CVPR 2022 | BoxeR:用于2D和3D Transformer的Box新注意力机制
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:煎饼果子不要果子 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/447928002

BoxeR: Box-Attention for 2D and 3D Transformers
论文:arxiv.org/abs/2111.13087
代码(现已开源):
https://github.com/kienduynguyen/BoxeR
主要思路和创新点
这篇文章主要基于 Deformable DETR 做了进一步拓展,以下描述都会基于已经清楚了 Deformable DETR 结构的假设,可参考:训练加快10倍!性能更强!商汤等提出可变形DETR目标检测网络
本文的出发点是希望将空间信息引入 Transformer 结构中,作者称位置编码或位置插入本质其实就是对特征的增强,毕竟是将一个序列加到原特征上,因此要求网络隐式地推断空间信息,效果并没有很好~
Deformable DETR 是通过对原特征学出需要的注意的几个点以及其相应注意力权重,而本文提出,只注意一个 box 区域内的所有点:
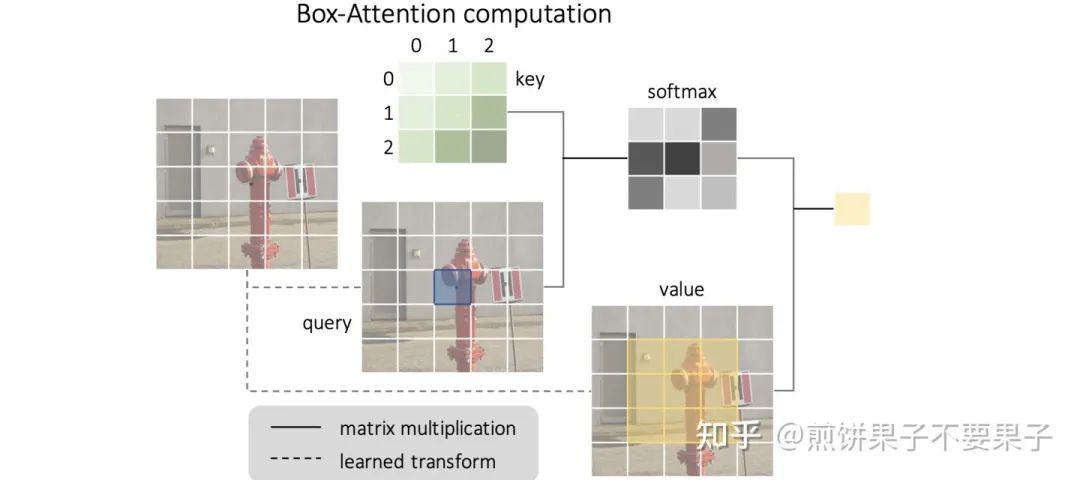
