
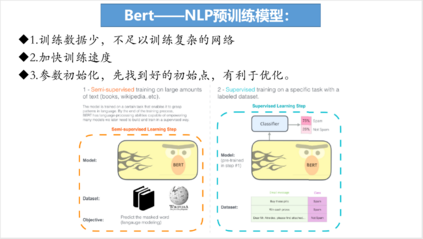
内容简介: 采用NLP预训练模型Bert的训练数据如果少的话,那么不足以训练复杂的网络;并且如果采用bert进行预训练则可以加快训练的速度;在运用预训练时,首先对参数进行初始化,找到一个好的初始点,那么对后续的优化将会产生巨大的影响。
说到利用深度学习来进行自然语言处理,必然绕不开的一个问题就是“Word Embedding”也 就是将词转换为计算机能够处理的向量,随之而来的人们也碰到到了一个根本性的问题,我们通常会面临这样的一个问题,同一个单词在不同语 境中的一词多义问题,研究人员对此也想到了对应的解决方案,例如在大语料上训练语境表示,从而得到不同的上下文情况的 不同向量表示。
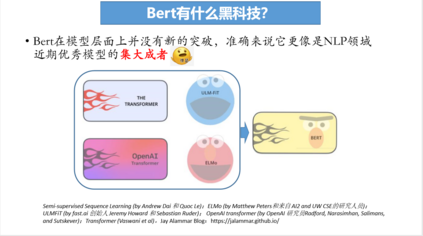
Bert在模型层面上并没有新的突破,准确来说它更像是NLP领域 近期优秀模型的集大成者,Bert相比其他神经网络模型,同时具备了特征提取能力与语境表达能力,这是其他比如OPEN AI与ELMo所不能达到的。为了解决双向编码器循环过程中出现的间接“窥见”自己的问题,Bert采用了一个masked语言模型,将其他模型的思想恰到好处的融合起来了。
成为VIP会员查看完整内容


相关内容

专知会员服务
78+阅读 · 2020年5月31日
专知会员服务
85+阅读 · 2020年1月15日
Arxiv
4+阅读 · 2019年9月11日
Arxiv
15+阅读 · 2018年10月11日




相关VIP内容
专知会员服务
78+阅读 · 2020年5月31日
专知会员服务
85+阅读 · 2020年1月15日
相关资讯
相关论文
Arxiv
4+阅读 · 2019年9月11日
Arxiv
15+阅读 · 2018年10月11日