Facebook开源MUSE:多语言无监督和监督词向量库
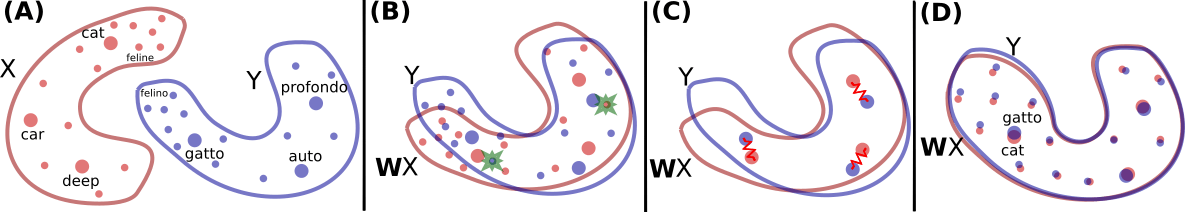
MUSE是一个多语言词向量Python库,它可提供:
基于fastText的最先进的多语言词向量;
可用于训练和评估的大规模高质量双语词典
我们包括了两种方法,其一是运用双语词典或相同字符串的监督向量,其二是不使用任何平行数据的无监督向量。
环境
搭载NumPy或SciPy的Python2/3
PyTorch
Faiss,快速实现最邻近搜索(推荐使用)
MUSE可在CPU或GPU上运行,支持Python2或3。如果在GPU上运行,Faiss不是必选项,虽然使用Faiss可以大大加快最邻近搜索速度。不过我们强烈建议CPU用户使用。Faiss可以使用“conda install faiss-cpu -c pytorch”或“conda install faiss-gpu -c pytorch”安装。
评估数据集
为了获取单一语种和多语言词向量评估数据集,需要:
Facebook的110种双语词典,下载地址:https://github.com/facebookresearch/MUSE#ground-truth-bilingual-dictionaries;
28个6种语言的词语相似度任务,以及英语单词的比喻任务;
SemEval2017跨语言词语相似度任务;
从Europarl语料库获得的句子译文。
只需在'data/'下运行:
./get_evaluation.sh
注意:此步骤需要bash 4。默认禁用了Europarl下载(因为速度很慢),可参考这里启用:https://github.com/facebookresearch/MUSE/blob/master/data/get_evaluation.sh#L99-L100。
获取单一语种词向量
对于预先训练的单语言词向量,我们强烈推荐使用fastText Wikipedia向量,或者用fastText从你自己的语料库中训练自己的词向量。
你可以用以下代码下载英语(en)和西班牙语(es)向量:
# English fastText Wikipedia embeddings
curl -Lo data/wiki.en.vec https://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.en.vec
# Spanish fastText Wikipedia embeddings
curl -Lo data/wiki.es.vec https://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.es.vec
连接单一语种词向量
为了得到跨语种词向量,该项目包含两种方法:
监督式:使用一个可训练的双语词典(或者相同的字符串作为定位点),使用Procrustes alignment进行迭代,学习从源语言到目标语言的映射。
无监督:没有任何平行数据或定位点,使用对抗训练和(迭代)Procrustes强化,学习从源语言到目标语言的映射。
监督式方法:Procrustes迭代(CPU|GPU)
学习从源语言到目标语言的映射,可运行以下代码:
python supervised.py --src_lang en --tgt_lang es --src_emb data/wiki.en.vec --tgt_emb data/wiki.es.vec --n_iter 5 --dico_train default
默认情况下,dicotrain会指向我们标记的词典(可在上方下载);当设置成为“identicalchar”,它将在源语言和目标语言之间使用相同的字符串来形成词汇表。日志和向量将被保存在dumped/目录中。
无监督方法:对抗训练和改进(CPU|GPU)
为了使用对抗训练和迭代Procrustes学习映射,可运行以下代码:
python unsupervised.py --src_lang en --tgt_lang es --src_emb data/wiki.en.vec --tgt_emb data/wiki.es.vec
默认情况下,validation值是利用CSLS构建的合成词典中单词对的平均余弦值。
评估单语言或跨语言词向量(CPU|GPU)
以下简单的脚本可以用来评估单语种或跨语种词向量在多重任务上的表现质量。
单语种:
python evaluate.py --src_lang en --src_emb data/wiki.en.vec --max_vocab 200000
多语种:
python evaluate.py --src_lang en --tgt_lang es --src_emb data/wiki.en-es.en.vec --tgt_emb data/wiki.en-es.es.vec --max_vocab 200000
GitHub地址:https://github.com/facebookresearch/MUSE





