论文链接:
https://arxiv.org/pdf/2110.00966.pdf
在近期一篇论文中,来自萨里大学的研究者引入了注意力机制,将自动驾驶的 2D 图像转换为鸟瞰图,使得模型的识别准确率提升了 15%。这项研究在不久前落幕的 ICRA 2022 会议上获得了杰出论文奖。
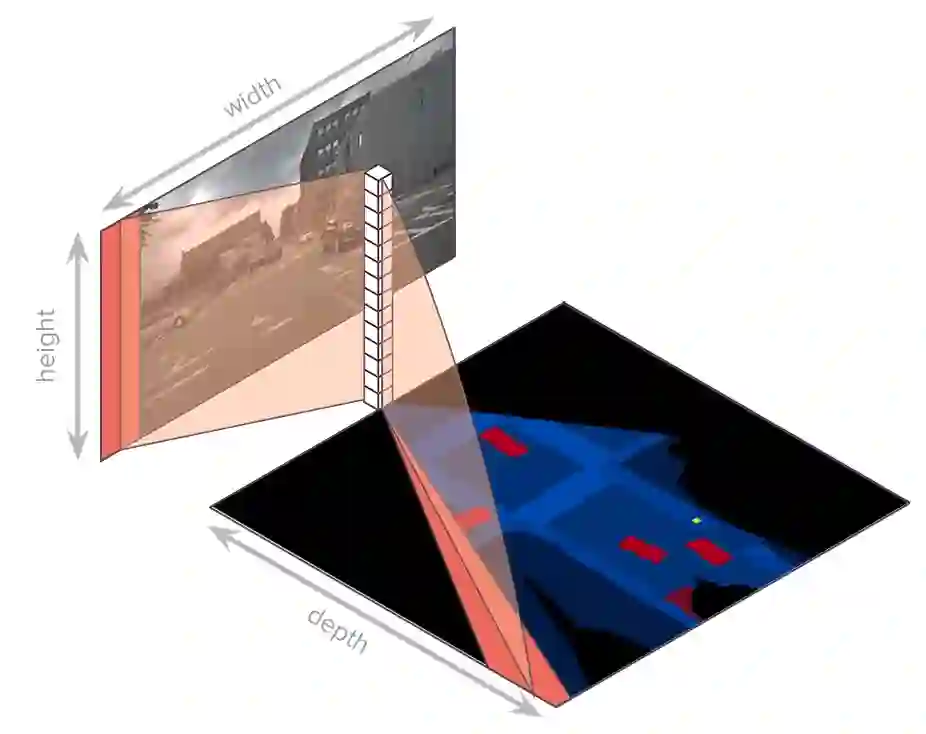
对于自动驾驶中的许多任务来说,从自上而下、地图或鸟瞰 (BEV) 几个角度去看会更容易完成。由于许多自动驾驶主题被限制在地平面,所以俯视图是一种更实用的低维表征,对于导航也更加理想,能够捕获相关障碍和危险。对于像自主驾驶这样的场景,语义分割的 BEV 地图必须作为瞬时估计生成,以处理自由移动的对象和只访问一次的场景。
要想从图像推断 BEV 地图,就需要确定图像元素与它们在环境中的位置之间的对应关系。 此前的一些研究以稠密深度图和图像分割地图指导这种转换过程,还有研究延展了隐式解析深度和语义的方法。一些研究则利用了相机的几何先验,但并没有明确地学习图像元素和 BEV 平面之间的相互作用。
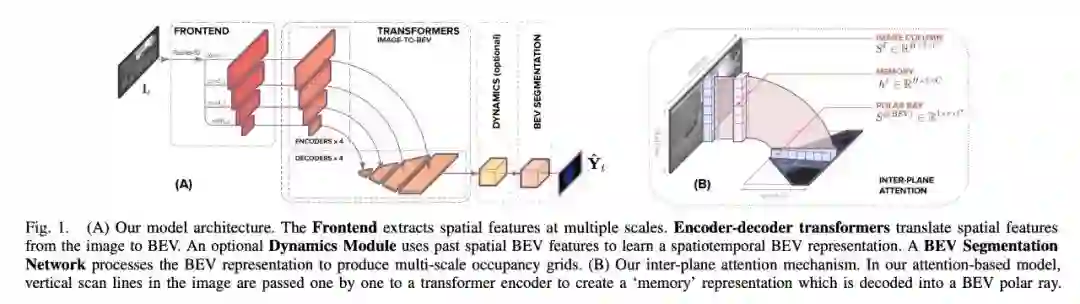
与以往的方法不同,这项研究将 BEV 的转换视为一个「Image-to-World」的转换问题 ,其目标是学习图像中的垂直扫描线(vertical scan lines)和 BEV 中的极射线(polar ray)之间的对齐。因此,这种射影几何对网络来说是隐式的。
在对齐模型上,研究者采用了 Transformer 这种基于注意力的序列预测结构 。利用其注意力机制,研究者明确地建模了图像中垂直扫描线与其极性 BEV 投影之间的成对相互作用。
Transformer 非常适合图像到 BEV 的转换问题,因为它们可以推理出物体、深度和场景照明之间的相互依赖关系,以实现全局一致的表征。
研究者将基于 Transformer 的对齐模型嵌入到一个端到端学习公式中,该公式以单目图像及其固有矩阵为输入,然后预测静态和动态类的语义 BEV 映射。
