NAACL 2019自然语言处理亮点
【导读】NAACL是自然语言处理领域的顶会,今年NAACL于6月2日至7日于Minneapolis,MN 召开,本文梳理了NAACL2019的亮点。
作者| Sebastian Ruder
NAACL2019最吸引作者的是迁移学习,常识推理,自然语言生成、偏差、非英语。
迁移学习
研究者对迁移学习的兴趣仍然很高。 NAACL 2019授予BERT最佳长篇论文奖,可以说是最具影响力的近期迁移学习方法。尽管它很近,但会议论文已经利用BERT进行基于方面的情感分析,阅阅读理解,常识推理和开放域问题回答。
在RepEval研讨会上,Kristina Toutanova讨论了如何将迁移学习用于开放域问答。通过使用Inverse Cloze Task进行适当的预训练,可以在QA对上直接微调检索器和阅读器,而无需中间IR系统。这表明仔细初始化+微调是迁移学习的两个关键因素,即使在具有挑战性的任务上也能工作。过去也已经证明这可以用于学习跨语言嵌入和无监督机器翻译。她还指出,单矢量句子/段落表示对于检索非常有用 - 我们应该继续研究它们。总体而言,NLP中的迁移学习有许多令人兴奋的研究方向。其他亮点包括:
Single-step Auxiliary loss Transfer Learning,一种“令人尴尬的简单”方法,通过多任务学习降低ULMFiT的一些复杂性,并以指数方式衰减辅助损失。
AutoSeM一个用于多任务学习的两阶段管道,利用多臂强盗和贝叶斯优化分别学习最佳辅助任务和最佳任务混合比。
对16个任务的情境表征的评估表明它们不善于捕获细粒度的语言知识,RNN中的更高层比Transformer更具有任务特异性。
常识推理
语言建模是一项预训练任务,已被证明可以大规模地学习有用的表示。 然而,有些语言很少被用到,就算语料库再大。 克服这种偏差是使语言模型适应更复杂任务的关键挑战。 为了用通常没有说明的知识来测试推理,最好的资源论文使用常识知识库ConceptNet作为“种子”。 他们创建了CommonsenseQA,这是一个多选题的数据集,其中大多数答案与目标概念具有相同的关系(见下文)。

这要求模型使用常识而不仅仅是关系或共现信息来回答问题。 BERT在该数据集上的准确率达到了55.9% - 估计在10万例的情况下达到75%左右 - 仍远低于人类表现88.9%。到达88.9%需要什么?最有可能是结构化知识,互动和多模态学习。在视觉与语言缺陷研讨会(SiLV)上的讲话中,Yoav Artzi讨论了基础自然语言理解中的语言多样性,并指出我们需要从合成图像转向更逼真的图像以学习基础表示。
自然语言理解的另一个先决条件是组合推理。深度学习自然语言推理教程讨论了自然语言推理,这是一种深入评估这种推理形式的通用基准。我特别喜欢以下论文:
A label consistency framework for procedural text comprehension,鼓励预测与同一过程的描述之间的一致性。这是一种使用直觉和其他数据将归纳偏差纳入模型的巧妙方法。
Discrete Reasoning Over the content of Paragraphs,它要求模型解析问题中的引用并对文本中的多个指示对象执行离散操作(例如,添加,计数,排序)。
自然语言生成
在NeuralGen研讨会上,Graham Neubig讨论了直接优化不可微分的目标函数(如BLEU)的方法,包括最小风险训练和强化学习以及处理其不稳定性并使其工作的技巧。虽然我们在教程中谈到了自然语言生成(NLG)的迁移学习,但Sasha Rush提供了更多细节,并讨论了使用语言模型来提高NLG质量的不同方法。提高样本质量的另一种方法是专注于解码。 Yejin Choi讨论了一种新的采样方法,该方法从分布头部进行采样,从而提高文本质量。她还讨论了假新闻的产生以及Grover等大型预训练语言模型如何用来防御它们。
生成对抗网络(GAN)是一种生成图像的流行方式,但到目前为止,语言表现不佳。 NLP深度对抗性学习指南认为我们不应该放弃它们,因为GAN所做的无监督或自我监督的学习在NLP中有很多应用。
生成的另一个引人注目的方面是使多个代理能够有效地进行通信。除了提供语言如何出现的窗口之外,可能有必要进行交互式学习并在代理之间传递知识。此外,将新兴语言与自然语言联系起来仍然很困难。
