目标检测论文阅读:DetNet
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:扬之水
来源:https://zhuanlan.zhihu.com/p/46710723
DetNet: A Backbone network for Object Detection
论文链接:https://arxiv.org/pdf/1804.06215.pdf
之前一直在看一篇综述类的文章,这周最开始也是想分享那篇文章的,但内容实在太多外加全是论述看得非常吃力。所以这周来看这篇改进Backbone的文章。这篇整体的思路还是比较简单易懂的,相较于那些复杂的结构变化或者技巧,它关注的是特征抽取网络如何改善的问题,效果还是比较好的。
1. 问题背景
一直以来,很少有人关注目标检测的特征抽取网络问题,特征抽取网络一般使用的是和分类相同的特征抽取器(例如resnet等,它们泛用性强,不是专门为目标检测设计的),这样也有一个好处就是可以使用ImageNet的预训练网络。 但是也会有一些潜在的问题,本质上这是两个问题的不同导致的,比如目标检测不仅关注分类,还关注定位问题。但是分类问题不关注位置的准确性,为了保证足够的感受野来认知图片整体,网络往往会使用较大的downsampling factor,这对定位的准确性非常不利。作者主要是针对这一点提出了一些设想并做出实验,力图得到同时具有高分辨率和高语义性、保持大的感受野的特征,并且更加适合目标检测问题。
2. 网络结构
潜在问题
DetNet的整体网络结构和FPN的对比如下图所示:
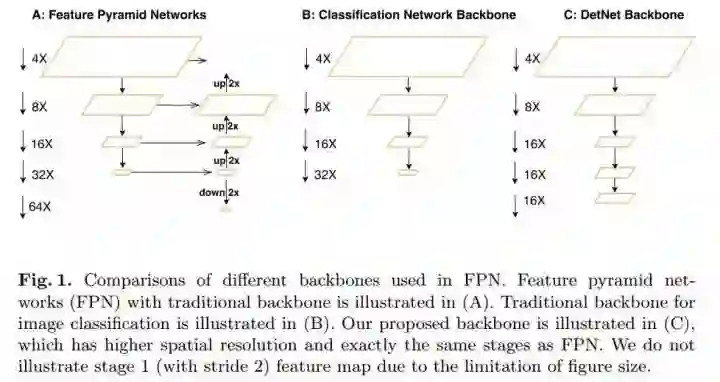
FPN等传统的特征网络具有如下几个问题:
网络的stages不同,FPN一般在从ImageNet迁移到检测问题上时,会添加一个额外的P6来处理大尺度的目标,这一层是没办法在ImageNet上预训练的
FPN中的深层虽然语义性很好,但由于缺乏细节信息,导致对大目标的定位不够精准
FPN的提出最早要解决的一个痛点就是对小目标检测率较差,因此把低分辨率、高语义层的深层与高分辨率、低语义层的浅层叠加,但是实际上,小目标的信息在深层损失中很严重,这种结合方式或许并不是最优解 因此,作者在设计 DetNet的时候,一方面希望DetNet所有层都是可以在ImageNet上预训练的,另一方面希望得到同时具备高语义化和高分辨率的特征,而不是像FPN那样简单粗暴地叠加。
