
随着技术的传播,世界各地的人们比以往任何时候都更加紧密地联系在一起,无缝沟通和理解的需求变得至关重要。根据Simons 2018年的研究,世界上现存的语言有7097种。然而,语料中,大多数成对的语言最多有几百到几千个平行的句子,而且成对的语言数量有限。由于统计机器翻译(SMT)和神经机器翻译(NMT)都是需要大量数据的机器学习方法,因此缺乏数据是训练合适机器翻译(MT)系统的一个严重问题。
Tom Kocmi的博士论文《Exploring Benefits of Transfer Learning in Neural Machine Translation》(《探索迁移学习在神经机器翻译中的益处》)提出相关的迁移学习技术,并提供了详细地分析。论文展示了几种利用基于大量资源语言对训练的模型来提升少量资源情况下的模型训练。在分析过程中,作者发现:
- 迁移学习同时适用于少量资源和大量资源的语言对,并且比随机初始化训练的性能更好。
- 迁移学习在神经机器翻译中没有其他领域所知的负面影响,可以作为神经机器翻译实验的初始化方法。
- 结果表明,在迁移学习中,平行语料库的数量比语言对的相关性更重要。
- 作者观察到,迁移学习是一种更好的初始化技术,即使两个模型面向的语言没有交集,性能也能得到提升。
除了上述主要的贡献,论文也描述其他几个研究的想法,包括作者对Czech-English平行语料库的贡献(Bojar et al., 2016a)、使用预训练词嵌入的实验(Kocmi and Bojar, 2017c)、使用子词信息的词嵌入(Kocmi and Bojar, 2016)、神经语言识别工具(Kocmi and Bojar, 2017b)。另外,作者还为一个sequence-to-sequence的研究框架Nerual Monkey(Helcl et al., 2018)的实现做了贡献。
博士论文《Exploring Benefits of Transfer Learning in Neural Machine Translation》的内容大致如下:
