
【导读】由于深度神经网络具有强大的学习不同层次视觉特征的能力,因此被广泛应用于目标检测,语义分割,图像描述等计算机视觉应用当中。从ImageNet这样的大型图像数据集中训练得到的模型被广泛地用作其他任务的预训练模型,主要有两个原因:(1)从大规模数据集中学习得到的参数能够为其他模型提供一个良好的训练起点,在其他任务上模型网络可以更快地收敛。(2)在大规模数据集上训练的网络已经学习到了层次特征,这有助于减少其他任务训练过程中的过拟合问题,特别是当其他任务的数据集较小或标注数据不足的情况。
介绍
为了在计算机视觉应用中学习得到更好的图像和视频特征,通常需要大规模的标记数据来训练深度神经网络。为了避免收集和标注大量的数据所需的巨大开销,作为无监督学习方法的一个子方法——自监督学习方法,可以在不使用任何人类标注的标签的情况下,从大规模无标记数据中学习图像和视频的一般性特征。本文对基于深度学习的自监督一般性视觉特征学习方法做了综述。首先,描述了该领域的动机和一些专业性术语。在此基础上,总结了常用的用于自监督学习的深度神经网络体系结构。接下来,回顾了自监督学习方法的模式和评价指标,并介绍了常用的图像和视频数据集以及现有的自监督视觉特征学习方法。最后,总结和讨论了基于标准数据集的性能比较方法在图像和视频特征学习中的应用。
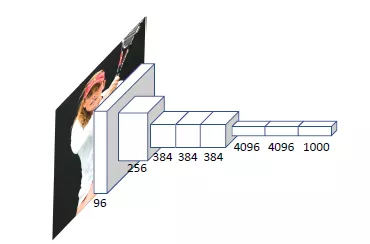
用于图像特征学习的架构
1.AlexNet:与以往的方法相比,AlexNet极大的提高了在ImageNet数据集上的图像分类性能。AlexNet架构总共有8层,其中的5层是卷积层,3层是全连接层。ReLU激活函数被运用在每一个卷积层后面。
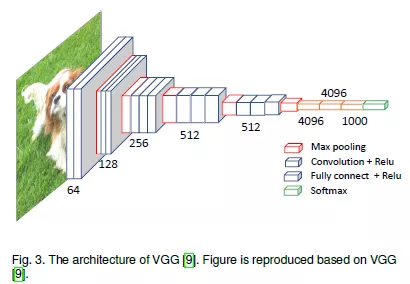
2.VGG:该模型赢得了ILSVRC2013挑战赛的第一名。其中的VGG-16由于模型尺寸适中,性能优越,被广泛使用。
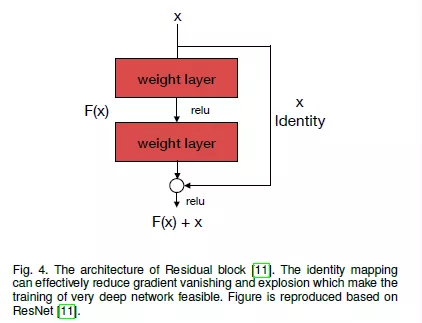
3.ResNet:该网络阐述了网络越深越能够获得良好的性能。但是由于梯度消失和梯度爆炸,深度神经网络很难训练。ResNet使用跳跃连接把前一层的特征直接传递到下一个卷积块来克服梯度消失和梯度爆炸的问题。
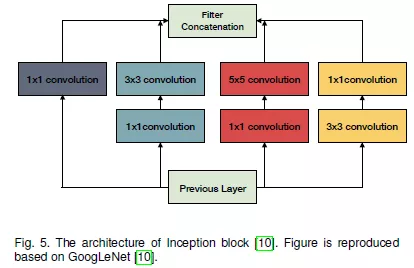
4.GoogleNet:22层的深度网络,以93.3%的准确率赢得了ILSVRC-2014挑战赛。和之前的网络相比,它拥有更深的网络。GoogleNet的基础模块inception块由4个平行的卷积层组成,这4个卷积层的卷积核尺寸不同,每层后面都有一个1x1的卷积操作来降低维度。
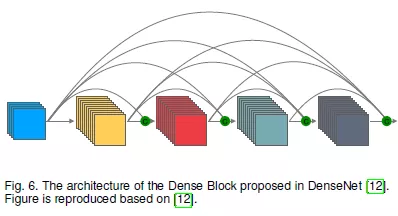
