单语言表征如何迁移到多语言去?

作者 | 刘旺旺
编辑 | 唐里
论文:On the Cross-lingualTransferability of Monolingual Representations
单语言表征的跨语言可迁移性的研究
链接:https://arxiv.org/abs/1910.11856
代码:暂无

摘要
目前最先进的无监督多语言模型(如多语言BERT)已被证明可以在零样本的跨语言学习中具有通用性,这种效果主要是因为使用了共享的子词词典和多语言的联合训练。
这篇文章主要设计实验去评判上述的观点。
该文章设计一个方法,该方法在词汇层面将一个单语的语言模型迁移到另外一个新的语言上,该方法并不依赖字词词典和多语言联合训练的技巧,但是该方法在跨语言的评测上表现和多语言的bert(mbert)表现旗鼓相当。
文本还发布了一个新的评测数据集(XQuAD), 它是一个更全面的跨语言基准测试,包括由专业翻译人员翻译成十种语言的240段和1190对问题回答。
本文贡献
提出了一种以非监督方式将单语表示转换为新语言的方法。
证明了零样本迁移既不需要共享的子词词汇,也不需要联合的多语言训练。
发现每一种语言的有效词汇量是训练多语言语言模型的重要因素。
证明单语模型学习跨语言泛化的语义抽象。
提出了一个新的跨语言问题回答数据集。
背景
mbert在跨语言的任务上表现很不错,普遍认可因素有三个:
使用共享的词表;
在不同语言下进行联合训练;
深度的跨语言表征。
一定需要上述三个因素才能有一个好的模型去解决跨语言的任务吗?文本设计了方法进行了探究。
论文设计的方法
假设有两种语言L1和L2,L1既有大量无标签数据又有下游任务的监督数据,L2只有大量无标签数据,整个流程可分为一下四步:
在L1无标签的数据集上,训练一个单语的bert,任务为masked语言模型(MLM)和下一句话预测(NSP)。
冻结第1步训练好的bert中的transformer部分(embedding层和softmax层除外),在L2无标签的数据集上从头开始训练新的bert模型,任务同1。
使用L1下游任务的监督数据,微调第1步训练好的模型,微调的过程中冻结 embedding层。
使用第2步得到的embedding层替换第3步的embedding层,得到新的模型,可应用于L2中相同的下游任务。
实验
对比实验的主要的目的是对比不同的多语言模型在zero-shot 跨语言下语言理解能力。
对比的模型有:
Jointmultilingual models (JOINT MULTI) : 一个15种语言上联合训练的多语种BERT模型。这个模型类似于mBERT,与XLM等其他变体很相似。
