从Densebox到Dubox:更快、性能更优、更易部署的anchor-free目标检测
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | Amusi
本文转载自公众号CVer
最近 Anchor-free (no-prior box)的概念又重新火热起来,anchor-free的概念从2015年densebox, yolov1开始出现,但一开始性能并不是很好,后来基于anchor(prior box)的概念的检测算法如faster rcnn, ssd性能有很大的提升,于是目标检测从此走进anchor时代,但是最近anchor-free的文章出现很多,目标检测发现不使用anchor依然可以达到较好的效果。今天要介绍的Dubox和Densebox都是由百度提出的无先验框的一阶段目标检测算法。
《DuBox: No-Prior Box Objection Detection via Residual Dual Scale Detectors》

arXiv: https://arxiv.org/abs/1904.06883
github: None
作者团队:百度
注:2019年04月17日刚出炉的paper
引言:
传统的神经目标检测方法使用多尺度特征,让多个检测器独立并行地在多个分支执行检测任务。同时,加入先验框(prior box)提高了算法处理尺度不变性的能力。然而,过多的先验框和多个检测器会增加检测算法的计算冗余度。这篇论文介绍了一种新的一步检测方法Dubox,它可以在没有先验框的情况下检测物体。设计的双尺度残差单元具有多尺度特性,使双尺度检测器不再独立运行。高层检测器学习低层检测器的餐叉。Dubox增强了启发式引导的能力,进一步使第一尺度探测器能够最大限度地检测小目标,第二尺度探测器能够检测第一尺度探测器无法识别的目标。此外,对于每一个比例探测器,采用新的classification-regression strap loss,使检测过程不基于先验框。结合这些策略,检测算法在速度和精度方面取得了优异的性能。通过对VOC、COCO目标检测基准的大量实验,证实了该算法的有效性。
标签和loss设计:
首先对于标签的设计:
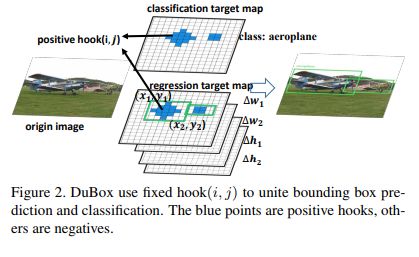
文章定义了在物体框内
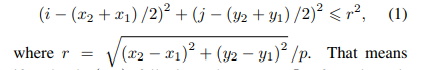
为正样本,其他为负样本。
熟悉densebox的同学都知道,这种设计和densebox相似,densebox更像分割类算法,对物体的中心范围进行回归+分类,因为物体内的范围都是正样本,其其他范围为负样本,为了克服正负样本波动性所以在正样本周围加上了一圈ignore范围,从而防止梯度的波动。Dubox没有使用固定的ignore范围,而是在loss设计时候是有iou gate unit自动的学习ignore范围。
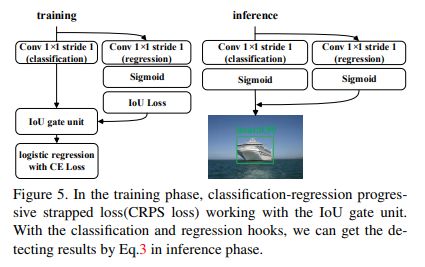
既只有回归框和真值框达到0.5的重合时分类才在该点产生loss,从而达到自动学习ignore范围的作用。用公式表达就可以写成:
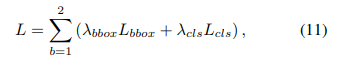
其中

Dubox框架设计:
Dubox的另一大创新是不再多个分支上独立并行的使用多个检测器,而是将检测器减少到了两个:
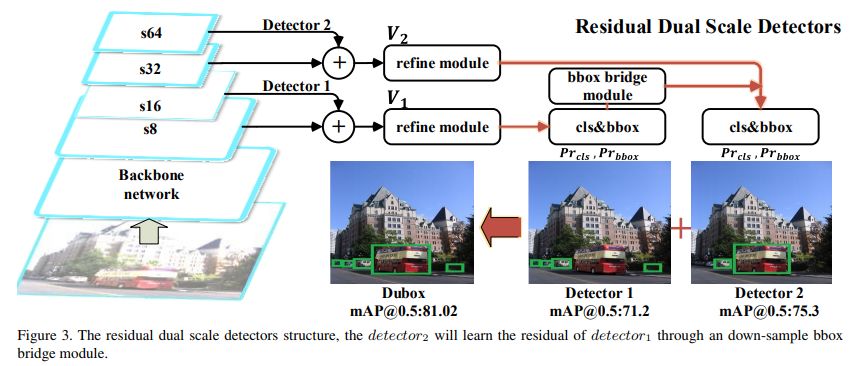
在这种设计中高层的检测器去检测底层检测器无法检测到的物体,从而最大化检测性能,
同时论文中为了减少两个检测器之间的检测冗余,设计了诸多减少冗余策略,使两个检测器之间的检测冗余最小,但整体达到了最优性能。
这种设计带来的好处有以下几点:
1. 基于分割的检测使底层检测效果明显高于yolo等算法。这源自于其基于分割的思想。
2. 第二个分支去检测第一个分支的残差,使独立运行变成了协同运作。
3. 整个网络的设计只使用简单的基本操作,这让其在部署中有非常大的优势。
4. 最后一个核心的可能只有经历过硬件部署的同学才能体会到,那就是更加优秀的int8部署。在部署gpu硬件上一般使用int8加速,但是使用一个分支进行int8进行量化时,有非常大的损失,这种损失可以看作,回归范围被强制映射到256个值,损失是在所难免的。而dubox的设计将两个分支进行分成无冗余的两个分支,两个分支分别进行int8量化产生的损失非常小甚至几乎没有。
实验:
最终的实验结果,论文各个部件的消融实验:

