
题目: 自然语言处理中的表示学习进展:从Transfomer到BERT
报告人: 邱锡鹏 博士 复旦大学
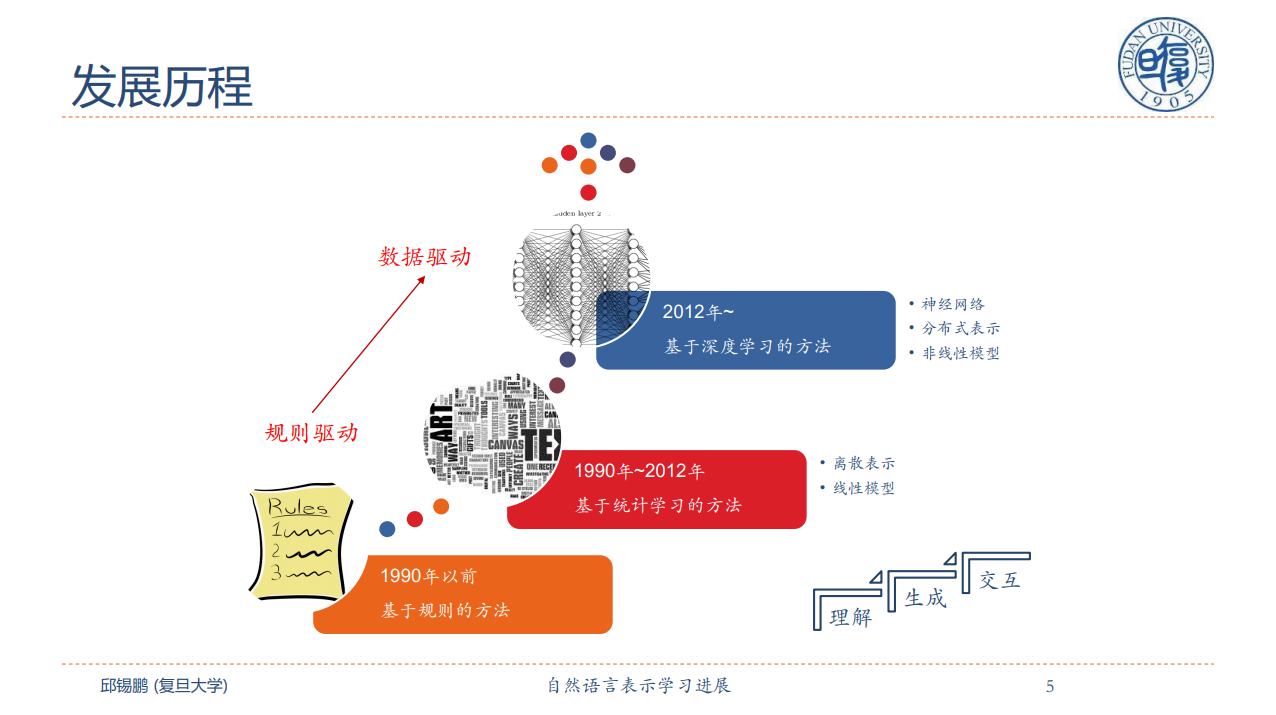
摘要: 目前全连接自注意力模型(比如Transformer)在自然语言处理领域取得了广泛的成功。本报告主要介绍我们在自注意力模型方面的一些工作,主要涵盖两部分内容:1)Transformer及其改进模型:通过分析Transformer的基本原理和优缺点,提出一些改进模型Star-Transformer、Multi-Scale Transformer等。2)预训练的Transformer模型的迁移方法:虽然预训练的Transformer模型(比如BERT、GPT等)在很多自然语言任务上都取得了非常好的性能,我们通过任务转换、继续预训练、多任务学习等方法来进一步提高其迁移能力。最后,对Transformer模型及其未来发展趋势进行展望。
成为VIP会员查看完整内容

相关内容

Arxiv
4+阅读 · 2019年9月11日
Arxiv
15+阅读 · 2018年10月11日
相关主题




相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年9月11日
Arxiv
15+阅读 · 2018年10月11日