CVPR2018 目标检测算法总览(最新的目标检测论文)
极市平台是专业的视觉算法开发和分发平台,加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:AI之路
来源:
CVPR2018上关于目标检测(object detection)的论文比去年要多很多,而且大部分都有亮点。从其中挑了几篇非常有意思的文章,特来分享,每篇文章都有详细的博客笔记,可以点击链接阅读。
1、Cascaded RCNN
论文:Cascade R-CNN Delving into High Quality Object Detection
论文链接:https://arxiv.org/abs/1712.00726
代码链接:
https://github.com/zhaoweicai/cascade-rcnn
详细内容请移步:Cascade RCNN算法笔记
https://blog.csdn.net/u014380165/article/details/80602027
Cascaded RCNN这篇文章的出发点非常有意思,是通过分析输入proposal和ground truth的IOU与检测模型采用的用于界定正负样本的IOU关系得到结论:当一个检测模型采用某个阈值(假设u=0.6)来界定正负样本时,那么当输入proposal的IOU在这个阈值(u=0.6)附近时,该检测模型比基于其他阈值训练的检测模型的效果要好,参看FIgure1(c)。
Cascaded RCNN通过级联几个检测网络达到不断优化预测结果的目的,与普通级联不同的是,cascade R-CNN的几个检测网络是基于不同IOU阈值确定的正负样本上训练得到的,前一个检测模型的输出作为后一个检测模型的输入,因此是stage by stage的训练方式,而且越往后的检测模型,其界定正负样本的IOU阈值是不断上升的。cascade R-CNN的实验大部分是在COCO数据集做的,而且效果非常出彩。
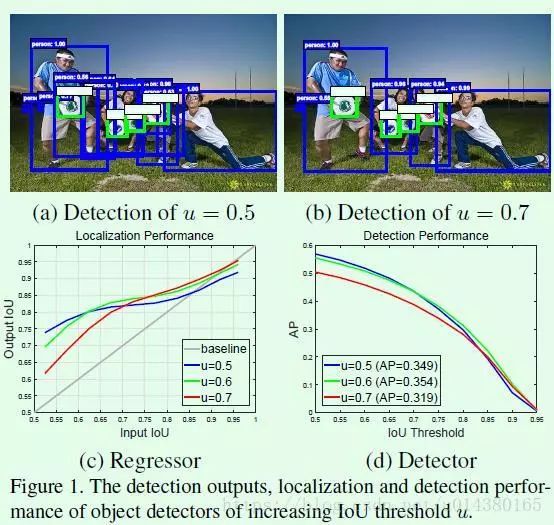
这是在COCO数据集上的结果。
2、Relation Networks for Object Detection
论文:Relation Networks for Object Detection
论文链接:https://arxiv.org/abs/1711.11575
代码链接:https://github.com/msracver/Relation-Networks-for-Object-Detection
详细内容请移步:Relation Networks for Object Detection算法笔记