K 是一个可学习的矩阵,因为目前版本是固定大小,因此可以将它理解为一个局部的位置编码。之后这个 K 与要计算的 q 点积,softmax 后得到注意力权重图,再与相应位置的 V 相乘就能得到最后值。
写成公式,每个端口的计算为:
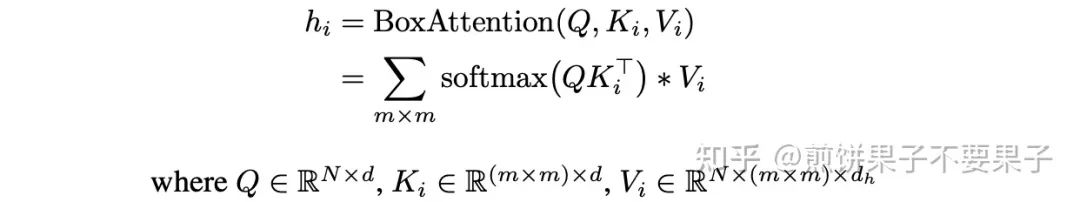
i 是不同端口的下标,m*m 就是要注意的 box 大小。其实乍一看和可变形 DETR 完全不同,但是内涵是一样的。作者在文中也称,实际操作中前面的注意力权重图可以直接通过对 Q 进行线性映射得到,这个线性映射的参数矩阵实际上就是 K,这部分就和 Deformable DETR 一样啦。
同时,本文也继续沿用了 FPN 的多尺度结构,和可变形一样,就是将 box 预测大小调整为 t*m*m,t 为尺度的层数。截止到目前,在这里说的都是一个固定大小的 box,对于每个 q 都是一样的,跟着 q 调整中心位置。作者进一步提出了 where-to-attend,即通过对 q 学出一个 box 的位置和大小偏差,实际上也就是输出为 4 个参数的线性映射。
偏差调整公式为:
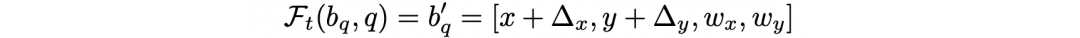
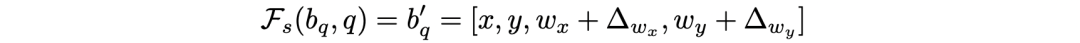
看图更清楚:
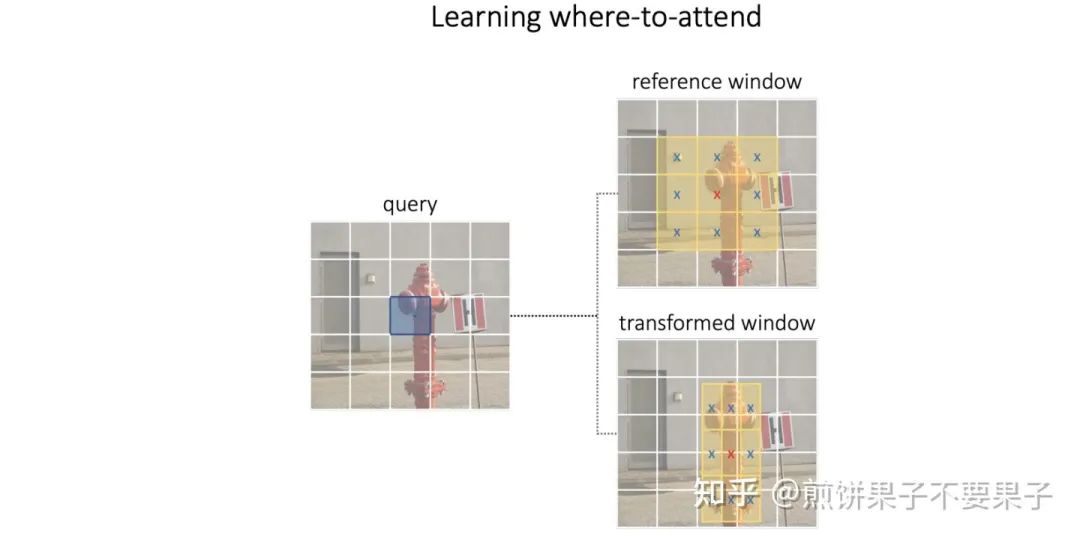
在编码器中,使用的几张多尺度特征图和可变形中是一样的:
