FoveaBox,超越Anchor-Based的检测器
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
TeddyZhang:上海大学研究生在读,研究方向是图像分类、目标检测以及人脸检测与识别
最近,目标检测领域出现了一大批anchor-free的算法,如FCOS, FSAF等等,其主要的思路大都起源于2015年的DensBox和2016年的UnitBox,极市也分享了一篇相关的综述:
目标检测:Anchor-Free时代 ,今天,我们再来解读其中一篇完全anchor-free的算法,FoveaBox。
论文地址:https://arxiv.org/abs/1904.03797

在此之前,我们首先讨论一下anchor-based的算法的缺点:
对于每个预选框我们都要根据不同的任务去设置其参数,如长宽比,尺度大小,以及anchor的数量,这就造成了不同参数所导致的AP有很大的不同,同时调参耗时耗力。
产生的预选框在训练阶段要和真实框进行IOU的计算,这会占用很大的运行内存空间和时间。对于单阶段算法来说,为了使其更为有效的检测小目标,通常进行FPN结构以及使用更低的特征图,这样来说产生预选框的数量就会增加很多很多。
针对不同的任务,比如人脸识别和通用物体检测,所有的参数都需要重新调节,这样一个模型的迁移能力就体现不出来了
而anchor-free算法的出现,似乎是一种思路去解决这样的问题,相比于anchor-based网络,FoverBox直接学习目标的存在概率和真实框的坐标(不产生预选框)。主要通过两个分支:
预测一个类别敏感的语义图作为目标存在的概率
预测一个中心点和边框坐标的一个映射关系
算法总览
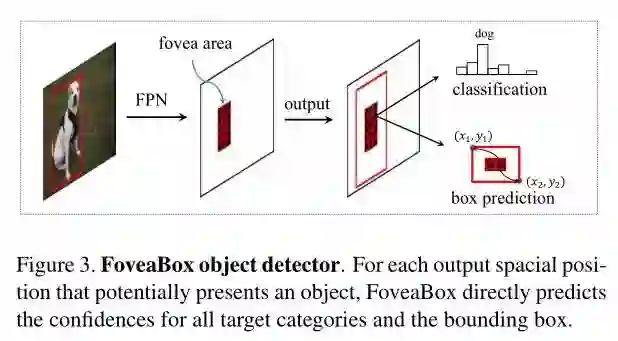
FoveaBox在训练和测试阶段都不需要依靠默认的anchor设置,这使得它对于bounding box的分布更有鲁棒性。FoveaBox的检测网络是有一个backbone网络和两个精度任务的subnet组合而成。Backbone网络用于计算输入图片的特征图(feature map),接着第一个子网络对backbone的输出做一个逐像素的分类任务,另一个子网络预测相对应位置的边框。
Backbone (FPN)
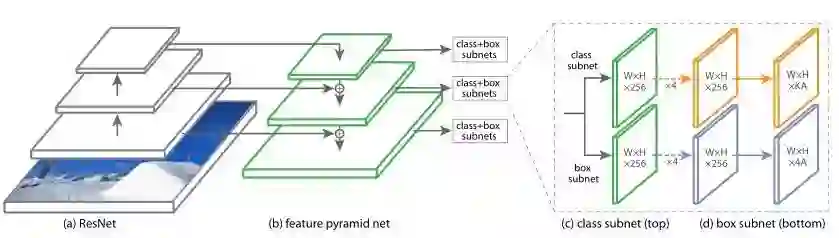
为了公平的与RetinaNet进行比对,作者使用了如其一模一样的网络结构,也就是ResNet+FPN的结构,其中金字塔的层数 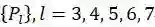
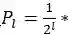
尺度分配
这里面我们也假设FPN中每一个层预测一定范围内的bounding box,而每个特征金字塔都有一个basic area,即32*32到512*512,所以表示为 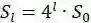
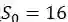
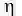

作者经过试验,发现当这个控制因子为2是为最优情况。
Object Fovea
首先我们来看预测分类的子网络,其输出为一个金字塔heatmap的集合,而每个heatmap的尺寸为HxW,维度为K,其中K为类别数量。如果给定真实框为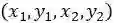
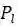
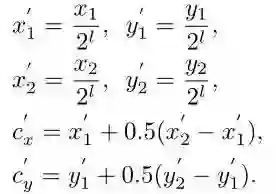
而正样本区域(fovea)被设计为原区域的一个衰减区域,这个与DenseBox的设置一样,这样设置的原因是为了防止语义区域的相互交叠!其中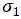
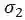