https://blog.csdn.net/u014380165/article/details/80779432
Relation Networks for Object Detection源码解读(网络结构细节)
https://blog.csdn.net/u014380165/article/details/80779712
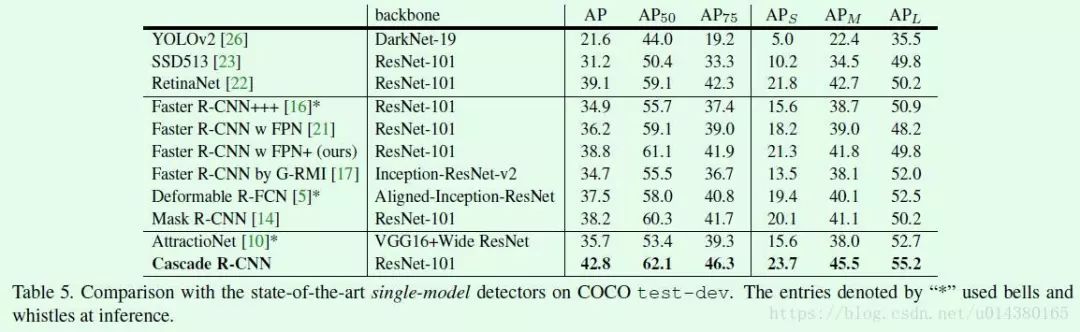
这篇文章的出发点在于目前大部分的目标检测(object detection)算法都是独立地检测图像中的object,但显然如果模型能学到object之间的关系显然对于检测效果提升会有帮助,因此这篇文章希望在检测过程中可以通过利用图像中object之间的相互关系或者叫图像内容(context)来优化检测效果,这种关系既包括相对位置关系也包括图像特征关系。
这篇文章提出了object relation module来描述object之间的关系,从而以attention的形式附加到原来的特征上最后进行回归和分类。实验是针对two stage系列的目标检测算法而言,在ROI Pooling后的两个全连接层和NMS模块引入object relation module,如Figure1所示,因此做到了完整的end-to-end训练。
3、RefineDet
论文:Single-Shot Refinement Neural Network for Object Detection
论文链接:https://arxiv.org/abs/1711.06897
代码链接:
https://github.com/sfzhang15/RefineDet
详细内容请移步:RefineDet算法笔记、
https://blog.csdn.net/u014380165/article/details/79502308
RefineDet算法源码 (一)训练脚本、
https://blog.csdn.net/u014380165/article/details/80562416
RefineDet算法源码(二)网络结构
https://blog.csdn.net/u014380165/article/details/80562452
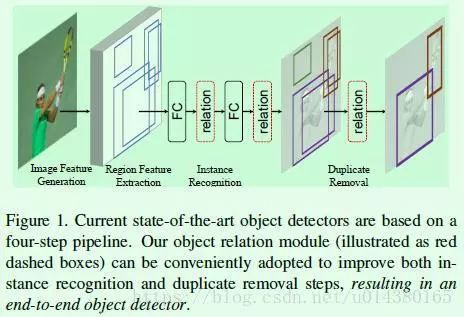
个人觉得RefineDet是一篇很不错的文章,该算法大致上是SSD算法和RPN网络、FPN算法的结合,可以在保持SSD高效的前提下提高检测效果(实验效果提升挺明显)。第一眼看到这篇文章就让我想起了RON,毕竟都是想做one stage和two stage的object detection算法结合。