本文构建了一个体系结构,有助于从对齐模型周围的单目图像预测语义 BEV 映射。如下图 1 所示,它包含三个主要组成部分:一个标准的 CNN 骨干,用于提取图像平面上的空间特征;编码器 - 解码器 Transformer 将图像平面上的特征转换为 BEV;最后一个分割网络将 BEV 特征解码为语义地图。
(1)用一组 1D 序列 - 序列的转换从一幅图像中生成一个 BEV 图;
(2)构建了一个受限制的数据高效的 Transformer 网络,具备空间感知能力;
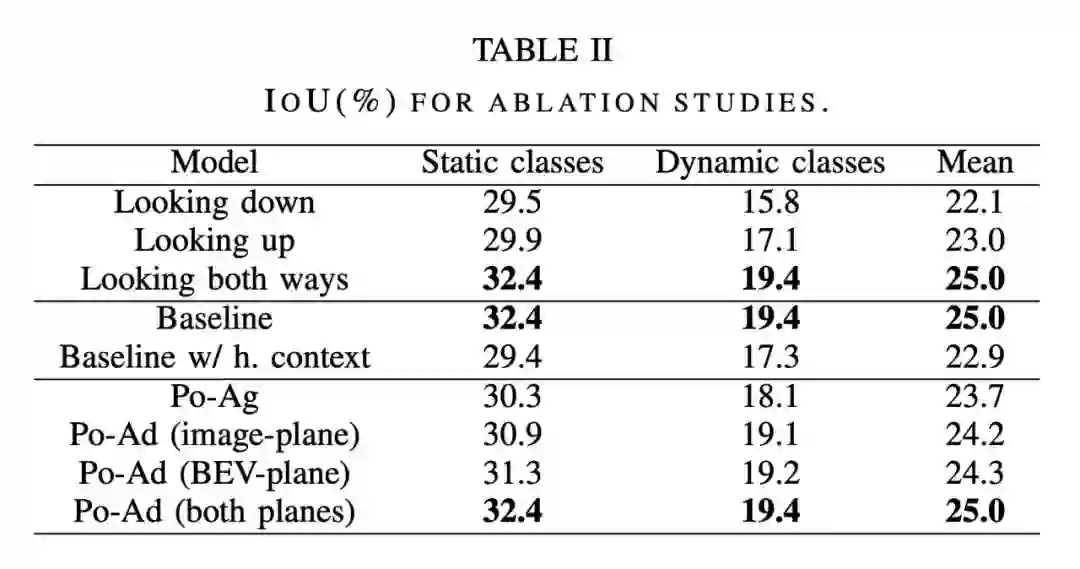
(3)公式和语言领域单调注意力的结合表明,对于精确的映射来说,知道图像中一个点下面是什么比知道它上面是什么更重要,尽管两者都使用会导致最佳性能;
(4)展示了轴向注意力如何通过提供时间意识来提高性能,并在三个大规模数据集上展示了最新的结果。
在实验中,研究者做了几项评估:将图像到 BEV 的转换作为 nuScenes 数据集上的转换问题评估其效用;在单调注意力中消融回溯方向,评估长序列水平上下文的效用和极位置信息(polar positional information)的影响。最后,将该方法与 nuScenes 、Argoverse 和 Lyft 数据集的 SOTA 方法进行比较。
如下表 2 的第一部分所示,研究者比较了软注意力 (looking both ways)、图像底部回溯(looking down) 的单调注意力、图像顶部回溯 (looking up) 的单调注意力。
结果表明,从图像中的一个点向下看比向上看要好。
沿着局部的纹理线索——这与人类在城市环境中试图确定物体距离的方法是一致的,我们会利用物体与地平面相交的位置。结果还表明,两个方向的观察都进一步提高了精度,使深度推理更具有识别力。
