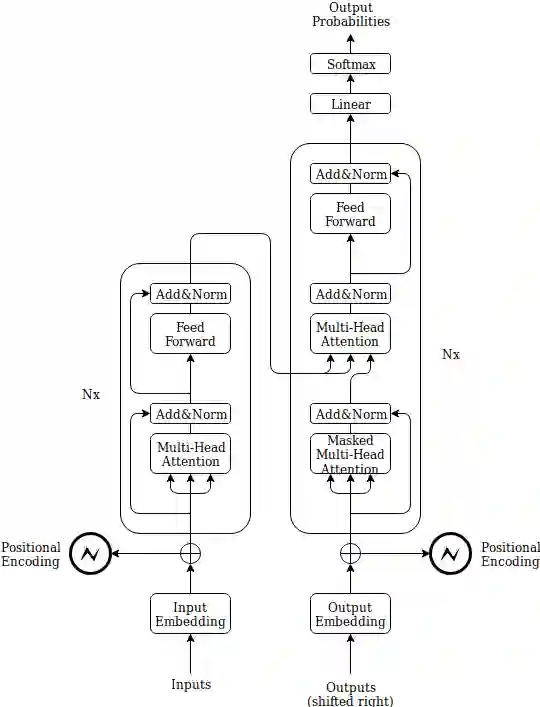
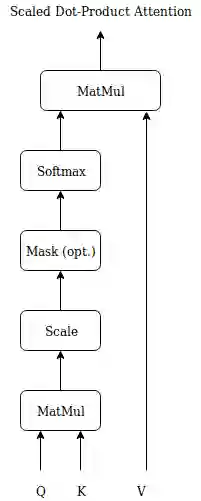
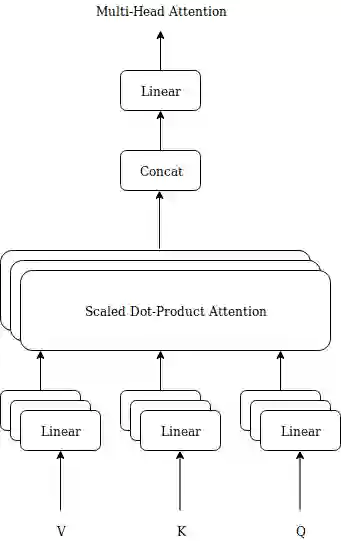
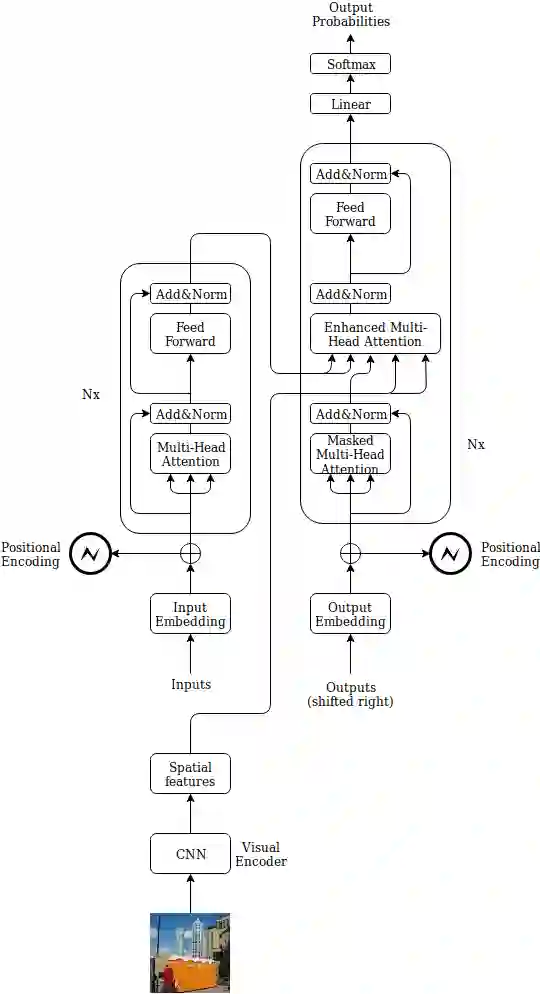
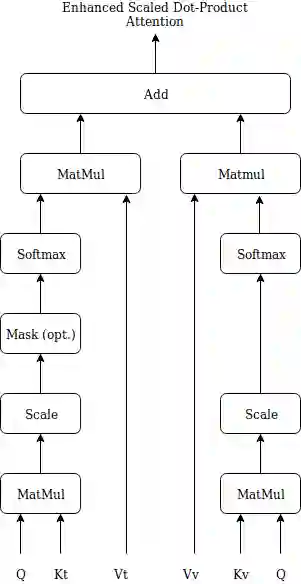
In this paper a doubly attentive transformer machine translation model (DATNMT) is presented in which a doubly-attentive transformer decoder normally joins spatial visual features obtained via pretrained convolutional neural networks, conquering any gap between image captioning and translation. In this framework, the transformer decoder figures out how to take care of source-language words and parts of an image freely by methods for two separate attention components in an Enhanced Multi-Head Attention Layer of doubly attentive transformer, as it generates words in the target language. We find that the proposed model can effectively exploit not just the scarce multimodal machine translation data, but also large general-domain text-only machine translation corpora, or image-text image captioning corpora. The experimental results show that the proposed doubly-attentive transformer-decoder performs better than a single-decoder transformer model, and gives the state-of-the-art results in the English-German multimodal machine translation task.
翻译:在本文中,演示了一种加倍注意的变压器机器翻译模型(DATNMT),在这种模型中,二倍注意的变压器解码器通常结合通过预先训练的神经神经网络获得的空间视觉特征,征服图像字幕和翻译之间的任何差距。在这个框架中,变压器解码器通过一个双倍注意的变压器的强化多层中两个单独的注意组件的方法,可以自由地处理源词和图像的一部分,因为它生成了目标语言中的文字。我们发现,拟议的模型不仅能够有效地利用稀缺的多式机器翻译数据,而且能够有效地利用大型通用的只读文本机器翻译体,或图像文字字幕字幕说明体。实验结果显示,拟议的双倍注意变压器脱码器比单分解变压器变压器模型的功能要好,并且给英德模式机器翻译任务带来最先进的结果。