准,用于评估consistency、grounding和plausibility等基本质量。对baseline和最先进的模型进行了广泛的分析,为不同的问题类型和拓扑提供了细粒度的结果。一个单独的LSTM仅获得42.1%的结果,强大的VQA模型达到54.1%,而人类的表现最高达到89.3%,这为探索新的研究提供了充足的机会。我们强烈希望GQA能够为下一代模型提供支持资源,增强健壮性、改进一致性以及对图像和语言更深入的语义理解。
网址:
https://arxiv.org/abs/1902.09506v2
https://cs.stanford.edu/people/dorarad/gqa/about.html
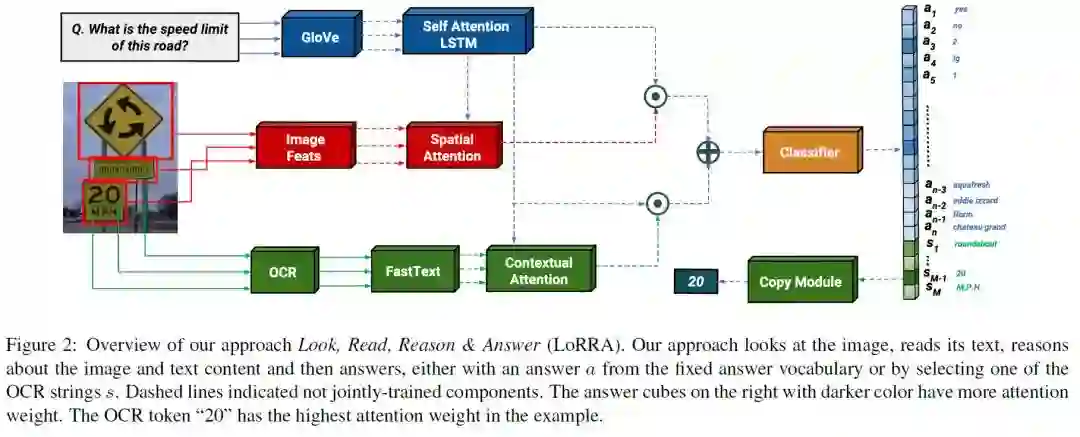
7、Towards VQA Models that can Read(面向可读的VQA模型)
CVPR ’19
作者:Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, Marcus Rohrbach
摘要:研究表明,视障用户对周围环境图像提出的主要问题包括阅读图像中的文字。但是今天的VQA模型不能读取! 我们的论文朝着解决这个问题迈出了第一步。首先,我们引入一个新的“TextVQA”数据集来促进在这个重要问题上的进展。现有的数据集要么有一小部分关于文本的问题(例如,VQA数据集),要么太小(例如,VizWiz数据集)。TextVQA包含45,336个问题,涉及28,408张图像,需要对文本进行推理才能回答。其次,我们介绍了一种新的模型架构,它可以读取图像中的文本,在图像和问题的上下文中对其进行推理,并预测一个可能是基于文本和图像的推理或由图像中发现的字符串组成的答案。因此,我们称我们的方法为“Look, Read, Reason & Answer”(LoRRA)。我们在TextVQA数据集中展示了LoRRA优于现有的最先进的VQA模型。我们发现,在TextVQA上,人类性能和机器性能之间的差距明显大于VQA 2.0,这表明TextVQA非常适合在与VQA 2.0互补的方向上进行基准测试。
网址:
https://arxiv.org/abs/1904.08920v1
代码链接:
https://www.groundai.com/project/towards-vqa-models-that-can-read/
下载链接:https://pan.baidu.com/s/1LNSFxz5nIwDi2o4nRrb_MA 提取码:yfq2

