【图神经网络入门】GAT图注意力网络
本文是清华大学刘知远老师团队出版的图神经网络书籍《Introduction to Graph Neural Networks》的部分内容翻译和阅读笔记。
个人翻译难免有缺陷敬请指出,如需转载请联系翻译作者@Riroaki。
注意机制已成功用于许多基于序列的任务,例如机器翻译,机器阅读等等。与GCN平等对待节点的所有邻居相比,注意力机制可以为每个邻居分配不同的注意力得分,从而识别出更重要的邻居。将注意力机制纳入图谱神经网络的传播步骤是很直观的。图注意力网络也可以看作是图卷积网络家族中的一种方法。
Graph Attention Network (GAT)
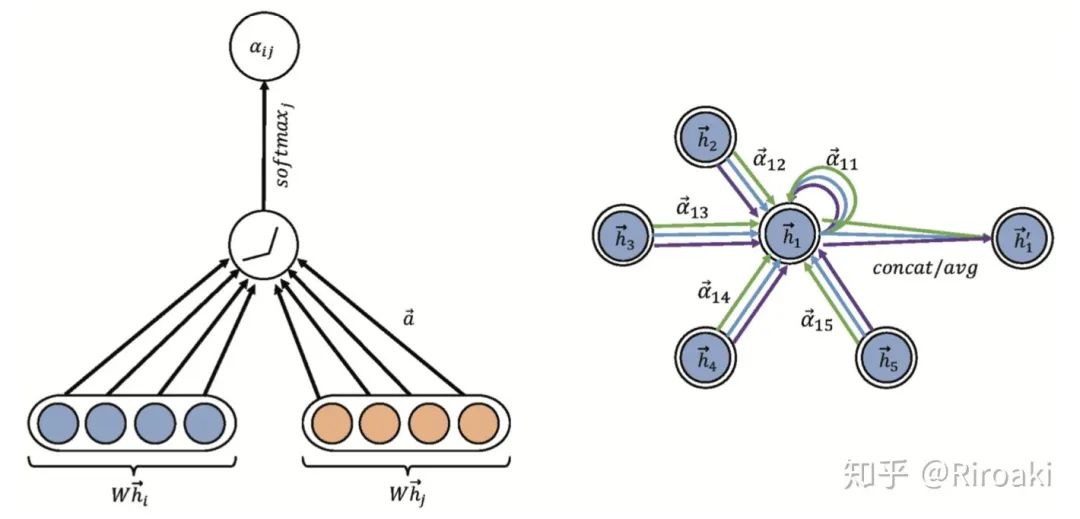
GAT在传播过程引入自注意力(self-attention)机制,每个节点的隐藏状态通过注意其邻居节点来计算。
GAT网络由堆叠简单的图注意力层(graph attention layer)来实现,对节点对 
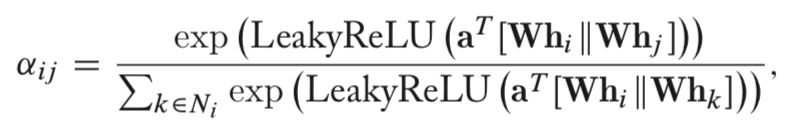
其中, 









最终节点的特征输出由以下式子得到:
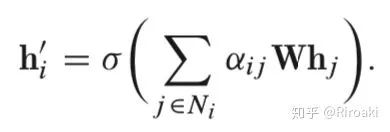
此外,该层也利用多头注意力以稳定学习过程。它应用 K 个独立的关注机制来计算隐藏状态,然后将其特征连接起来(或计算平均值),从而得到以下两种输出表示形式:
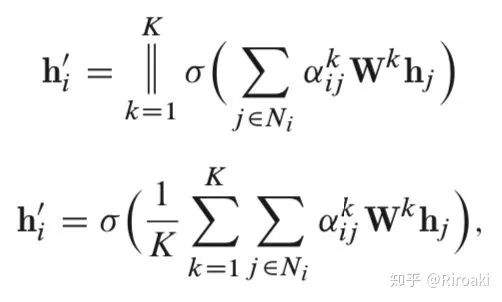
其中 

这一模型结构具有如下特点:
节点-邻居对的计算是可并行化的,因此运算效率很高(和GCN同级别);
可以处理不同程度的节点,并为其邻居分配相应的权重;
可以很容易地应用于归纳学习(inductive learning)问题。
与GCN类似,GAT同样是一种局部网络,无需了解整个图结构,只需知道每个节点的邻节点即可。
补充:
