【华南理工大学ICCV-CVPR2019】基于单一的RGB图像的拓扑感知的三维物体重建
从单张图片恢复出三维物体形状这一研究课题在许多应用中扮演着重要的角色,例如增强现实,图像编辑。但是由于物体的拓扑结构复杂多变,这一课题也颇具挑战性。目前,基于体素表达的方法受限于三维卷积网络计算和内存的限制而难以得到高分辨率的输出。基于点云表达的方法又很难生成平滑而又干净的表面。三角网格表达对物体形状提供了一种更有效,更自然的离散化逼近方式。最近的一些方法尝试直接从输入图像中恢复物体的网格表达。这些方法本质上是在对一个给定拓扑连接关系的初始网格变形,但它们都难以重建出拓扑复杂的物体形状。针对这一问题,华南理工大学几何感知与智能实验室,分别与香港中文大学(深圳)、微软亚研院以及南加州大学展开合作,提出两种能重建出拓扑复杂的物体形状的算法,非常有效地解决了这一难题。一种是以骨架(meso-skeleton)为桥梁融合多种形状表达方式优点的深度学习算法,已收录为CVPR2019 Oral论文。另一种算法提出了拓扑修正网络,能够在对初始网格变形的过程中动态地更新顶点连接关系,修正拓扑连接关系,该论文被ICCV2019所接受。
简介


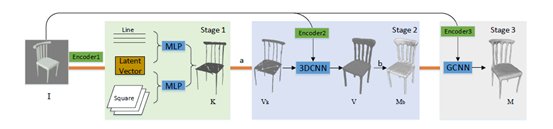
算法总览
骨架学习
用于骨架生成的CurSkeNet 和 SurSkeNet
骨架生成的网络训练
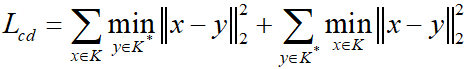
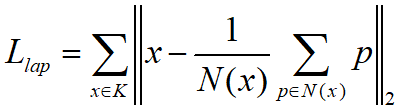
从骨架生成粗糙网格
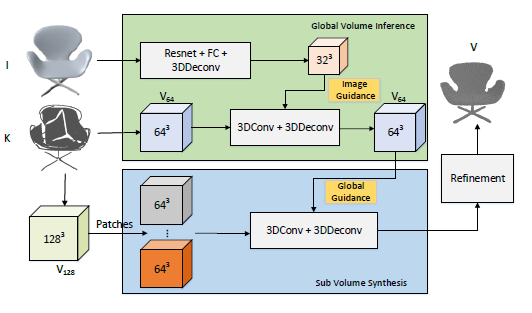
全局引导下的分子块合成
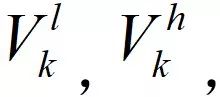 分辨率
为
分辨率
为
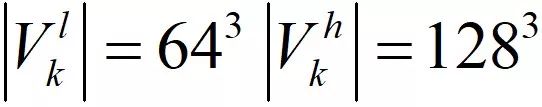 。
如图3所示,我们采用两个三维卷积网络用于骨架体素的全局结构和局部子块合成。
全局结构合成网络用于对
。
如图3所示,我们采用两个三维卷积网络用于骨架体素的全局结构和局部子块合成。
全局结构合成网络用于对
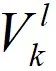 的
修复,产生一个分辨率为的骨架体素表达。
局部子块合成网络用从
的
修复,产生一个分辨率为的骨架体素表达。
局部子块合成网络用从
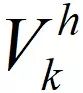 中均匀切割出来的64^3子块做输入,对这些子块独立地进行修复。
当修复每个子块的时候,全局网络的输出
中对应的32^3
对应的子块也被一起输入,使得每个子块修复后的结果仍然保持全局一致性。
中均匀切割出来的64^3子块做输入,对这些子块独立地进行修复。
当修复每个子块的时候,全局网络的输出
中对应的32^3
对应的子块也被一起输入,使得每个子块修复后的结果仍然保持全局一致性。

加入图像引导进行拓扑纠正
初始网格提取
初始网格变
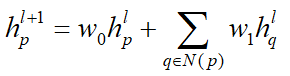
实验
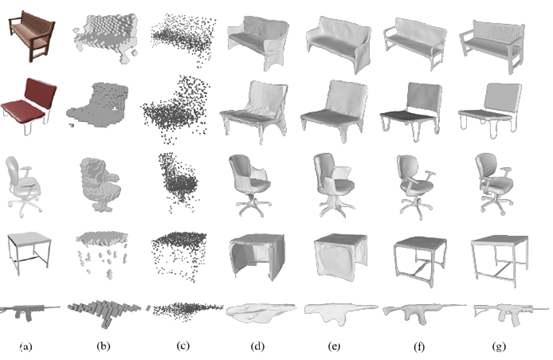
单视角物体重建
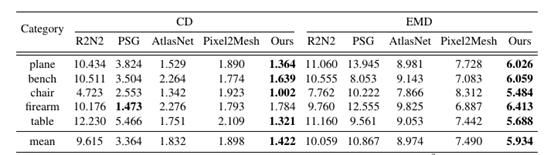
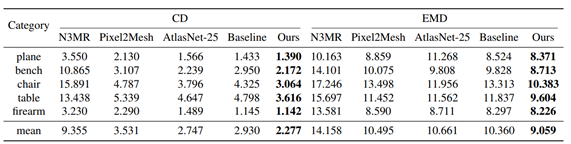
量化对比
真实图片泛化测试

骨架生成比较
量化对比
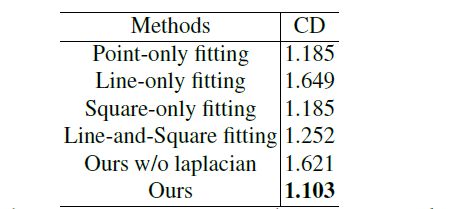
可视化对比


拓扑自适应(Topology-adaptive)网格重建
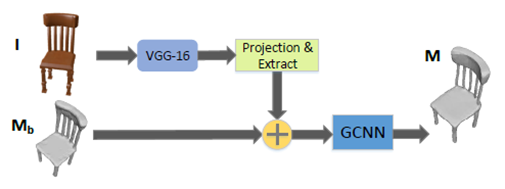
模型架构
网格形变模块
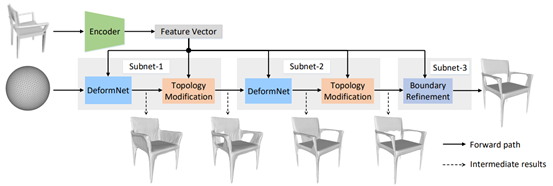
拓扑修正模块
误差估计
面片删除
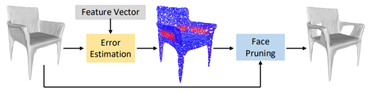
边界优化模块
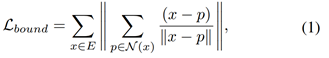
目标函数
倒角距离
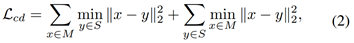
误差估计损失函数
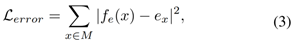
实验结果

总结


登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文