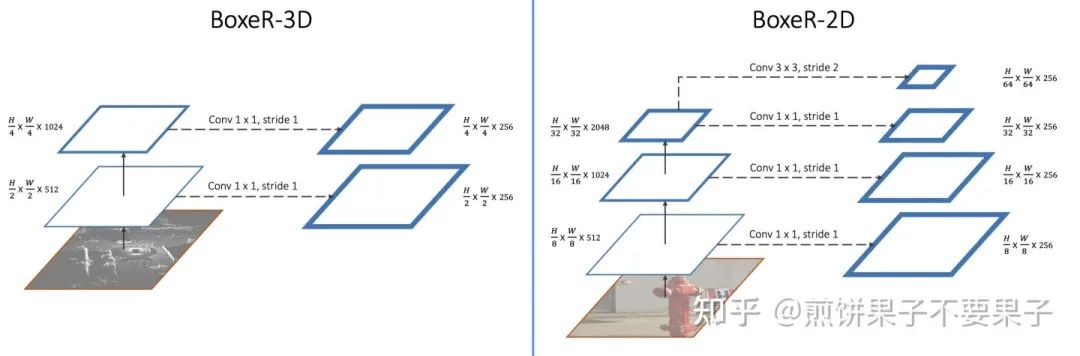
之后对于四个不同尺度,最初的 box 设定大小从下到上为 [32*32, 64*64, 128*128, 256*256] 像素点,但实际上换成特征图上都是 4*4。因为 Attention 使用的是多端口,在学习 box 偏差的时候都不一样,这就允许了不同长宽比的任意变化,因此没有必要专门设计更多初始 box。
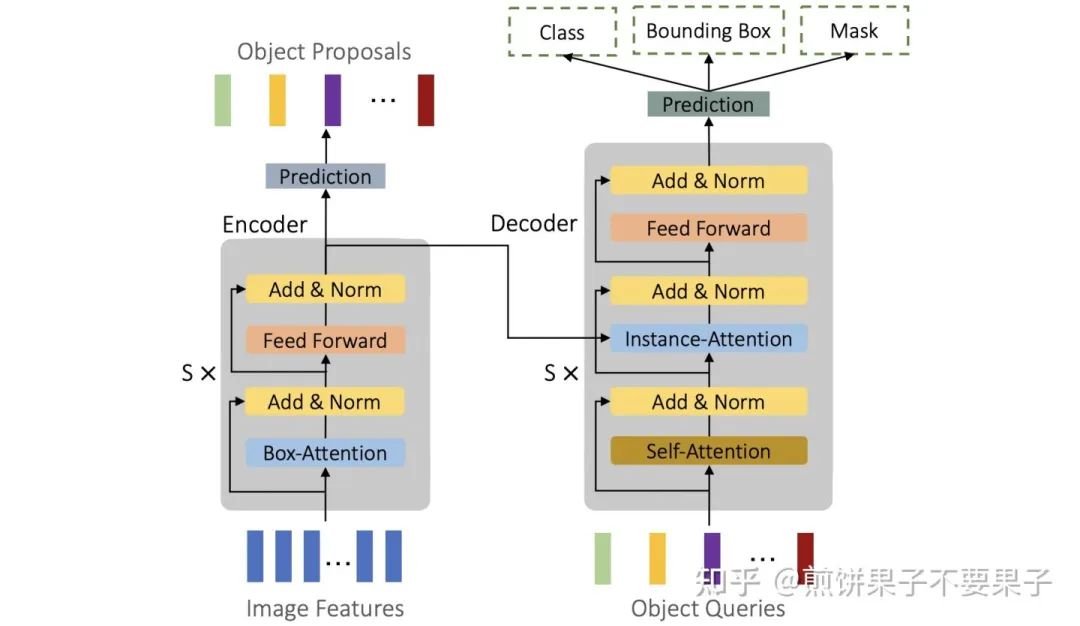
这些特征在输入 Transformer 前会加上一个位置编码,同时还为不同尺度设计了编码,均采用 sinusoid 以及标准化。在编码器过渡到解码器的阶段中,与可变形一样,依然先对最后一层的输出特征使用预测端来帮助解码器的初始化。
预测端会选取分数最高的一些候选框,用这些检测框来作为解码器 query 的注意力基本 box。解码器中 Self-Attention 仍然沿用基础版,Cross-Attention 变为文中提出的 box 变版,除了继续预测特征,还会预测一个用于实例分割大小为 m*m*d 的 mask。
注意到其中每个 q 的注意力图为 t*m*m,预测特征时会将三个维度都 softmax 标准化,整体加总为 1,之后与相应的 v 相乘求和。但在预测 mask 时,只针对 t 维度标准化,求和也是针对该维度,因此会生成 m*m*d 大小的 mask 特征。作者称这部分是因为要对中间层做辅助损失?