RefineDet的主要思想:一方面引入two stage类型的object detection算法中对box的由粗到细的回归思想(由粗到细回归其实就是先通过RPN网络得到粗粒度的box信息,然后再通过常规的回归支路进行进一步回归从而得到更加精确的框信息,这也是two stage类型的object detection算法效果优于one stage类型的一个重要原因)。另一方面引入类似FPN网络的特征融合操作用于检测网络,可以有效提高对小目标的检测效果,检测网络的框架还是SSD。
网络结构参考Figure1。
4、SNIP
论文:An Analysis of Scale Invariance in Object Detection – SNIP
论文链接:https://arxiv.org/abs/1711.08189
代码链接:http://bit.ly/2yXVg4c
详细内容请移步:SNIP 算法笔记
https://blog.csdn.net/u014380165/article/details/80793334
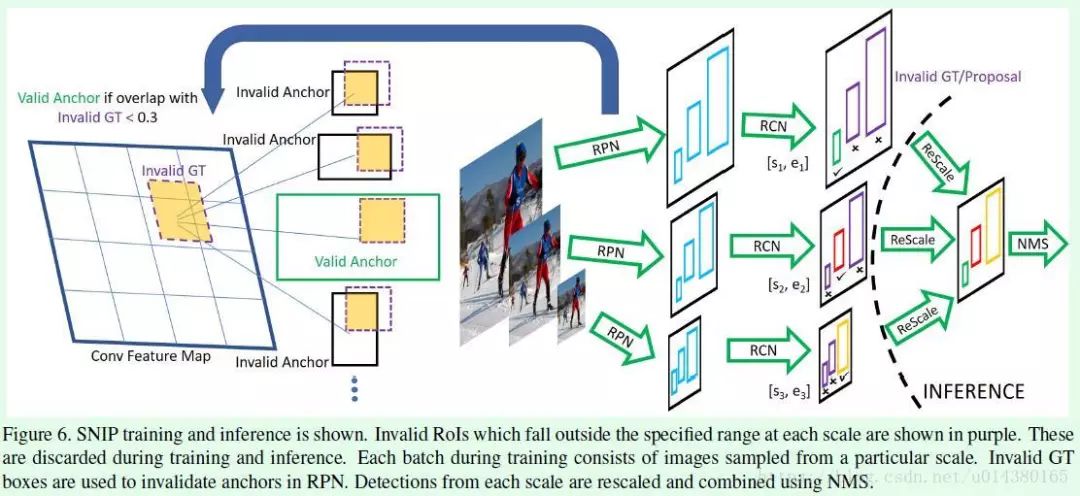
这篇文章从数据集出发进行了非常详细的分析和实验对比,发现在COCO数据集中小目标占比要比ImageNet数据集大,这样在用ImageNt数据集的预训练模型时就会产生domain-shift问题,另外COCO数据集中的object尺寸变化范围非常大,即便采用multi-scale training的方式也很难训练一个检测器去cover所有scale的目标。
因此,这篇文章针对前面提到的问题,提出一种新的训练模型的方式:Scale Normalization for Image Pyramids (SNIP),该算法主要包含两个改进点:1、为了减少前面所提到的domain-shift,在梯度回传时只将和预训练模型所基于的训练数据尺寸相对应的ROI的梯度进行回传。2、借鉴了multi-scale training的思想,引入图像金字塔来处理数据集中不同尺寸的数据。
SNIP网络结构参考Figure6。
5、R-FCN-3000
论文:R-FCN-3000 at 30fps: Decoupling Detection and Classification
链接:https://arxiv.org/abs/1712.01802
详细内容请移步:R-FCN-3000算法笔记
https://blog.csdn.net/u014380165/article/details/78809002
