论文浅尝 | 面向自动问题生成的跨语言训练
论文笔记整理:谭亦鸣,东南大学博士生,研究方向为跨语言知识图谱问答。

来源:ACL 2019
链接:https://128.84.21.199/pdf/1906.02525.pdf
动机
现有问题生成方法需要大量的“文本-问题”有标注数据对作为训练数据集,对于小语种语言(或缺少有标注数据的语言),有标注数据的缺少是无法实现高质量问题生成的主要原因。从上述因素出发,作者的动机是:利用已有大规模标注数据集(例如英文问题生成数据集,文中描述为 secondary language),用于提升小语种(文中称为 primary language)问题生成模型的性能。
贡献
1. 提出了一种利用大规模 secondary language 数据提升 primary language问题生成的模型
2. 验证上述模型在印度语与中文问题生成的性能.
3. 使用上述模型构建了“文本-问题”形式的印度语问题生成数据集,命名为HiQuAD.
方法
基本概述:
1. 使用无监督模型,将单语primary与secondary文本训练编码到一个共享潜在空间中.
2. 基于上述编码结果,使用大规模 secondary language的问题生成数据以及小规模primary language问题生成数据,用于训练一个有监督模型(Seq2Seq),从而提升primary language的问题生成.
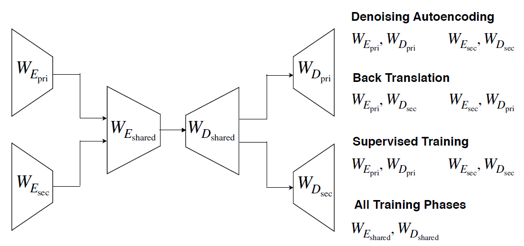
图1问题生成模型框架
模型概述(对照方法基本概述):
模型框架由(左→右)编码-解码两个主要层次构成(原文描述为两个编码器和两个解码器构成):
编码层包含两个子层:
1. 第一层为独立的两个单语编码器,分别用于primary(参数下标为 pri)及secondary(参数下标为 sec) language的初编码,W_E/W_D分别表示编码/解码的权重参数;
2. 第二层为融合编码器(两种语言共享编码权重参数),用于将primary及secondary language的初编码结果融合到共享编码空间中;
解码层也包含两个子层:
1. 第三层共享双语权重参数的解码器;
2. 第四层为分别用于primary及secondary language的单语解码器;
方法细节说明
1. 过程细节:
无监督编码过程(作者称为无监督预训练)算法如下图所示:

其中,x_p/x_s 分别表示 primary/secondary 对应的句子,算法包含三个步骤(三个步骤的目的均是通过训练调整模型 W_E/W_D 参数):
1) 训练编码器,用于将带有噪声的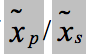
2) 使用关联的编码-解码器将 x_p/x_s 翻译为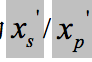
3) 利用步骤2中得到的译文结果
问题生成过程算法如下图所示:

1) 使用预训练部分得到的权重参数作为问题生成模型的初始参数
2) 使用 primary/secondary 数据分别训练对应语言的生成模型(通过 secondary 语言的 QG 训练过程对共享编码/解码的权重参数进行微调,从而提升 primary 语言的 QG 性能)
2. 技术细节:
1) 本文使用的编码/解码器模型基于 Transformer 模型(作者表示相对RNN编码模型,在翻译任务中,Transformer 模型效果更好),不同的是,作者将位置信息也加入编码中,并参照双向 RNN 的做法,从两个序列输入方向分别对文本进行编码处理。
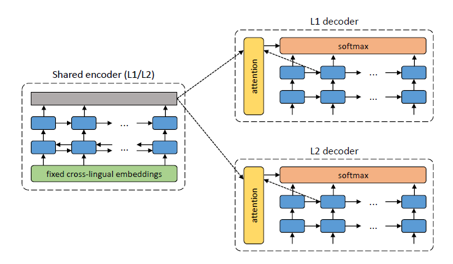
2) 去噪编码(预训练算法策略)采用 ‘UNSUPERVISED NEURALMACHINE TRANSLATION’一文类似的策略(如下图所示),通过共享编码,而后单语解码,可以实现对单语文本的重构(去噪)。与他们不同的是,本文作者在共享编码之前先对两种语言单独进行初编码,其次是作者使用 Transformer 替换 RNN 编码/解码。
3) 在训练问题生成模型时,所使用的词表利用BPE方法做子字化(subword unit)处理,使词表的覆盖能力更强,减少OOV情况的同时缩小词表规模(作者表示直接使用原始词表将出现内存不足的错误)
实验
数据说明:
HiQuAD 数据集说明
作者构建的HiQuAD包含6555个‘问题-答案’对,来自于1334个文本段落(原始来源为Dharampal Books),为了构建“文本-问题”对,对于给定的问题,作者首先从段落中选取答案中的首词,然后抽取出对应的整句。
其他实验使用到的数据集说明:
Primary:印度;Secondary:英语
IITB 印度语单语数据集:作者从中抽取了93000个句子作为实验用单语文本(用于预训练阶段)
IITB 印度语-英语平行语料:作者从中抽取了100000个句对用于对预训练结果进行微调,抽取规则确保每个句子长度大于10
Primary:中文;Secondary:英语
DuReader 中文单语数据集:规模为8000
News Commentary Dataset 中英平行语料:包含91000的中英平行语料
SQuAD英文问答数据集:包含70484规模的“文本-问题”对
实验方案:
增量模型说明
1. Transformer:直接使用小规模问题生成训练集训练得到生成模型;
2. Transformer+pretraining:使用单语数据对编码解码模型进行预训练后,将得到权重参数作为问题生成模型的初始参数;
3. CLQG:使用双语数据预训练/问题生成的 Transformer+ pretraining;
4. CLQG+parallel:预训练之后,使用平行语料对权重参数进行进一步微调的CLQG;
评价指标说明(均是机器翻译相关指标,得分越高代表系统性能越好)
1. Bleu
2. ROUGE-L
3. METEOR
实验结果
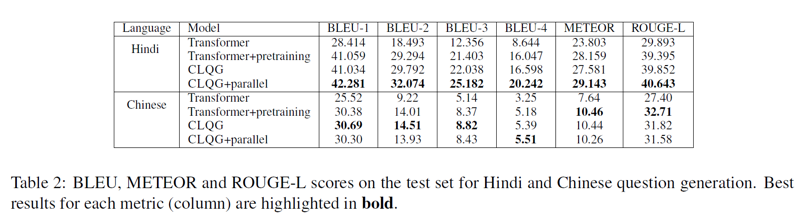
在印度语的问题生成实验中,CLQG+parallel 模型均取得了最优结果,但是在中文 QG 实验结果上,增量模型的效果并不突出,但整体上能够反映出英语语料对于中文问题生成能够带来提高。
分析
1. 利用资源丰富的语料+跨语言表示学习,能够帮助提升小规模语料的表示学习效果,但是,作者并没有验证在同等情况下,该方法对英语(大规模语料)编码效果的影响
2. HiQuAD 语料的构建过程并不明确,从实验上看,小语种语言问题的生成依然需要小规模的 QG 标注语料参与训练,但是作者对于HiQuAD的构建过程仅描述了获得问题之后文本的获取方式。但问题本身的来源,是否使用了小规模的印度语QG标注数据等细节,未做说明
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。


