BAM!利用知识蒸馏和多任务学习构建的通用语言模型
选自Openreview
机器之心编译
自 BERT 崛起以来,语言模型的预训练任务就被推至研究前沿,很多研究者都尝试构建更高效的通用自然语言理解模型。在这篇论文中,作者提出结合多任务学习与 BERT,从而在 11 项 NLP 任务上都获得极好的效果。
在今年年初,微软发布了一个多任务自然语言理解模型,它在通用语言理解评估基准 GLUE 上取得了当时最好的效果:11 项 NLP 基准任务中有 9 项超过了 BERT。至此,各种 NLP 预训练方法都被提了出来,GLUE 基准也出现越来越多的新研究。
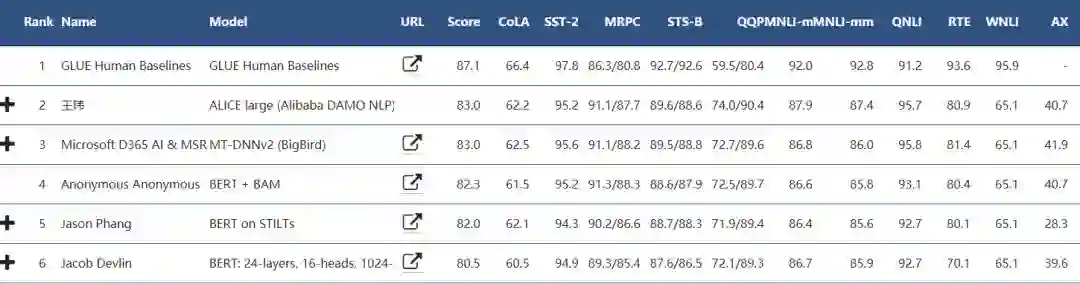
如下所示为目前 GLUE 基准的排名,Jacob 等人提出的原版 BERT 引发了一系列后续研究与改进,其中 BERT+BAM 的模型就是本文介绍的方法。
在 BAM + BERT 的这篇论文中,作者表示构建能够执行多个任务的单个模型一直是 NLP 领域的难题。多任务 NLP 对很多应用而言是无效的,多任务模型通常比单任务模型性能差。但是该研究提出利用知识蒸馏方法,让单任务模型高效教导多任务模型,从而在不同单任务上都有很好的表现。
知识蒸馏与 BERT
知识蒸馏即将知识从「教师」模型迁移到「学生」模型,执行方式为训练学生模型模仿教师模型的预测。在「born-again network」(Furlanello et al., 2018) 中,教师和学生具备同样的神经网络架构和模型大小,然而令人惊讶的是,学生网络的性能超越了教师网络。该研究将这一想法扩展到多任务模型训练环境中。
研究者使用多个变体对比 Single→Multi born-again 知识蒸馏,这些变体包括单模型到单模型的知识蒸馏和多任务模型到多任务模型的知识蒸馏。此外,该研究还提出了一个简单的教师退火(teacher annealing)方法,帮助学生模型超越教师模型,大幅改善预测结果。
如下所示为整体模型的结构,其采用多个任务的单模型与对应标签作为输入。其中多任务模型主要基于 BERT,因此该多任务模型能通过知识蒸馏学习到各单任务模型的语言知识。模型会有一个教师退火的过程,即最开始由多个单任务模型教多任务模型学习,而随着训练的进行,多任务模型将更多使用真实任务标签进行训练。
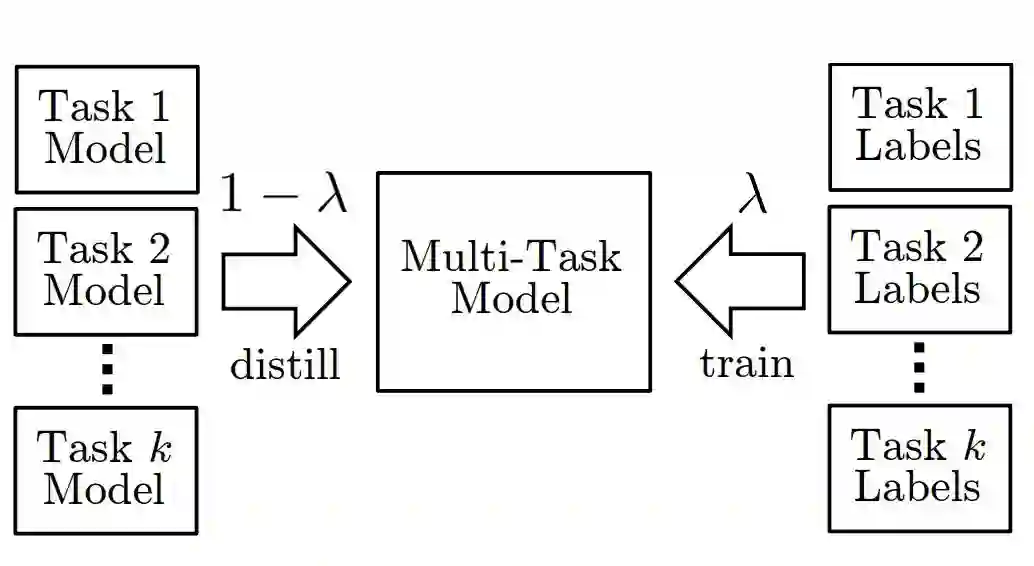
图 1:该研究提出方法概览。λ 在训练过程中从 0 线性增加到 1。
研究者在 GLUE 自然语言处理基准任务上使用无监督预训练环境 (Dai and Le, 2015; Peters et al., 2018) 和多任务精调 BERT 对该方法进行了实验评估。该研究提出的训练方法 Born-Again Multi-tasking (BAM) 持续优于标准单任务和多任务训练,在 GLUE 基准上获得了当前最优准确率。后续的分析证明多任务模型受益于更好的正则化和相关任务之间的知识迁移。
论文:BAM! Born-Again Multi-Task Networks for Natural Language Understanding