- 简介
- 贡献
- 论文结构
- 背景
- 语言资源
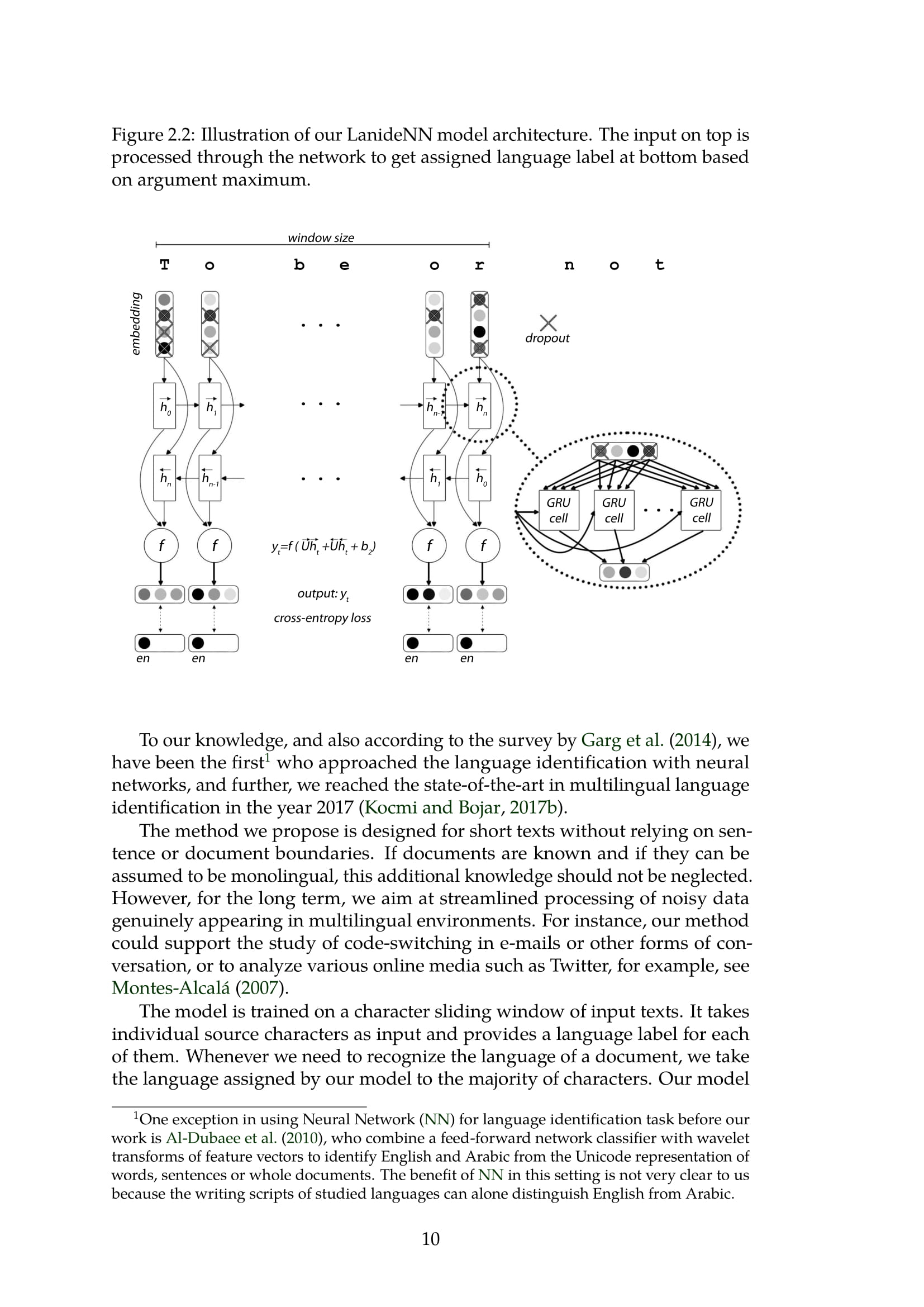
- LanideNN:语言识别工具
- 训练数据
- 机器翻译评价
- 神经机器翻译
- 词嵌入
- 子词表示
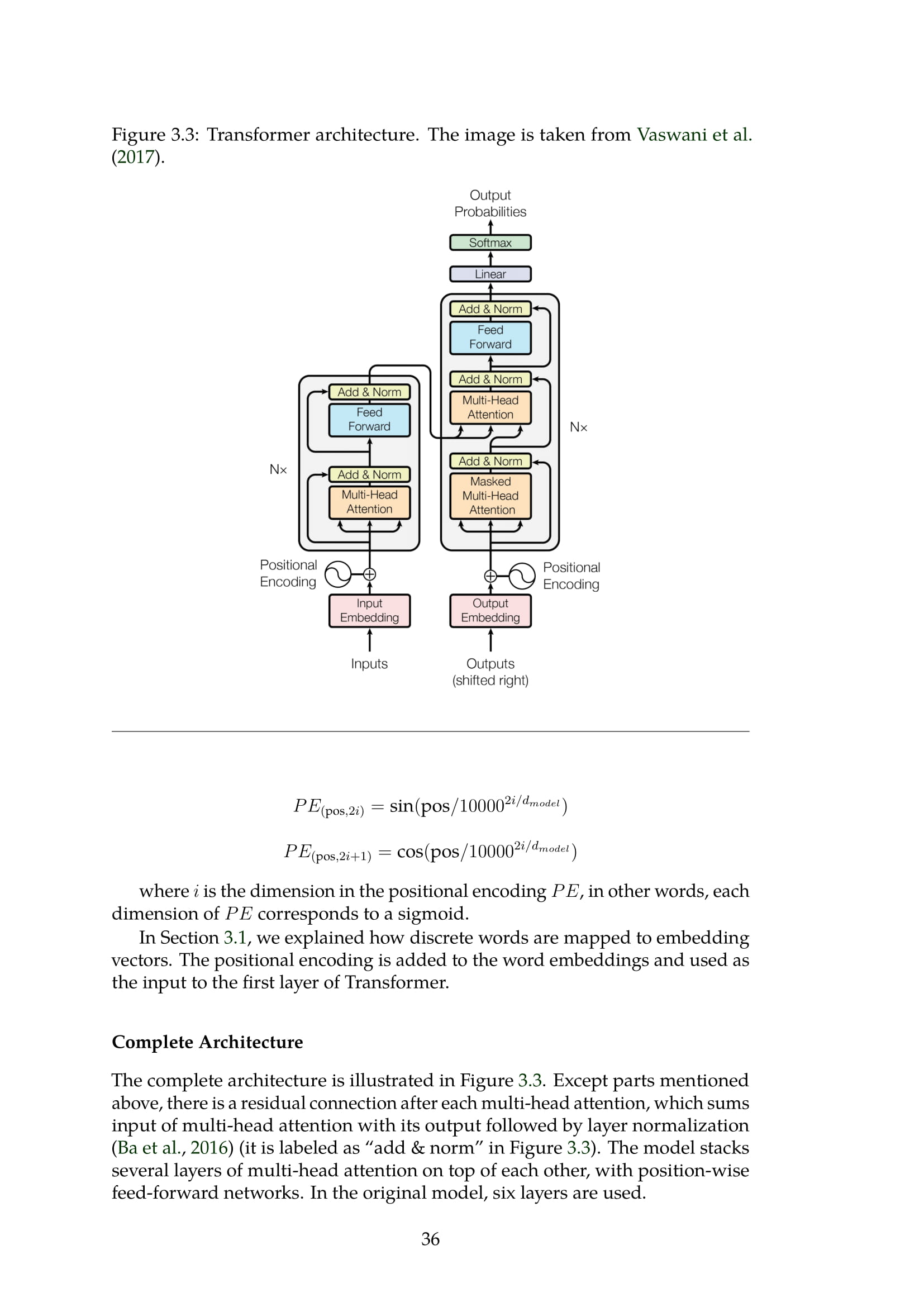
- 神经机器翻译架构
- 神经机器翻译模型设置
- 度量训练过程
- 迁移学习
- 术语
- 域适应
- 迁移学习
- 冷启动迁移学习
- 冷启动直系迁移
- 冷启动词汇变换
- 热启动迁移学习
- 热启动和冷启动对比
- 相关工作
- 总结
- 分析
- 负迁移
- 共享语言的位置是否影响迁移学习
- 语言相关性和数据量
- 语言特征和更好的初始化
- 迁移学习分析汇总
- 案例:反翻译迁移学习
- 总结
- 生态追踪
- 结束语

成为VIP会员查看完整内容



相关内容

迁移学习(Transfer Learning)是一种机器学习方法,是把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。迁移学习(TL)是机器学习(ML)中的一个研究问题,着重于存储在解决一个问题时获得的知识并将其应用于另一个但相关的问题。例如,在学习识别汽车时获得的知识可以在尝试识别卡车时应用。尽管这两个领域之间的正式联系是有限的,但这一领域的研究与心理学文献关于学习转移的悠久历史有关。从实践的角度来看,为学习新任务而重用或转移先前学习的任务中的信息可能会显着提高强化学习代理的样本效率。
专知会员服务
140+阅读 · 2020年7月10日
专知会员服务
19+阅读 · 2020年4月25日

相关VIP内容
专知会员服务
140+阅读 · 2020年7月10日
专知会员服务
19+阅读 · 2020年4月25日
相关资讯