贾佳亚等提出Fast Point R-CNN,利用点云快速高效检测3D目标
选自arXiv
作者:Yilun Chen、Shu Liu、Xiaoyong Shen、Jiaya Jia
机器之心编译
参与:韩放、一鸣
本文提出了一个统一、高效且有效的,基于点云的三维目标检测框架。其两阶段方法采用体素表示和原始点云数据并充分利用了它们的优势。第一阶段的网络,以体素表示为输入,只包含轻量卷积运算,产生少量高质量的初始预测。初始预测中每个点的坐标和索引卷积特征与注意机制有效融合,既保留了准确的定位信息,又保留了上下文信息。第二阶段研究内部点及其融合特征,以进一步完善预测。该方法在 KITTI 数据集上进行了评估,包括 3D 和鸟瞰图(BEV)检测,以 15FPS 的检测速率达到了最先进的水平。
 论文地址:
https://arxiv.org/abs/1908.02990v1
论文地址:
https://arxiv.org/abs/1908.02990v1
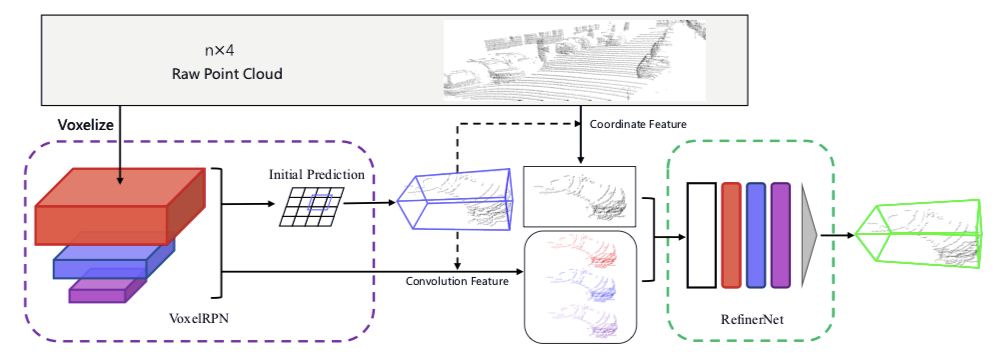
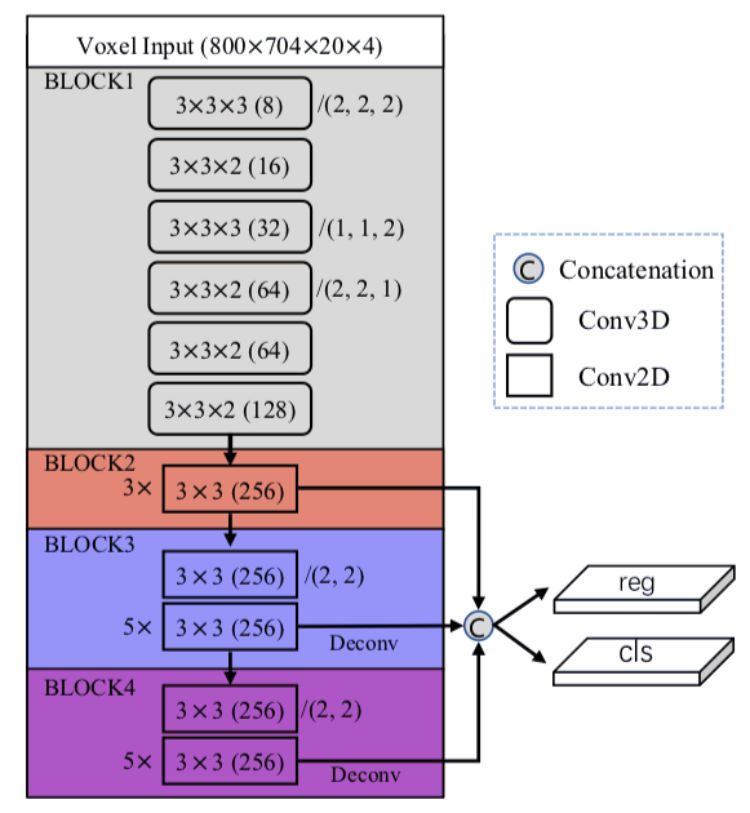
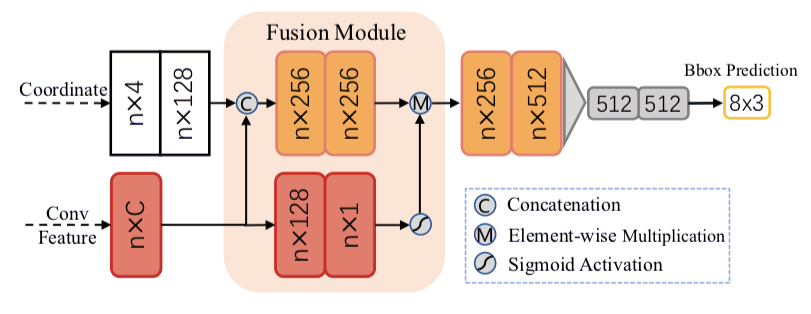
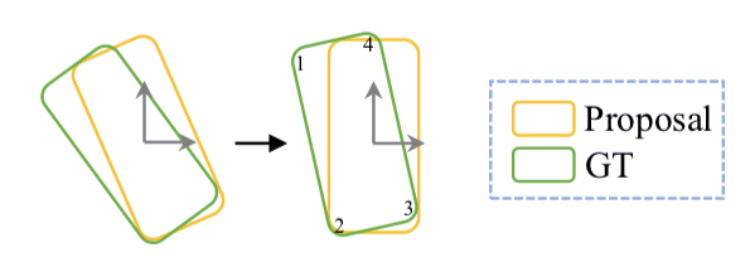
实验结果
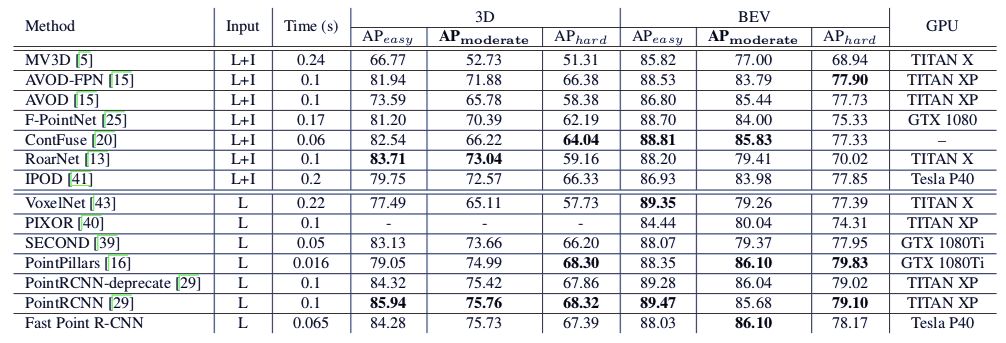
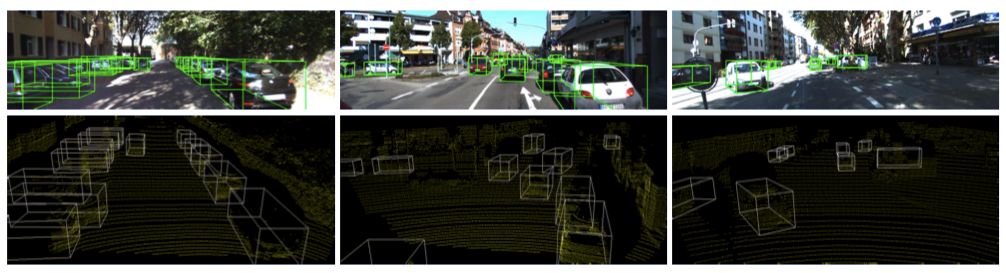
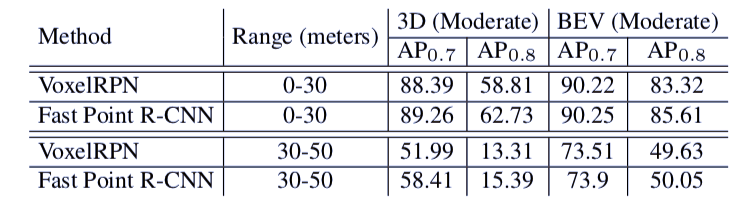
登录查看更多
相关内容

Arxiv
15+阅读 · 2020年3月31日
Arxiv
8+阅读 · 2018年2月21日


相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2020年3月31日
Arxiv
8+阅读 · 2018年2月21日