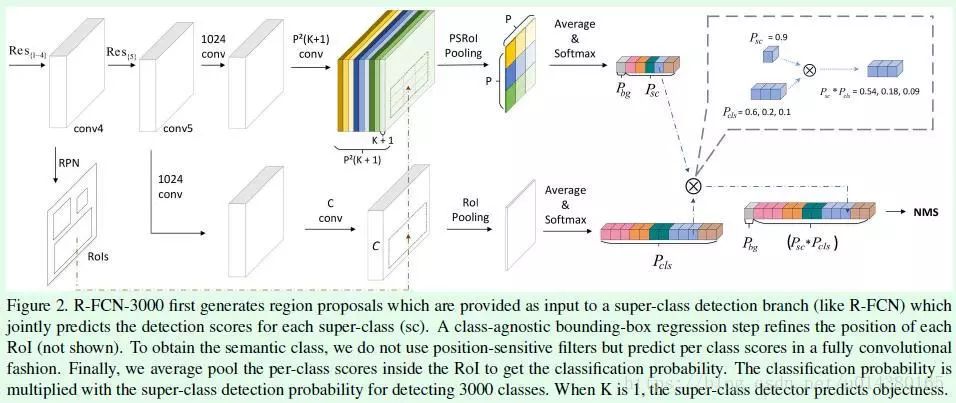
这篇文章主要是成功将R-FCN算法(关于R-FCN算法的介绍可以看博客)应用在检测类别较多的场景下。首先当初提出R-FCN算法的主要目的在于引入position-sensitive score map解决原来Faster RCNN中ROI的重复计算问题,有效提升速度。但是如果检测的类别数非常多(比如这里的3000类),那么直接用R-FCN算法的话速度是很慢的,瓶颈正是生成分类支路的position-sensitive score map时计算量非常大,因此这篇文章通过解耦分类支路的position-sensitive score map生成的过程(将原来的分类支路拆分成两条支路,而回归支路还是采用R-FCN的回归支路,这篇文章不做修改,这是因为增加检测类别数增加不影响回归支路的计算量),从而在保证速度(30FPS)的情况下将R-FCN的分类类别数延伸至3000类。
Figure2是F-RCN-3000的分类支路过程,该过程包含两条支路(Figure2上面那条是生成objectness score的过程,Figure2下面那条是生成fine-grained classification score的过程),这两条支路的结果的乘积才是最终的分类结果。在Figure2中回归部分并未画出,但是需要注意的是回归部分和R-FCN的回归部分是一样的。
6、DES
论文:Single-Shot Object Detection with Enriched Semantics
论文链接:https://arxiv.org/abs/1712.00433
详细内容请移步:Detection with Enriched Semantics(DES)算法笔记
https://blog.csdn.net/u014380165/article/details/80602240
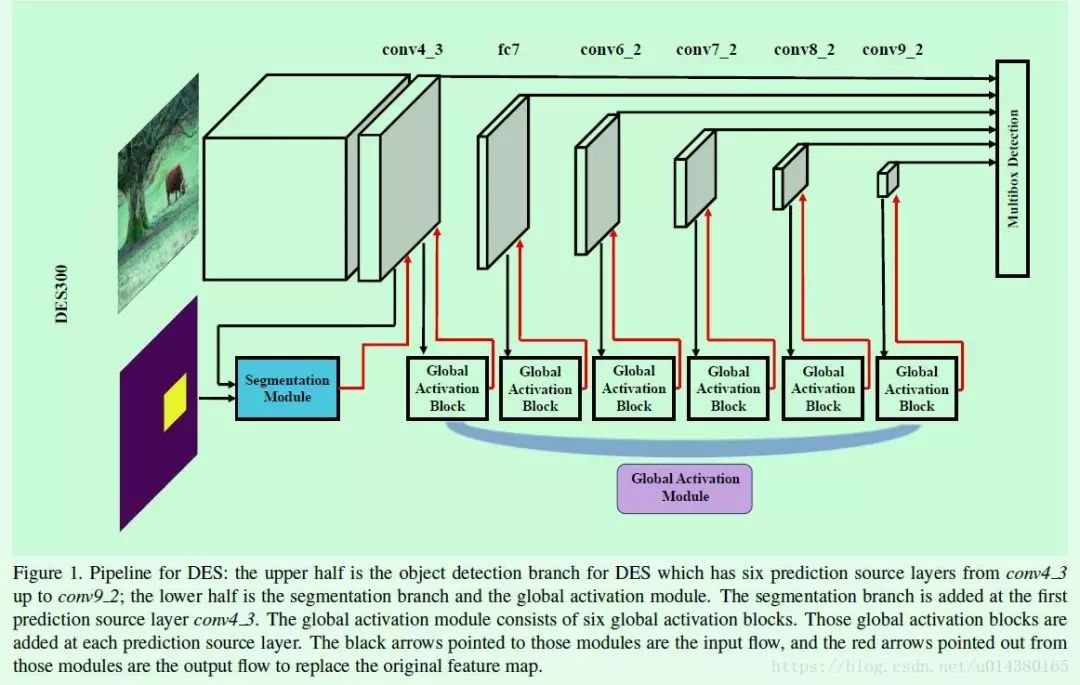
Detection with Enriched Semantics(DES)主要是基于SSD做改进,也是为了解决SSD中对于小目标物体的检测效果不好的问题,因为SSD算法对小目标的检测只是利用了浅层的特征,并没有用到高层的语义特征。因此这篇文章的出发点就是为了增加用于检测的feature map的语义信息,
主要的措施包括:
1、引入segmentation module用于得到attention mask,从而提高low level的feature map的语义信息。