长序列水平上下文的效用。 此处的图像 - BEV 转换是作为一组 1D 序列 - 序列转换进行的,因此一个问题是,当整个图像被转换成 BEV 时会发生什么。考虑到生成注意力地图所需的二次计算时间和记忆力,这种方法的成本高得令人望而却步。然而,可以通过在图像平面特征上应用水平轴向注意力,取得近似使用整个图像的上下文效益。借助通过图像行的轴向注意力,垂直扫描线中的像素现在具备了长距离的水平上下文,之后像以前一样,通过在 1D 序列之间转换来提供长距离的垂直上下文。
如表 2 中间部分所示,
合并长序列水平上下文并不会使模型受益 ,甚至略有不利影响。这说明了两点:首先,每个转换后的射线并不需要输入图像整个宽度的信息,或者更确切地说,比起已经通过前端卷积聚合的上下文,长序列上下文并没有提供任何额外的好处。这表明,使用整个图像执行转换,不会让模型精度提高以至超过 baseline 约束公式;此外,引入水平轴向注意力导致的性能下降意味着使用注意力训练图像宽度的序列的困难,可以看出,使用整个图像作为输入序列的话,会更难训练。
Polar-agnostic vs polar-adaptive Transformers :表 2 最后一部分比较了 Po-Ag 与 Po-Ad 的变体。一个 Po-Ag 模型没有极化位置信息,图像平面的 Po-Ad 包括添加到 Transformer 编码器中的 polar encodings,而对于 BEV 平面,这些信息会加入到解码器中。在任何一个平面上添加 polar encodings 都比在不可知模型上添加更有益处,其中动态类的增加最多。将它添加到两个平面会进一步强化这一点,但对静态类的影响最大。
研究者将本文方法与一些 SOTA 方法进行了比较。
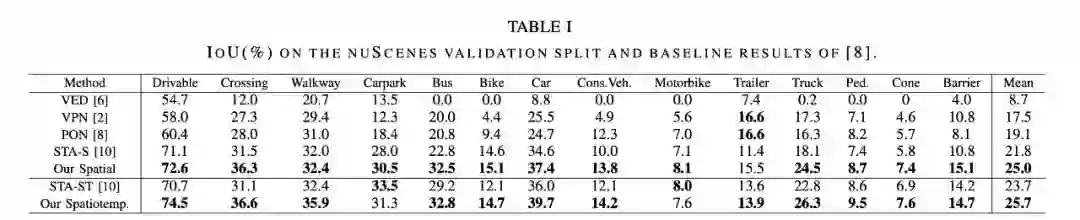
如下表 1 所示,空间模型的表现优于目前压缩的 SOTA 方法 STA-S ,平均相对改善 15% 。在更小的动态类上,改善更加显著,公共汽车、卡车、拖车和障碍物的检测准确度都增加了相对 35-45% 。
