

为了克服在合成数据集上训练的去雾模型的过拟合问题,许多最近的方法试图使用非成对数据进行训练来提高模型的泛化能力。然而其中大多数方法仅仅简单地遵循 CycleGAN 的思路构建去雾循环和上雾循环,却忽略了现实世界中雾霾环境的物理特性,即雾霾对物体可见度的影响随深度和雾气密度而变化。
在本文中,我们提出了一种自增强的图像去雾框架,称为D4(Dehazing via Decomposing transmission map into Density and Depth),用于图像去雾和雾气生成。我们所提出的框架并非简单地估计透射图或清晰图像,而是聚焦于探索有雾图像和清晰图像中的散射系数和深度信息。通过估计的场景深度,我们的方法能够重新渲染具有不同厚度雾气的有雾图像,并用于训练去雾网络的数据增强。值得注意的是,整个训练过程仅依靠非成对的有雾图像和清晰图像,成功地从单个有雾图像中恢复了散射系数、深度图和清晰内容。
综合实验表明,我们的方法在参数量和 FLOP 更少的情况下去雾效果优于最先进的非成对去雾方法。本工作是由京东探索研究院联合天津大学、悉尼大学完成,已经被CVPR2022 接收。


01 研究背景
雾霾是由气溶胶粒子在大气中的散射效应引起的一种自然现象。它会严重影响图片中的内容的可见性,给人类和计算机视觉系统带来影响。
借助深度神经网络强大的学习能力,大量的有监督方法都已经被提出并被应用于图像去雾。通过使用大量合成的有雾-清晰图像对的训练,有监督的深度去雾方法在特定的测试集上取得了令人满意的结果。然而,合成的有雾图像和真实世界的有雾图像之间存在较大的差距。仅仅在成对图像上进行训练的去雾模型很容易过拟合,从而导致在真实世界有雾图像中泛化很差的现象。
而由于现实世界中有雾/清晰的图像很难获得,所以近年来,研究人员提出了许多使用非成对有雾/清晰图像的深度学习方法来训练图像去雾模型。其中,许多方法采用了基于CycleGAN[1] 的思想,来构建去雾循环和上雾循环,从而可以在进行有雾图像和清晰图像进行转换的同时保持内容一致性。
然而,我们认为,简单地使用 CycleGAN 的思想,通过网络端到端地实现有雾图像域和清晰图像域之间的转换并不能够很好地解决非成对图像去雾这一问题。现有的基于构建循环的去雾方法忽略了真实有雾环境的物理特性,即真实世界中的雾气对图像的影响随着雾气浓度和深度的变化而变化,这种关系已经由大气散射模型[2]给出描述,即一张有雾图像可以表示为:
(1)
其中,J(x)为清晰图像,A为大气光,可以使用[3]中的方法直接确定。t(x)为透射图,可进一步表示为:
(2)
其中 β 为散射系数,可表示雾气的浓度,d(x)表示深度。如图1(i)和(iii)-(e)所示,基于 CycleGAN 的方法倾向于合成具有固定厚度的雾气,并且可能错误地模拟雾气效应,即,随着场景深度的增加,雾气应该变得更厚。
本方法目标是在原始 CycleGAN 处理非成对图像去雾方法的基础上,引入考虑雾气密度与场景深度的物理模型,使得模型在训练过程中可以合成更加真实且厚度有变化的雾气,从而达到数据增强,进而提升模型去雾效果的目的。
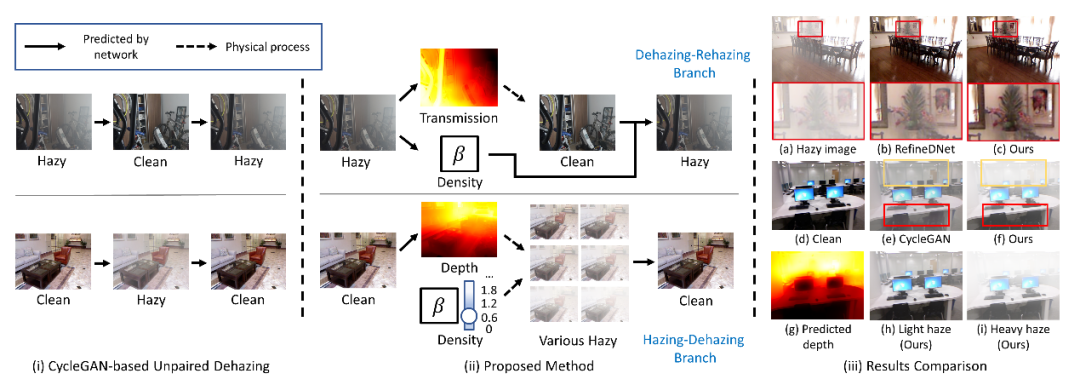
图1 (1)基于CycleGAN的非成对去雾图示,(2)所提出的方法图示及(3)结果对比
02 基于深度和密度分解的自增强非成
对图像去雾方法
我们提出了一种基于深度和雾气密度分解的自增强非成对图像去雾框架。其训练过程包括两个分支,去雾-上雾分支和上雾-去雾分支。如图2上半部分,在去雾-上雾分支中,一张有雾图像 首先输入去雾网络 中得到估计的透射图 和估计的散射系数 ,进一步通过式(1)合成清晰图像 。