归纳学习(inductive learning)与转导学习(transductive learning)
在半监督学习场景中,大部分数据是没有标注的。
如果和常规的学习一样使用归纳学习,只采用标注数据进行训练,并且尝试对没有见过的数据进行分类,效果可能会很糟糕。
但是转导学习就不同。它可以引入没有标签的数据,学习数据的分布信息,并且在测试时对(已经见过的)没有标注的数据进行分类。
因此,一般来说转导学习的效果会更好。当然,一般的任务都是使用归纳学习模型解决。
以下来自维基百科(en.wikipedia.org/wiki/T):
归纳尝试从特殊案例归纳出一般特征(train),再应用于特殊案例(test)。
转导尝试从特定案例(train)中学习并应用到特定案例(test)。
后者的难度更小。
还有一个有趣的概念是主动学习(active learning),有兴趣的读者可以自行了解。
GAT在半监督节点分类,链接预测等多项任务上均胜过GCN。
详见原论文《Graph attention networks》
Gated Attention Network (GaAN)
除了GAT之外,门控注意力网络(GaAN)也使用多头注意力机制。GaAN中的注意力聚合器与GAT中的注意力聚合器的区别在于,GaAN使用键值注意力和点积注意力,而GAT使用全连接层来计算注意力系数。
此外,GaAN通过计算其他soft gate为不同的注意力头分配不同的权重。该聚合器称为门控注意聚合器。详细地讲,GaAN使用卷积网络,该卷积网络具有中心节点的特征,并且与之相邻以生成门值。
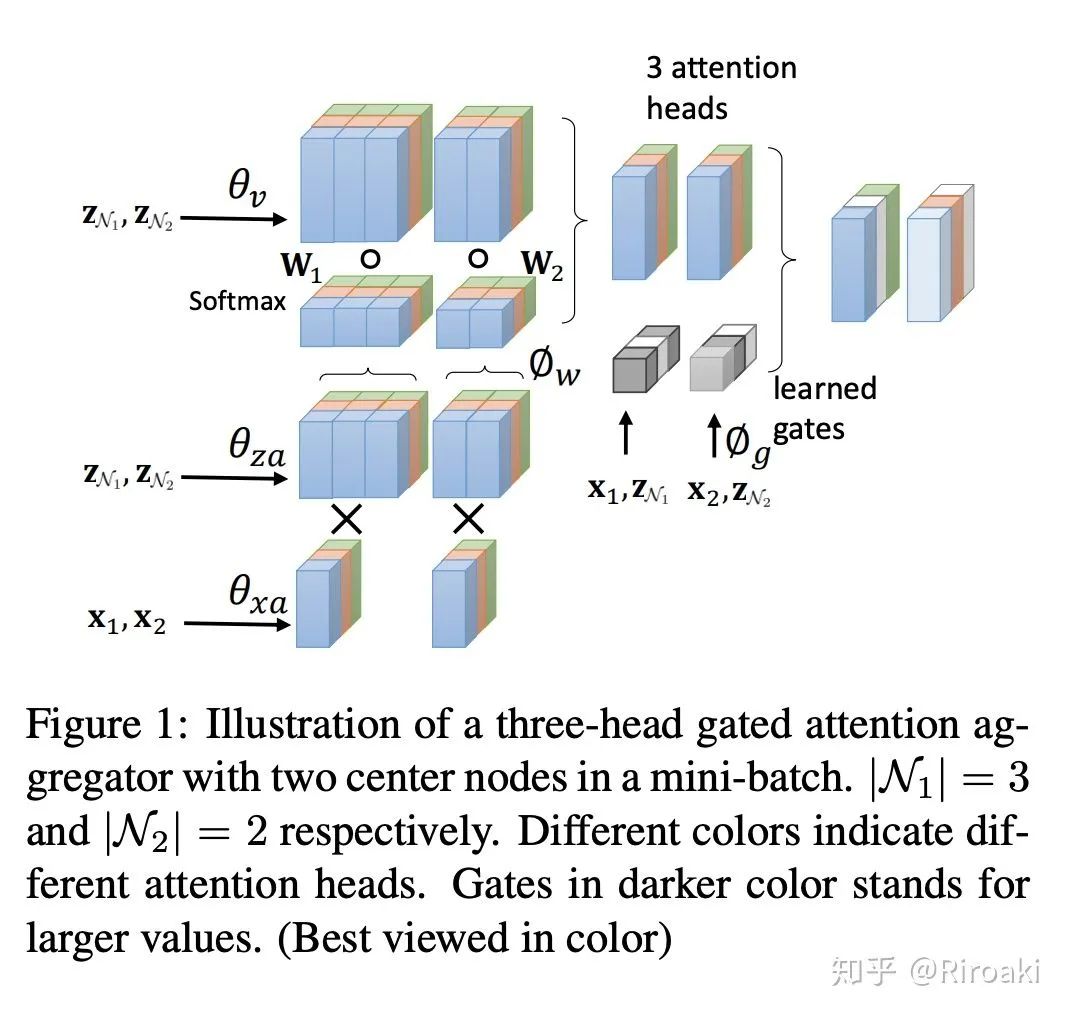
在归纳节点分类问题中,GaAN可以优于GAT以及其他具有不同聚合器的GNN模型。
关于本模型的细节,原文没有过多介绍,有待补充。
详见原论文《GaAN: Gated Attention Networks for Learning on Large and Spatiotemporal Graphs》