2、引入global activation module用于提高high level的feature map的语义信息。
实验效果不错,在VOC2007数据集上,DES512能达到81.7的mAP,而且在Titan X上的速度是31.7FPS(batch设置为8,不过比相同大小输入和相同特征提取网络的SSD算法慢一些)。
网络结构参考Figure1。
7、STDN
论文:Scale-Transferrable Object Detection
论文链接:https://pan.baidu.com/s/1i6Yjvpz
详细内容请移步:Scale-Transferrable Detection Network(STDN)算法笔记
https://blog.csdn.net/u014380165/article/details/80602130
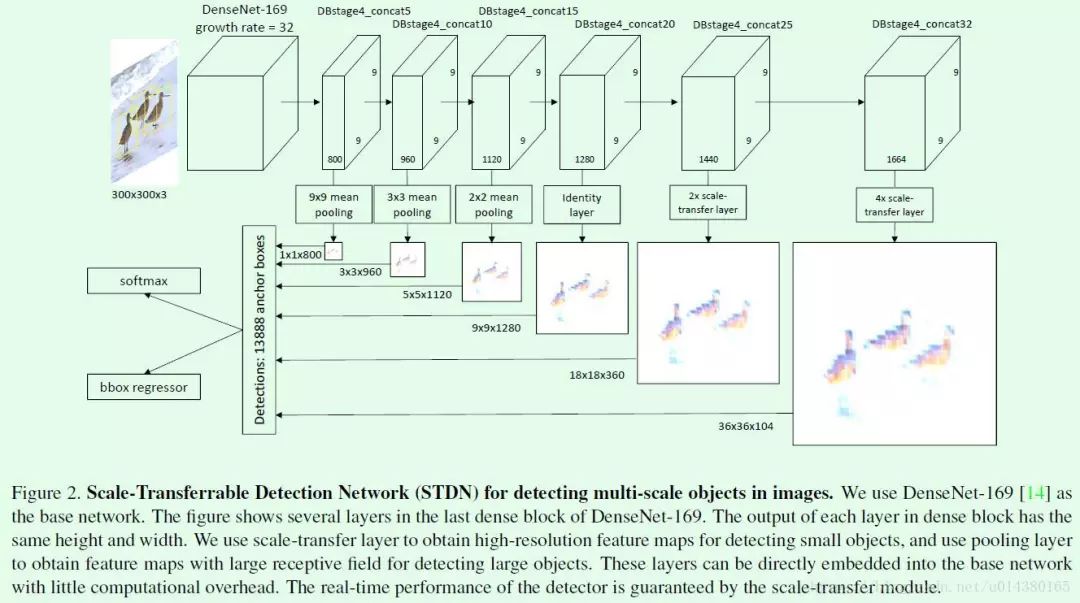
Scale-Transferrable Detection Network(STDN)算法主要用于提高object detection算法对不同scale的object的检测效果。该算法采用DenseNet网络作为特征提取网络(自带高低层特征融合),基于多层特征做预测(类似SSD),并对预测结果做融合得到最终结果。
该算法有两个特点:
1、主网络采用DenseNet,了解DenseNet的同学应该知道该网络在一个block中,每一层的输入feature map是前面几层的输出feature map做concate后的结果,因此相当于高低层特征做了融合。高低层特征融合其实对object detection算法而言是比较重要的,FPN算法是显式地做了高低层特征融合,而SSD没有,这也是为什么SSD在小目标问题上检测效果不好的原因之一,因此该算法虽然看似SSD,但其实和SSD有区别。
2、引入scale-transfer layer,实现了在几乎不增加参数量和计算量的前提下生成大尺寸的feature map(其他常见的算法基本上都是采用deconvolution或upsample),由于scale-transfer layer是一个转换操作,因此基本不会引入额外的参数量和计算量。
网络结构参考Figure2。
*推荐文章*
聊聊目标检测中的多尺度检测(Multi-Scale),从 YOLO到FPN,SNIPER,SSD 填坑贴和极大极小目标识别
8500+观看的缺陷检测干货!全球冠军团队全面剖析深度学习在工业检测中的应用(PPT+视频)
简析缝隙检测算法新思路
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~