同时,根据式(2),其深度 可以通过估计的透射图和散射系数一并求出。之后将 输入深度估计网络 ,得到估计的深度图 。然后使用得到的深度图 和先前得到的散射系数 根据式(1)、(2)得到粗有雾图像,再经过细化网络 得到最终的上雾图像 。而在上雾-去雾分支中,如图2下半部分,起点则变为了清晰图像 。
其首先输入深度估计网络 得到估计的深度 ,结合在均匀分布里随机采样的散射因子 ,根据式(1)、(2)得到粗上雾图像,再经过细化网络 得到上雾图像 。得到的上雾图像再经过去雾网络 得到估计的透射图 和估计的散射系数 ,进一步通过式(1)合成清晰图像 。
其中对散射因子 进行随机采样是我们的一个创新点,因为自然界中的雾气是有着轻重薄厚之分的,所以通过对散射因子 进行随机采样并输入到下面的雾气合成部分,我们的网络便可以在训练过程中提供富于薄厚变化的雾气,从而达到自增强的目的。
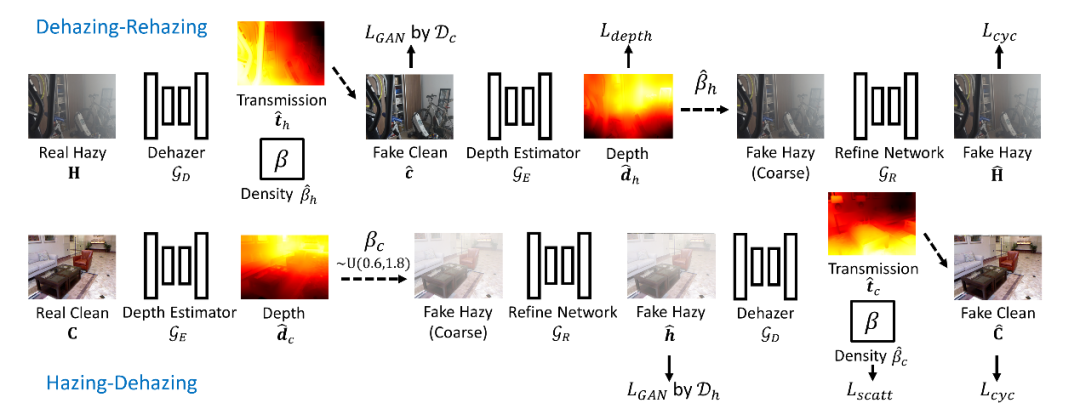
图2 框架训练过程示意图
注意这里 与 是非成对的清晰/有雾图像。为了保证整个框架能够正常训练,我们使用了若干项损失函数,包括循环一致性损失,对抗损失,伪散射因子监督损失和伪深度监督损失。
循环一致性损失要求在两个分支中,重建的有雾图像 应当与给定的有雾图像 一致,重建的清晰图像 应当与给定的清晰图像 一致。其目的是保持图像内容的一致性。循环一致性损失 表示为:
对抗损失评估生成的图像是否属于特定域。换句话说,它约束我们的去雾和再雾化图像应该是视觉上逼真的,并且分别遵循与训练集 和 中的图像具有相同的分布。对于去雾网络 和对应的判别器 ,对抗损失可以表示为:
其中 是从清晰图像集合 中采样得到的真实清晰图像样本。 是通过去雾网络 得到的去雾结果。 是用于判断输入图像是否属于清晰域的判别器。相对应的,图像细化网络 和对应的判别器 所使用的对抗损失可以表示为:
其中 是从有雾图像集合 中采样得到的真实有雾图像样本。 是通过细化网络 得到的上雾图片。 是用于判断输入图像是否属于有雾域的判别器。
由于并不存在直接可用的成对深度信息与成对的散射因子信息用于训练深度估计网络和散射因子估计网络。我们引入了伪散射因子监督损失和伪深度监督损失来训练这两个子网络。
伪散射因子监督损失是指在上雾-去雾分支中,由去雾网络 预测的散射因子 应当与随机生成的 的值保持一致。其可以表示为:
伪深度监督损失是指在去雾-上雾分支中,由深度网络 预测的深度 应当与由 和 求出的 保持一致。其可以表示为:
其中深度估计网络 直接由深度估计损失 优化,其余的模块则由 λλλ 优化,其中 λλ 。
03 实验结果
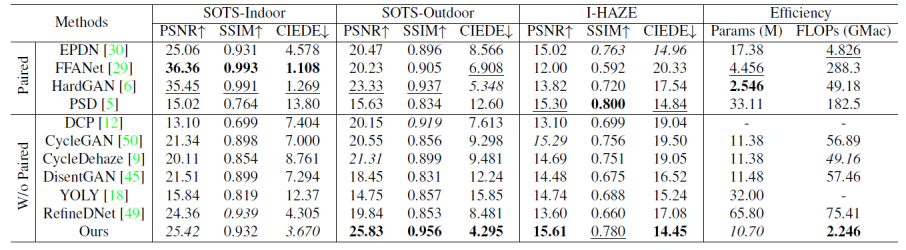
表1 各方法在各数据集上的性能表现
我们将所提出的方法与其他有监督,无监督以及非成对的去雾方法进行了对比,其中有监督的对比方法包括 EPDN[4]、FFANet[5]、HardGAN[6]、PSD[7],非成对方法包括CycleGAN[1], CycleDehaze[8], DisentGAN[9], RefineDNet[10],无监督方法包括DCP[3],YOLY[11]。
定量实验结果比较。为了验证我们的方法相较于有监督的方法有着更好的泛化性能,相较于其他无监督或非成对方法也有更好的去雾性能,我们在 SOTS-indoor 数据集上对这些方法进行训练并在其他数据集上测试它们的性能。同时我们还测试了这些方法的模型参数量和 FLOPs 用来测试这些模型的效率。结果如表1所示。
定性实验结果比较。为了验证我们的方法相较于其他方法的优势,我们还在多个数据集以及真实有雾图像上进行了定性的测试。其结果如图3、图4所示。其中图3第一组,第二组图像是 SOTS-indoor 的测试集,与训练集分布类似,可以看到 FFANet 去雾效果最好,我们的方法优于除了 FFANet 的其余方法。
