跨语言版BERT:Facebook提出跨语言预训练模型XLM
选自 GitHub
机器之心编译
参与:张倩、思源
自去年 BERT 横空出世以来,预训练语言模型就得到大量的关注,但大多数预训练表征都是单语言的,不同语言的表征并没有什么关系。今天,Facebook 发布了一种新型跨语言预训练语言模型,它旨在构建一种跨语言编码器,从而将不同语言的句子在相同的嵌入空间中进行编码。这种共享的编码空间对机器翻译等任务有很大的优势。
项目地址:https://github.com/facebookresearch/XLM
在这一项工作中,作者展示了跨语言预训练语言模型的高效性,它在多种跨语言理解基准任务中都取得了很好的效果。总的而言,Facebook 提供的是一种跨语言版的 BERT,它在 XNLI 和无监督机器翻译等跨语言任务取得了当前最好的效果。
整个 XLM 开源项目主要展示了预训练语言模型和机器翻译等使用方法,如下所示为项目结构。
1. 预训练语言模型:
因果语言模型(CLM)—单语言
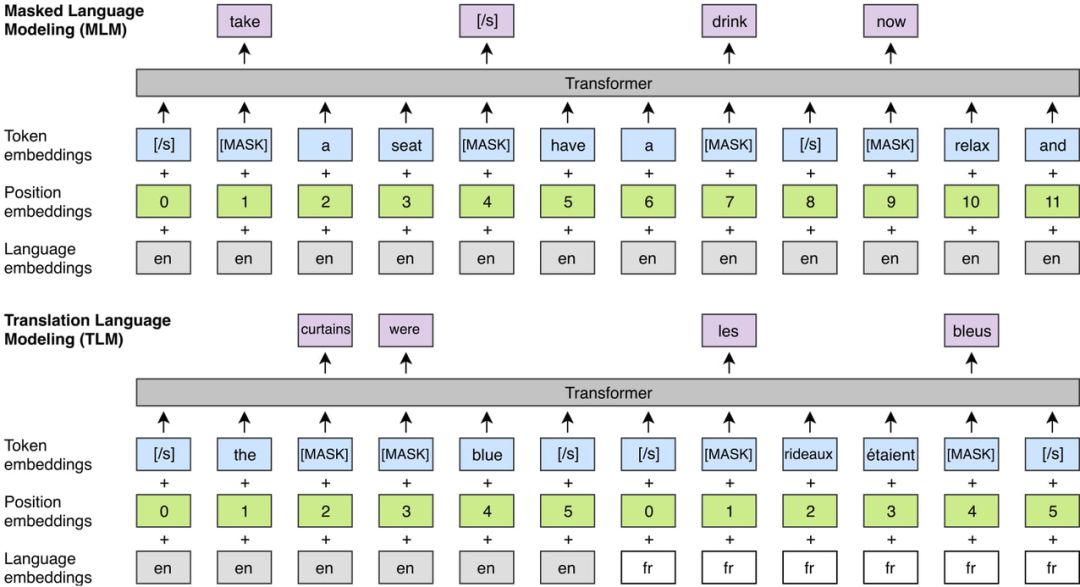
BERT 中通过掩码训练的语言模型(MLM)—单语言
翻译语言模型(TLM)—跨语言
2. 监督/无监督机器翻译训练:
降噪自编码器
平行数据训练
在线回译
3.XNLI 微调
4.GLUE 微调
此外,XLM 支持多 GPU 和多节点训练,这对于大规模重训练或微调都很有帮助。
预训练模型
本项目提供预训练跨语言模型,所有预训练模型都是利用 MLM 目标函数训练的:
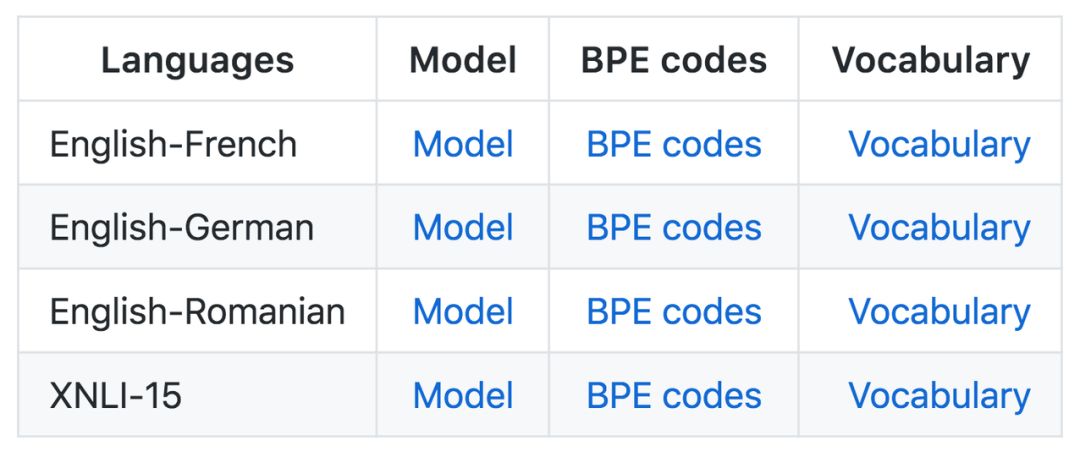
机器翻译预训练论文中用到的是英-法、英-德、英-罗马尼亚模型。如果要使用这些模型,需要使用相同的数据预处理/BPE 代码来预处理数据。
XNLI 微调用到的模型是 XNLI-15。它可以处理英语、法语、西班牙语、德语、希腊语、保加利亚语、俄语、土耳其语、阿拉伯语、越南语、泰国语、汉语、印地语、斯瓦希里语和乌尔都语。该模型的预处理方法不同于机器翻译模型。
生成跨语言句子表征
项目提供了一段简单的示例代码,它可以帮我们从预训练模型快速获取跨语言句子表征,这种跨语言的句子表征对机器翻译、计算句子相似性或实现跨语言的分类器都很有帮助。项目提供的示例主要是 Python 3 写的,它还需要 Numpy、PyTorch、fastBPE 和 Moses 四个库的支持。其中 fastBPE 主要帮助解决机器翻译中罕见词的表征问题,Moses 主要对文本进行清理和 Tokenize 等过程,这个库并不需要安装。
要生成跨语言的句子表征,首先需要导入一些代码文件和库:
import os
import torch
from src.utils import AttrDict
from src.data.dictionary import Dictionary, BOS_WORD, EOS_WORD, PAD_WORD, UNK_WORD, MASK_WORD
from src.model.transformer import TransformerModel
加载预训练模型:
model_path = '/private/home/guismay/aws/XLM/mlm_tlm_xnli15_1024.pth'
reloaded = torch.load(model_path)
params = AttrDict(reloaded['params'])
print("Supported languages: %s" % ", ".join(params.lang2id.keys()))
__________________________________________
Supported languages: ar, bg, de, el, en, es, fr, hi, ru, sw, th, tr, ur, vi, zh
构建字典、更新参数和构建模型:
# build dictionary / update parameters
dico = Dictionary(reloaded['dico_id2word'], reloaded['dico_word2id'], reloaded['dico_counts'])
params.n_words = len(dico)
params.bos_index = dico.index(BOS_WORD)
params.eos_index = dico.index(EOS_WORD)
params.pad_index = dico.index(PAD_WORD)
params.unk_index = dico.index(UNK_WORD)