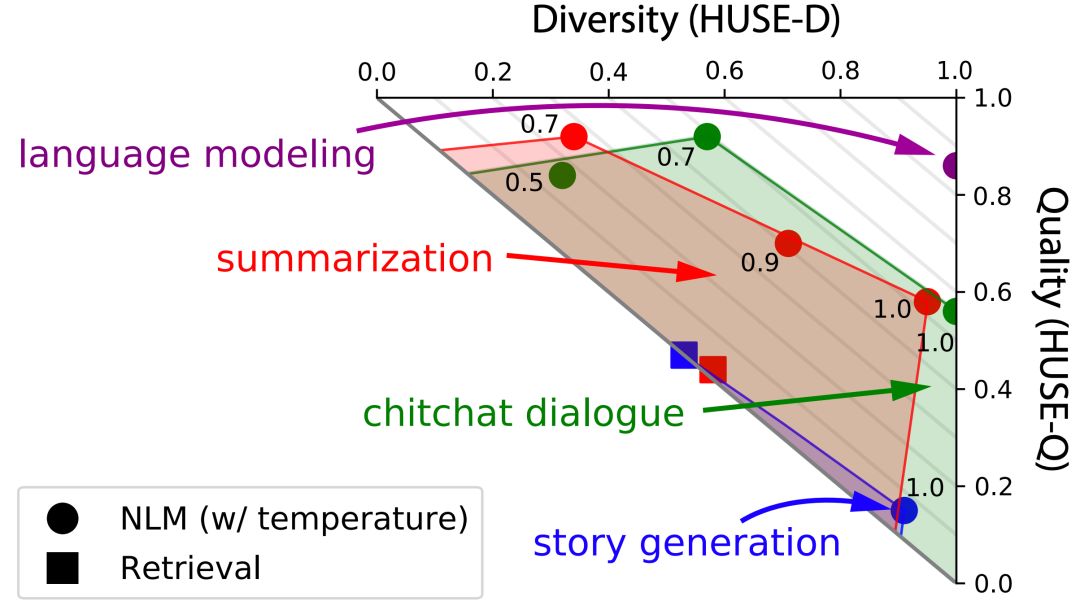
此外,吸引人的亮点还有:
Human Unified with Statistical Evaluation 人类与统计评估统一,一种新的自然语言生成度量,可以考虑多样性和质量.
Separating planning from realization 可以提高结构化数据(如RDF三元组)生成文本的质量,因为通常有多种方式可以在文本中实现结构化信息。
Decoupling syntax and surface form generation是处理结构化数据中文本生成的未指定问题的另一种方法(在这种情况下,抽象意义表示)。
A systematic analysis that probes how useful the visual modality actually is for multimodal translation 并获得了最佳短篇论文奖。它观察到,与当前信念相反,具有较少文本信息的模型更强烈地依赖于视觉上下文。
偏差
会议的主题是模型偏差。各种主题演讲非常适合这一主题。 Arvind Narayanan的第一个主题演讲特别突出了一个未被充分认识的偏差方面,即我们可以利用模型中的偏差来提高我们对人类文化的理解。
总的来说,在理想偏好和不良偏差之间存在细微差别。我们经常尝试编码关于世界如何运作的归纳偏见,例如对象对翻译不变。另一方面,我们不希望我们的模型学习表面暗示或关系,这些暗示或关系不属于我们可能理想化的世界观,如性别偏见。最终,超人类的表现不仅仅意味着模型能够定量地超越人类,而且还会减少他们的偏见和错误。
最后,我们应该意识到技术在现实世界中具有持久的影响。作为一个生动的例子,Kieran Snyder在她的主题演讲中叙述了她为Sinhala设计排序算法的时间,为了使斯里兰卡政府能够在2004年海啸之后搜寻幸存者,必须对僧伽罗语名称进行排序。她决定如何将语言按字母顺序划分,后来成为官方政府政策的一部分。
其他亮点:
Debiasing methods only superficially remove bias in word embeddings;偏差仍然反映在 - 并且可以从去除的嵌入中的距离中恢复。
An evaluation of bias in contextualized word embeddings发现,ELMo在语法上和不平等地编码性别信息,更重要的是,这种偏见是由下游模型继承的。
非英语
关于不同语言的主题,在会议期间,以“Emily Bender”命名的“弯曲规则”以她的倡导多语言语言处理而闻名于世,经常在演讲之后被引用。简而言之,该规则规定:“始终命名您正在处理的语言。”没有明确指出所考虑的语言会导致英语被视为默认语言并被视为其他语言的代理,这在许多方面都存在问题。
在这方面,一些论文调查了我们的模型在应用于其他语言时的表现如何变化:
Polyglot contextual representations 通过使用跨语言表示初始化单词嵌入来训练英语和其他语言的多语言上下文表示。对于某些设置(中文SRL,阿拉伯语NER),跨语言训练会产生很大的改进。
A study on transfer of dependency parsers trained on English to 30 other languages 关于将英语训练的依赖性解析器转移到其他30种语言的研究发现,受过英语训练的RNN很好地转移到接近英语的语言,但自我关注模型更好地转移到远程语言。
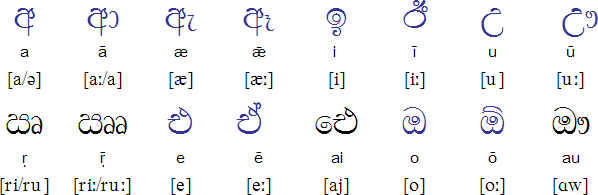
An unsupervised POS tagger for low-resource languages用 于低资源语言(Cardenas等人)的无监督POS标记器,用于“解密”Brown簇ID以生成POS序列并在僧伽罗语上实现最先进的性能(见上文)。
原文链接:
http://ruder.io/naacl2019/
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!550+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