第三四张分别来自 SOTS-outdoor 和 IHAZE 数据集,与训练集分布不同。可以看出我们的方法相较其他方法去雾更加彻底,且相对其他方法如 cycledehaze 颜色失真较小,生成的结果更加自然。图4展示了两个真实图像去雾的例子,可以看到我们的方法去雾结果明显好于其他方法,说明我们的模型泛化能力相对其他模型有着明显优势。
除此之外,我们的方法还可以用于有雾图像的生成,此类技术可以应用于图像或视频编辑中,相较于其他的方法,我们的方法生成的有雾图像可以随意变化雾气的薄厚程度,而且更加富有真实感,如图5所示。
另外,区别于其他的非成对图像去雾方法,我们的模型还支持对清晰图像进行相对深度预测,其效果如图6所示,虽然相比于其他有监督的深度估计网络,深度估计准确度有限,但我们的方法是首个能够利用非成对的有雾/清晰图像训练出了能够估计场景深度的方法。

** 图3各个方法在测试集上的定性效果比较**

图4 各个方法在真实图像上的去雾结果对比

图5 所提出的方法在生成有雾图像上的效果

图6 所提出的方法在深度估计上的效果
04 结论
本文提出了一种自增强的非成对图像去雾框架D4,该框架将透射图的估计分解为对雾气密度(散射因子)和深度图的预测。根据估计的深度,我们的方法能够重新渲染具有不同雾气厚度的有雾图像并且用作自增强,以提高模型去雾性能。充分的实验验证了我们的方法相对于其他去雾方法的优越性。
但我们的方法也存在着局限性,它通常会过度估计极端明亮区域的透射图,这将误导深度估计网络对过亮区域预测得到较小的深度值。并且我们发现低质量的训练数据会导致训练不稳定。尽管如此,我们提出的在物理模型中的变量进一步分解思路可以扩展到其他任务,比如低光照增强等。希望我们的方法能够启发未来的工作,尤其是底层视觉中的非成对学习任务。
文章:https://openaccess.thecvf.com/content/CVPR2022/html/Yang_Self-Augmented_Unpaired_Image_Dehazing_via_Density_and_Depth_Decomposition_CVPR_2022_paper.html 代码:代码已公布 https://github.com/YaN9-Y/D4
参考文献 [1] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle- consistent adversarial networks. In ICCV, pages 2223–2232, 2017 [2] Srinivasa G Narasimhan and Shree K Nayar. Chromatic framework for vision in bad weather. In CVPR, volume 1, pages 598–605, 2000. [3] Kaiming He, Jian Sun, and Xiaoou Tang. Single im- age haze removal using dark channel prior. IEEE TPAMI, 33(12):2341–2353, 2010. [4] Yanyun Qu, Yizi Chen, Jingying Huang, and Yuan Xie. En- hanced pix2pix dehazing network. In CVPR, pages 8160– 8168, 2019. [5] Xu Qin, Zhilin Wang, Yuanchao Bai, Xiaodong Xie, and Huizhu Jia. Ffa-net: Feature fusion attention network for single image dehazing. In