params.mask_index = dico.index(MASK_WORD)
# build model / reload weights
model = TransformerModel(params, dico, True, True)
model.load_state_dict(reloaded['model'])
下面展示一些语言的案例,我们会根据预训练模型抽取句子表征,它们已经是 BPE 格式(基于 fastBPE 库):
# list of (sentences, lang)
sentences = [
('the following secon@@ dary charac@@ ters also appear in the nov@@ el .', 'en'),
('les zones rurales offr@@ ent de petites routes , a deux voies .', 'fr'),
('luego del cri@@ quet , esta el futbol , el sur@@ f , entre otros .', 'es'),
('am 18. august 1997 wurde der astero@@ id ( 76@@ 55 ) adam@@ ries nach ihm benannt .', 'de'),
('اصدرت عدة افلام وث@@ اي@@ قية عن حياة السيدة في@@ روز من بينها :', 'ar'),
('此外 , 松@@ 嫩 平原 上 还有 许多 小 湖泊 , 当地 俗@@ 称 为 “ 泡@@ 子 ” 。', 'zh'),
]
# add </s> sentence delimiters
sentences = [(('</s> %s </s>' % sent.strip()).split(), lang) for sent, lang in sentences]
最后创建批量并完成前向传播就能获得最终的句子嵌入向量:
bs = len(sentences)
slen = max([len(sent) for sent, _ in sentences])
word_ids = torch.LongTensor(slen, bs).fill_(params.pad_index)
for i in range(len(sentences)):
sent = torch.LongTensor([dico.index(w) for w in sentences[i][0]])
word_ids[:len(sent), i] = sent
lengths = torch.LongTensor([len(sent) for sent, _ in sentences])
langs = torch.LongTensor([params.lang2id[lang] for _, lang in sentences]).unsqueeze(0).expand(slen, bs)
tensor = model('fwd', x=word_ids, lengths=lengths, langs=langs, causal=False).contiguous()
print(tensor.size())
最后输出的张量形状为 (sequence_length, batch_size, model_dimension),它可以进行进一步的微调,从而完成 GLUE 中的 11 项 NLP 任务或 XNLI 任务等。
当然除了提取预训练句子嵌入向量,该项目还展示了如何用于无监督机器翻译等任务,详细内容可查阅原 GitHub 项目。
论文:Cross-lingual Language Model Pretraining

论文链接:https://arxiv.org/abs/1901.07291
摘要:最近的研究已经展示了生成预训练在英语自然语言理解上的有效性。本研究将此方法扩展到多种语言并展示了跨语言预训练的有效性。研究者提出了两种方法,用于学习跨语言模型(XLM):一个是无监督模型,只依赖单语数据,另一个是有监督模型,利用具有新的跨语言模型目标函数的平行数据。该方法在跨语言分类、无监督和有监督机器翻译方面达到了当前最佳水准。在 XNLI 上,该方法将当前最高绝对准确率提高了 4.9%。在无监督机器翻译上,本研究中的方法在 WMT'16 德语-英语任务上的 BLEU 到达了 34.3,将当前最佳水平提高了 9 分。在有监督机器翻译任务中,该方法在 WMT'16 罗马尼亚语-英语任务中的 BLEU 达到 38.5,将当前最佳水平提高了 4 分。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com