DetNet的设计
看起来,高语义化和高分辨率是矛盾的。高语义化的前提是要有足够大的感受野,但感受野增加一般伴随着分辨率的降低,为了解决这一问题,作者使用了空洞卷积,其改进后的两种基本残差结构和传统残差结构的对比如下图所示。 作者以ResNet50为例进行实验,1-4阶段和传统的ResNet相同,后面开始使用自己设计的空洞卷积残差结构。空洞卷积可以有效增加感受野,同时避免strides过大引起的分辨率不足问题。
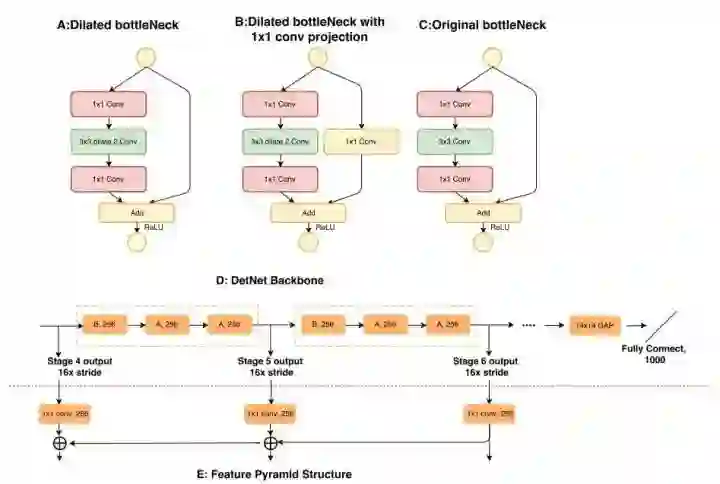
DetNet的主要特点如下:
从4阶段向后,降采样因子固定为16x
4阶段之后使用空洞卷积的残差结构,且每个阶段开始使用B结构,之后是A结构
空洞卷积的计算需要花费大量时间,因此作者减少了stage 5和6的通道数,保持在256而不是会增加 这里其实比较值得关注的是B结构和A结构的区分。这里有一个比较关键的问题就是,在降采样因子固定以后,不同阶段是怎么区分的? 我们知道,ResNet在每个阶段的开始结构都是不同的,会对feature map降采样,这是区分不同阶段的关键。对比ResNet101和50的同一个阶段,我们会发现前者会叠加重复更多个上图中C的结构,但是它们仍然是属于同一阶段的……那么,DetNet又是怎么区分不同阶段并保证有实质性的效果提升而不是单纯累加结构? 答案就是B里面的1x1 Conv结构,我认为这种跨通道的信息融合还是能比较好地进行信息整合的。作者给出了实验证明,不再详细介绍。
3. 实验结果
作者在准确率和召回率方面都做了实验,对比如下:
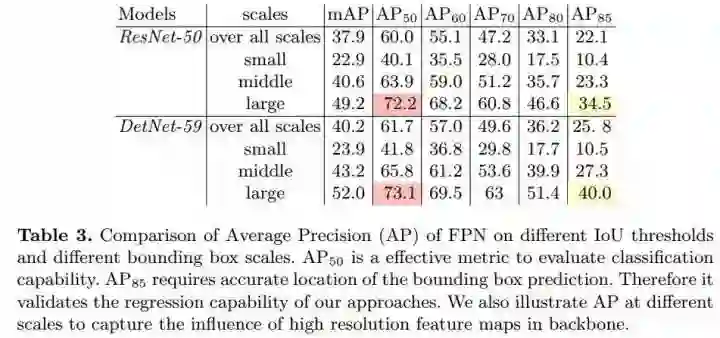

可以看到,DetNet在大物体的准确率上提升非常大,而且IoU指标越大效果越明显,这说明DetNet的深层网络还有很多分辨率细节信息,对最后准确定位帮助很多。另一方面,在IoU指标要求不大时,DetNet在小目标的召回率提升非常大,说明DetNet能很好地找到小物体,避免漏检。
最后上一张总的检测结果:
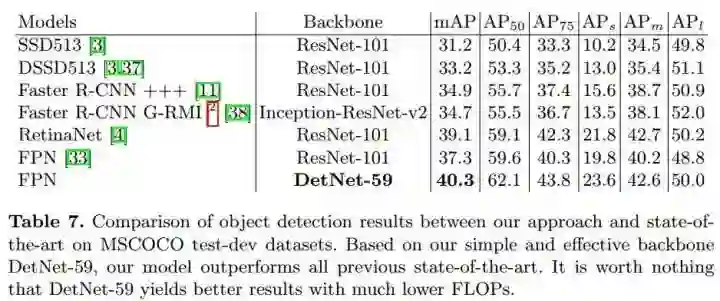
可以看出来,DetNet还是取得了很不错的效果,而且实现简单,只要简单地更改特征抽取网络的代码,不需要太多的技巧,有兴趣的同学不妨进行尝试~
*延伸阅读