Jointpairwise bilingual models (JOINT PAIR) :只在两种语言上(英语和另外一种语言)进行联合训练,这样主要是为了提高联合训练的效果。
Cross-lingualword embedding mappings (CLWE): 不同语言的词嵌入表征首先对齐到没剖一个单语词汇的空间,然后在此空间上学习多语言深度模型。
Cross-lingualtransfer of monolingual models (MONOTRANS):本文的方法 。
实验1:
将上述的模型按照在MultiNLI上进行训练,然后在XNLI数据集上进行测试:
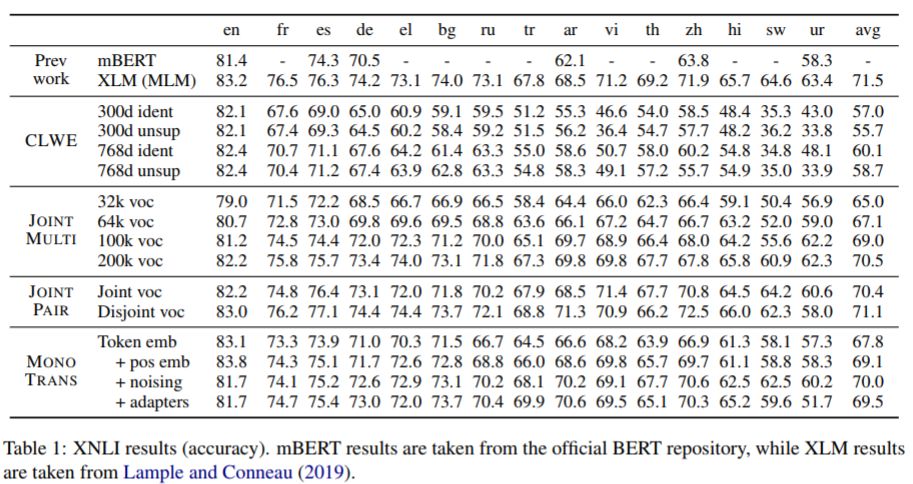
最好的JOINTMULTI模型明显优于mBERT,只有一个点差(平均)比无监督的XLM模型(规模更大)。
在测试的JOINTMULTI不同设置中,我们观察到使用更大的词汇量有显著的积极影响。
这表明对更多的语言建模不会影响学习表示的质量(在XNLI上评估)。
JOINT PAIR 一组中可以看出 联合训练中共享字词不需要。
CLWE表现不佳。即使它在英语上有竞争力,它也不能很好地转移到其他语言上。
实验2:
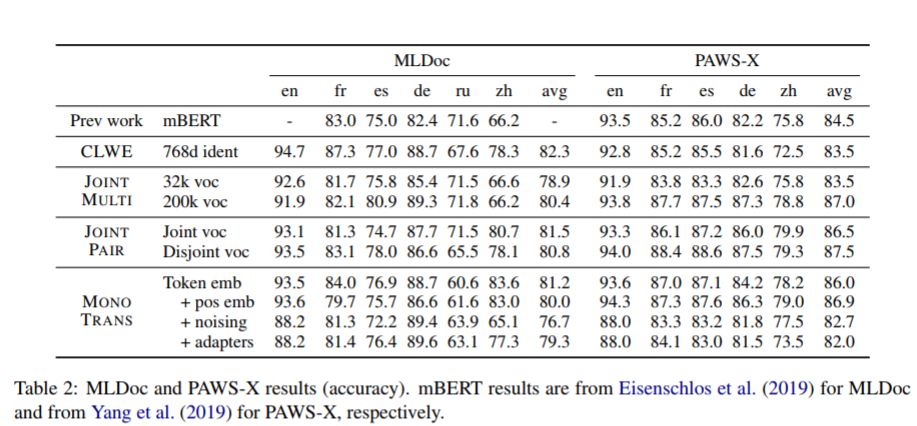
四种方法得到的结果跟相近,说明为了取得良好的成绩,不需要联合的多语言预培训和共享的词汇表 。
实验3
前面的测试数据集上发现,MONOTRANS与JOINTMULTI, JOINTPAIR 在上述测试集上表现都旗鼓相当,对这种行为的一个可能的假设是,现有的跨语基准是有缺陷的,在词汇层面上是可以解决的。
为了更好的理解这些模型的跨语言泛化能力,创建了一个新的评测数据集 XQuAD ,由240个段落和1190个来自于v1.17开发集的问答对组成,并将它们翻译成10种语言:西班牙语、德语、希腊语,俄语,土耳其语,阿拉伯语,越南语,泰国语、汉语和印度语。上下文段落和问题都是由来自Gengo的专业翻译人员翻译的。
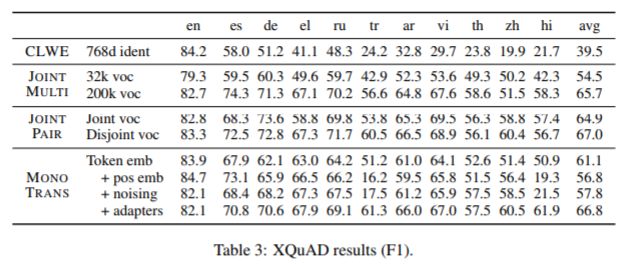
从表中可知MonoTRANS可以和联合训练的模型相媲美 。
论文结论
比较了目前最先进的多语言表征学习模型和在词汇水平上转移到新语言的单语模型。证明了这些模型在标准的零样本跨语迁移基准上的表现是相似的,这表明在多语言模型中既不需要共享词汇,也不需要联合的预训练。
在一系列的探究性实验中,还进一步证明了一个针对特定语言训练的单语模型可以学习一些可推广到其他语言的语义抽象。结果和分析与以前的一些理论相矛盾(多语言模型需要联合训练和共享词表),为多语言模型的泛化能力的基础提供了新的见解。为了提供一个更全面的基准来评估跨语言模型,发布了跨语言问题回答数据集(XQuAD)。