5.DenseNet:大多数网络包括AlexNet, VGG和ResNet都遵循层次结构。图像被输入到网络中,由不同的层提取特征。浅层提取低级的一般性特征,而深层提取特定于任务的高级特征。然而,当一个网络变得越来越深的时候,更深的网络层可能会记住完成任务所需的底层特征。为了避免这一问题,DenseNet通过稠密连接将一个卷积块之前的所有特征作为输入输送到神经网络中的下一个卷积块。
视频特征学习架构
Spatiotemporal Convolutional Neural Network
三维卷积运算最早是在3DNet中提出的,用于人类行为识别。与2DConvNets分别提取每一帧的空间信息,然后将它们融合为视频特征相比,3DConvNets能够同时从多个帧中同时提取空间和时间特征。
随着三维卷积在视频分析任务中的成功应用,出现了3DConvNet的各种变体。比如Hara等人提出了3DResNet,将ResNet中所有的2D卷积层替换为3D卷积层。实验表明,在多个数据集上,3D卷积层的性能更为优异。
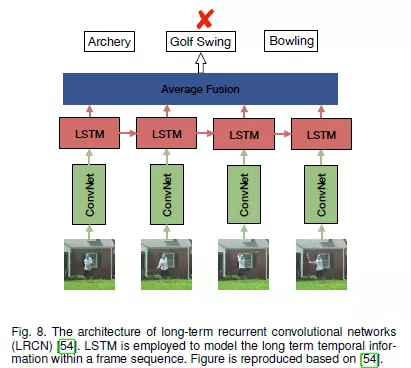
Recurrent Neural Network(RNN)
由于RNN能够对一个时间序列数据进行动态建模,所以RNN通常被应用于视频的有序帧序列当中。和标准的RNN相比,LSTM使用内存单元来存储,修改和访问内部状态,从而更好的对视频帧之间的长时间序列进行建模。基于LSTM的优势,Donahue提出了long-term recurrent convolutional networks (LRCN)用于人类行为识别。
数据集介绍
1.图像数据集
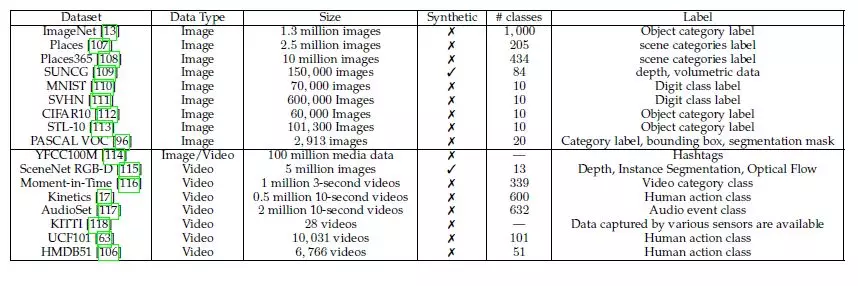
2.视频数据集
YFCC100M:该数据集是从Flicker上收集的多媒体数据集,由1亿条多媒体数据组成,其中的99200000条数据是图片,剩余的800000条数据是视频。
SceneNet RGB-D:该数据集是一个大型的室内视频合成数据集。
Moment in Time:该数据集是一个用于视频内容理解的数据集,内容多样且分布均衡。
Kinetics:该数据集规模大,质量高,用于人类行为识别。
AudioSet:该数据集由来自YouTube的2084320条人工标记10秒的声音剪辑组成,这些视频涵盖了632个音频事件。
KITTI:该数据集是在驾驶汽车时收集的,收集数据时的装备有各种传感器,包括高分辨率RGB相机、灰度立体声相机、3D激光扫描仪和高精度GPS测量。
UCF101:该数据集被广泛使用于人类动作识别。
HMDB51:相比于前面的数据集,该数据集是一个小规模的视频数据集,用于人流动作识别。