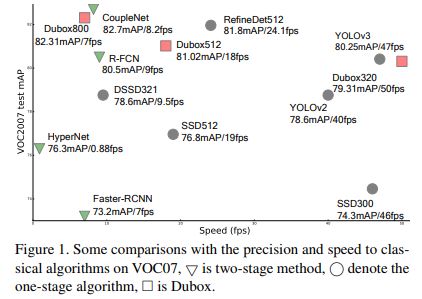
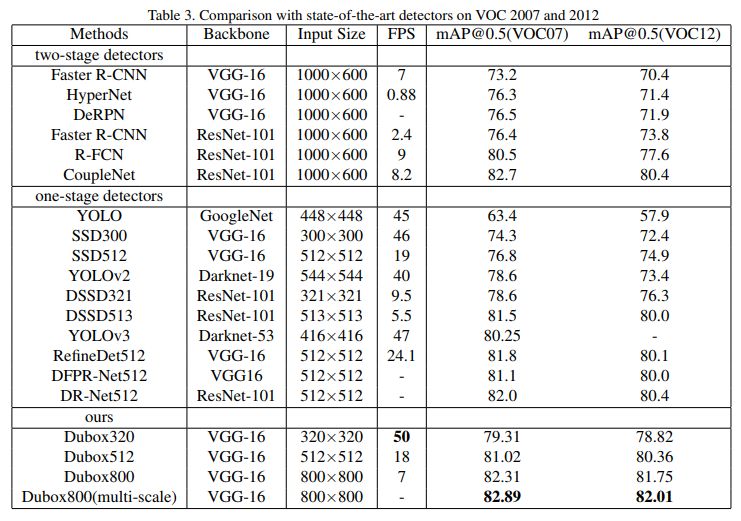
在voc上的速度和性能,达到了82.89的map, 其320x320版本达到了79.31map 和高达50fps的速度。
在coco上的性能:
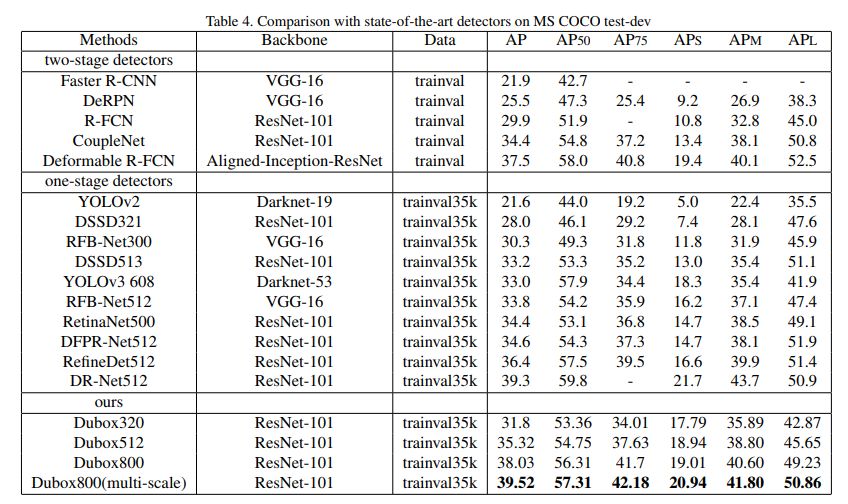
总结:
Dubox整体上属于densebox的强化版,进一步加强了其在硬件上的友好性,达到了速度和性能上的最优表现。使用int8量化后的速度会有更大的提升,相对的精度会损失很少,虽然论文中没有提到,这使dubox的设计更加适用于工程实践。
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个看啦~