AAAI, volume 34, pages 11908– 11915, 2020 [6] Qili Deng, Ziling Huang, Chung-Chi Tsai, and Chia-Wen Lin. Hardgan: A haze-aware representation distillation gan for single image dehazing. In ECCV, pages 722–738. [7] Zeyuan Chen, Yangchao Wang, Yang Yang, and Dong Liu. Psd: Principled synthetic-to-real dehazing guided by phys- ical priors. In CVPR, pages 7180–7189, June 2021. [8] Shiwei Shen, Guoqing Jin, Ke Gao, and Yongdong Zhang. Ape-gan: Adversarial perturbation elimination with gan. arXiv preprint arXiv:1707.05474, 2017. [8] Deniz Engin, Anil Genc¸, and Hazim Kemal Ekenel. Cycle- dehaze: Enhanced cyclegan for single image dehazing. In CVPRW, pages 825–833, 2018. [9] Xitong Yang, Zheng Xu, and Jiebo Luo. Towards percep- tual image dehazing by physics-based disentanglement and adversarial training. In AAAI, volume 32, pages 7485–7492, 2018. [10] Shiyu Zhao, Lin Zhang, Ying Shen, and Yicong Zhou. Refinednet: A weakly supervised refinement framework for sin- gle image dehazing. IEEE TIP, 30:3391–3404, 2021. [11] Boyun Li, Yuanbiao Gou, Shuhang Gu, Jerry Zitao Liu, Joey Tianyi Zhou, and Xi Peng. You only look yourself: Unsupervised and untrained single image dehazing neural net- work. IJCV, 129(5):1754–1767, 2021.
THE END
ABOUT
京东探索研究院
京东探索研究院(JD Explore Academy)秉承“以技术为本,致力于更高效和可持续的世界”的集团使命,是以京东集团以各事业群与业务单元的技术发展为基础,集合全集团资源和能力,成立的专注前沿科技探索的研发部门,是实现研究和协同创新的生态平台。探索研究院深耕泛人工智能3大领域,包括“量子机器学习”、“可信人工智能”、“超级深度学习”,从基础理论层面实现颠覆式创新,助力数智化产业发展及变革。以原创性科技赋能京东集团零售、物流、健康、科技等全产业链场景,打造源头性科技高地,实现从量变到质变的跨越式发展,引领行业砥砺前行。
京东探索研究院诚招勤于实践、勇于梦想的志同道合之士,包括正式员工或者实习生,方向包括但不限于:算法理论、深度学习、自动机器学习、自然语言处理、计算机视觉、多模态处理、量子机器学习等。