边框预测
与DenseBox和UnitBox不同,FoveaBox并不是直接学习目标中心到四个边的距离,而是去学习一个预测坐标与真实坐标的映射关系,假如真实框为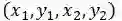
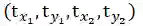
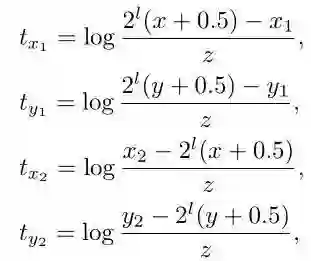
接着使用简单的L1损失来进行优化,其中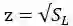
实验结果
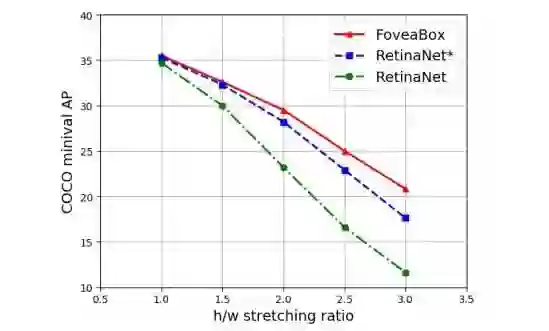
通过上图我们可以看到,相比于anchor-based的,anchor-free的算法对于目标的尺度更具有鲁棒性,并且完全不需要去费劲的设计anchor的尺寸。
接下来是AP和AR的比较:
1)FoveaBox与RetinaNet的比较

2)与ASFA(CVPR2019)的比较
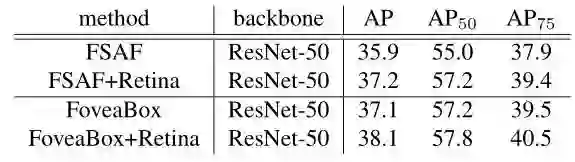
3)与其他SOTA方法的对比(coco test-dev)
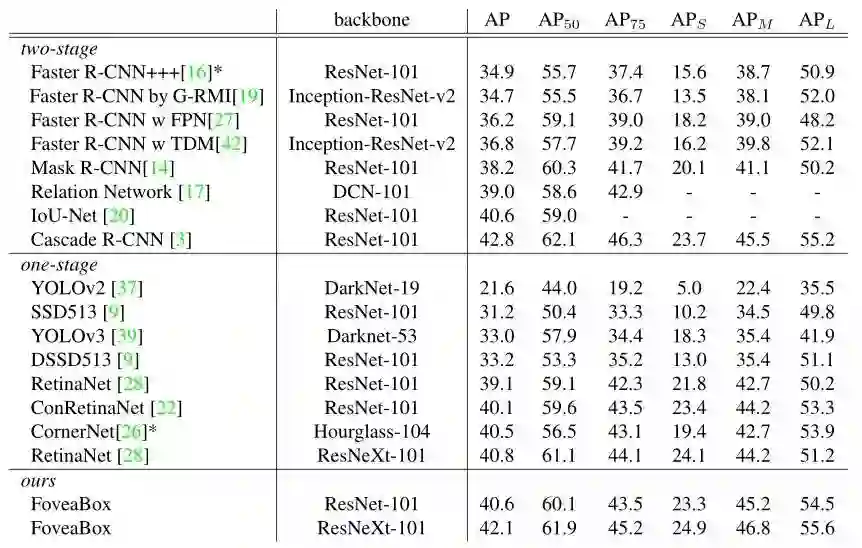
总结
FoveaBox整体设计思路为anchor-free,不需要人为的去定义anchor的参数,但仍然需要手工的去设置参数,比如每层的area的范围,以及正样本区域的缩放因子的参数。总的来说还是不错的,吸取了DenseBox的大量优点,也对其进行了优化。在预测坐标方面,不是单纯的去预测一个distance,而是去学习一个映射Transform。
*延伸阅读
CVPR2019 | 行人检测新思路:高级语义特征检测取得精度新突破
FCOS: 最新的one-stage逐像素目标检测算法
CVPR2019 | FSAF:来自CMU的Single-Shot目标检测算法
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~