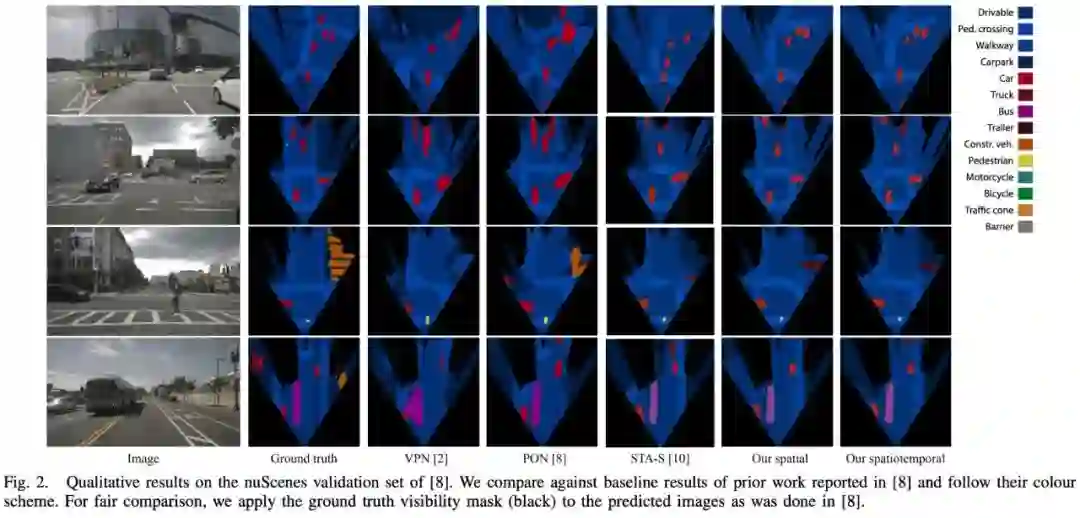
下图 2 中得到的定性结果也支持了这一结论,本文模型显示出更大的结构相似性和更好的形状感。这种差异可以部分归因于用于压缩的全连接层(FCL) : 当检测小而遥远的物体时,图像的大部分是冗余的上下文。
此外,行人等物体往往部分被车辆挡住。在这种情况下,全连接层将倾向于忽略行人,而是保持车辆的语义。在这里,注意力方法展示出了它的优势,因为每个径向深度都可以独立地注意到图像ーー如此,更深的深度可以使行人的身体可见,而此前的深度只可以注意到车辆。
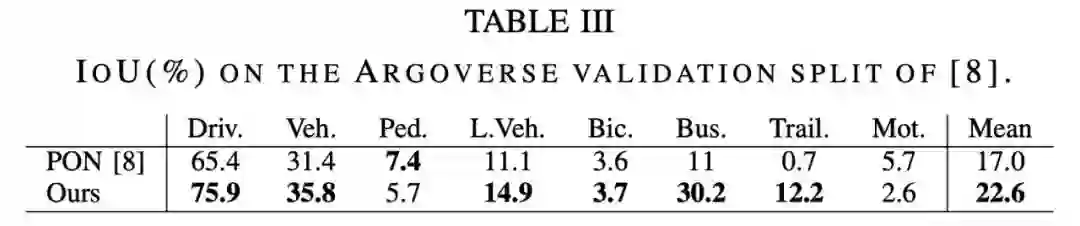
下表 3 中 Argoverse 数据集上的结果展示了类似的模式,其中本文方法对比 PON [8]提高了 30% 。
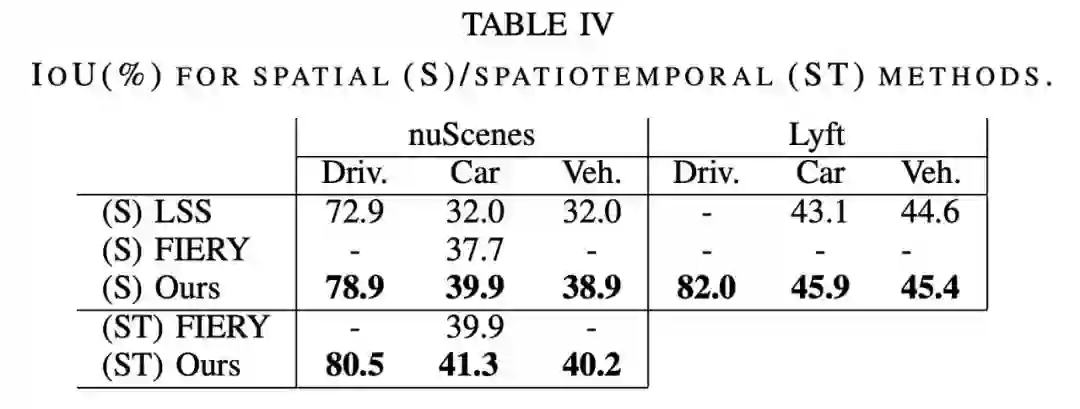
如下表 4 所示,本文方法在 nuScenes 和 Lyft 上的表现优于 LSS [9]和 FIERY [20]。在 Lyft 上进行真正的对比是不可能的,因为它没有规范的 train/val 分割,而且无法获得 LSS 所使用的分割。
公众号后台回复“ 目标检测综述 ” 获取目标检测(2001-2021)综述PDF~
极市平台深耕CV开发者领域近5年,拥有一大批优质CV开发者受众,覆盖微信、知乎、B站、微博等多个渠道。通过极市平台,您的文章的观点和看法能分享至更多CV开发者,既能体现文章的价值,又能让文章在视觉圈内得到更大程度上的推广。
对于优质内容开发者,极市可推荐至国内优秀出版社合作出书,同时为开发者引荐行业大牛,组织个人分享交流会,推荐名企就业机会,打造个人品牌 IP。
2.
极市平台尊重原作者署名权,并支付相应稿费。文章发布后,版权仍属于原作者。
3.原作者可以将文章发在其他平台的个人账号,但需要在文章顶部标明首发于极市平台
添加小编微信Fengcall(微信号:fengcall19),备注:姓名-投稿