论文链接:https://openreview.net/forum?id=SylnYlqKw4
摘要:训练性能匹配甚至优于单任务设置的多任务神经网络是很有挑战性的。为了解决这个问题,该研究提出使用知识蒸馏,即用单任务模型教多任务模型。研究者使用 teacher annealing 来增强这一训练过程,teacher annealing 是一种新型方法,它将模型从知识蒸馏逐渐转换为监督学习,帮助多任务模型超越担任其老师的单任务模型。研究者在 GLUE 基准上使用多任务精调 BERT 评估了该方法。实验结果表明该研究提出的方法显著优于标准单任务和多任务训练,获得了当前最优准确率。
方法
如前所述,BAM 主要结合了 BERT 与多任务学习,且其中多任务学习最开始通过知识蒸馏的方式进行学习,再慢慢转为通过真实标签的有监督学习。一言以蔽之,BAM 方法主要可以分为多任务学习与知识蒸馏。
多任务训练
模型:该研究所有模型均基于 BERT 构建。该模型将 byte-pair-tokenized 的输入句子传输到 Transformer 网络,为每个 token 生成语境化的表征。对于分类任务,研究者使用标准 softmax 层直接分类。对于回归任务,研究者使用最后一层的特征向量,并使用 sigmoid 激活函数。在该研究开发的多任务模型中,除了基于 BERT 的分类器,所有模型参数在所有任务上共享,这意味着不到 0.01% 的参数是任务特定的。和 BERT 一样,字符级词嵌入和 Transformer 使用「masked LM」预训练阶段的权重进行初始化。
训练:单任务训练按照 Devlin 等人 (2018) 的研究来执行。至于多任务训练,研究者将打乱不同任务的顺序,即使在小批量内也会进行 shuffle。最后模型的训练为最小化所有任务上的(未加权)损失和。
知识蒸馏
该研究使用知识蒸馏方法,让单任务模型来教多任务模型。这里学生网络和教师网络具备同样的模型架构。
知识蒸馏中学生网络要模仿教师网络,这有可能导致学生网络受限于教师网络的性能,无法超过教师网络。为了解决该问题,该研究提出 teacher annealing,在训练过程中混合教师预测和 gold label。
实验
数据:研究人员使用 GLUE 基准(Wang 等人,2019 年)的 9 种自然语言理解任务上进行实验,包括文本蕴涵(RTE 和 MNLI)、问答蕴涵(QNLI)、释义(MRPC)、问题释义(QQP)、文本相似度(STS)、情感分类(SST2)、语言可接受性语料库(CoLA)和威诺格拉德模式(WNLI)等。
训练细节:研究人员并没有简单地对多任务模型的数据集进行 shuffle,而是遵循 Bowman 等人(2018 年)的任务抽样流程。这保证了超大数据集任务不会过度主导训练。研究人员还采用 Howard 和 Ruder(2018 年)的层级学习率技巧。
超参数:对于单任务模型而言,除在每一任务的开发集上将层级学习率 α 设置为 1.0 或 0.9 外,研究人员使用与原始 BERT 实验相同的超参数。对于多任务模型而言,研究人员训练模型的时间更长(6 个 epoch 而不是 3 个),批量更大(128 代替 32),并且使用 α = 0.9 以及 1e-4 的学习率。所有模型使用 BERT-Large 模型的预训练权重。
实验结果:开发集上的结果报告了所有 GLUE 任务(除 WNLI 之外)的平均分。所有结果都是至少 20 次使用不同随机种子的试验的中位数。研究人员发现有必要进行大量实验,因为在不同的运行下实验结果有显著差异。例如,多任务模型下 CoLA、RTE 和 MRPC 的分数标准差均超过 ±1,单任务模型下的标准差甚至更大。
结果
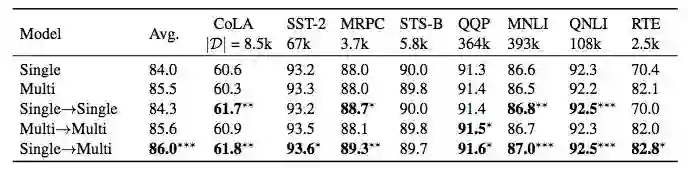
表 1:在 GLUE 开发集上对比不同方法。根据 bootstrap hypothesis test,∗、∗∗ 和 ∗∗∗ 表明单任务和多任务模型都有显著改善(分别是 p < .05、p < .01 和 p < .001)。
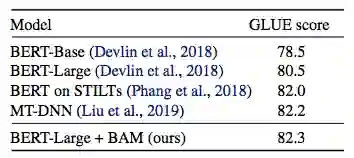
表 2:测试集结果对比。

表 3:模型简化测试。根据曼-惠特尼 U 检验(Mann-Whitney U test),Single→Multi 之间的差距显著 (p < .001)。

表 4:哪些任务组合有助于 RTE 分数?根据曼-惠特尼 U 检验,每对任务之间的差距显著 (p < .01)。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