下图是一个整体结构:
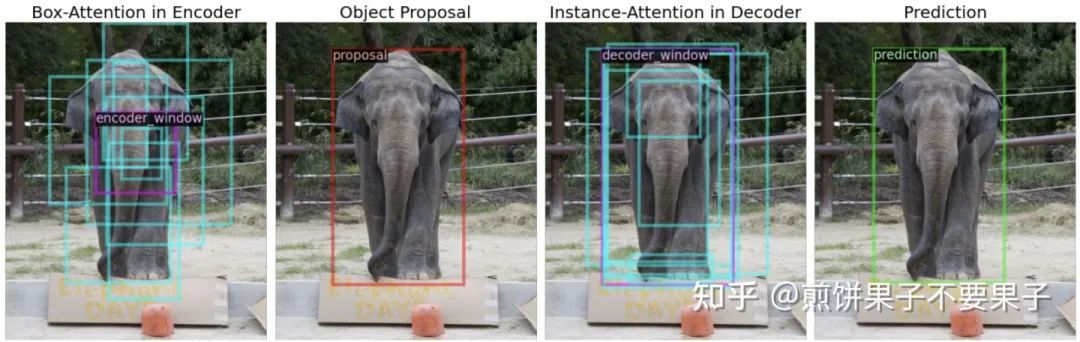
这部分给了一些注意力 box 的可视化示例:
之后作者还针对 3D 检测任务给了一些变化,首先,预测的位移偏差还要加上一个角度:
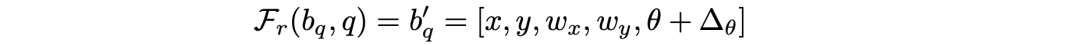
初始的基本 box 也有三个不同的角度:
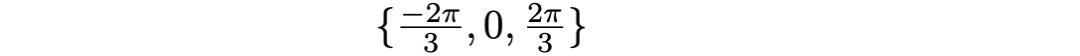
文中说是每个 Attention 端口会分配一个角度。

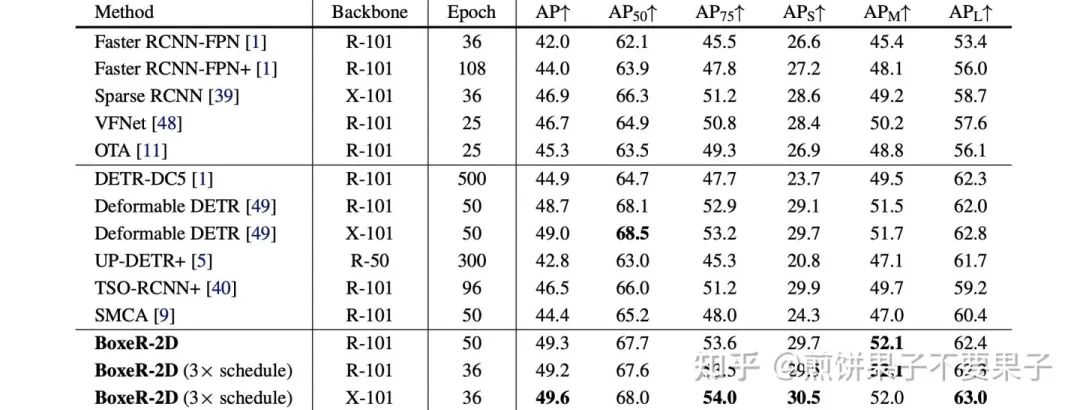
实验结果和可视化
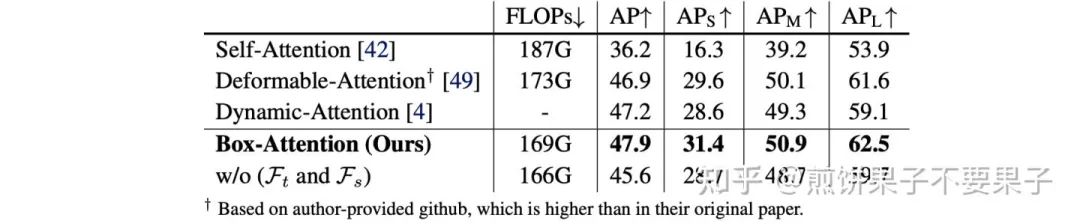
确实对可变形 DETR 有提升~


上面论文和代码下载
后台回复:BoxeR,即可下载上面的论文和代码
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号


整理不易,请点赞和在看