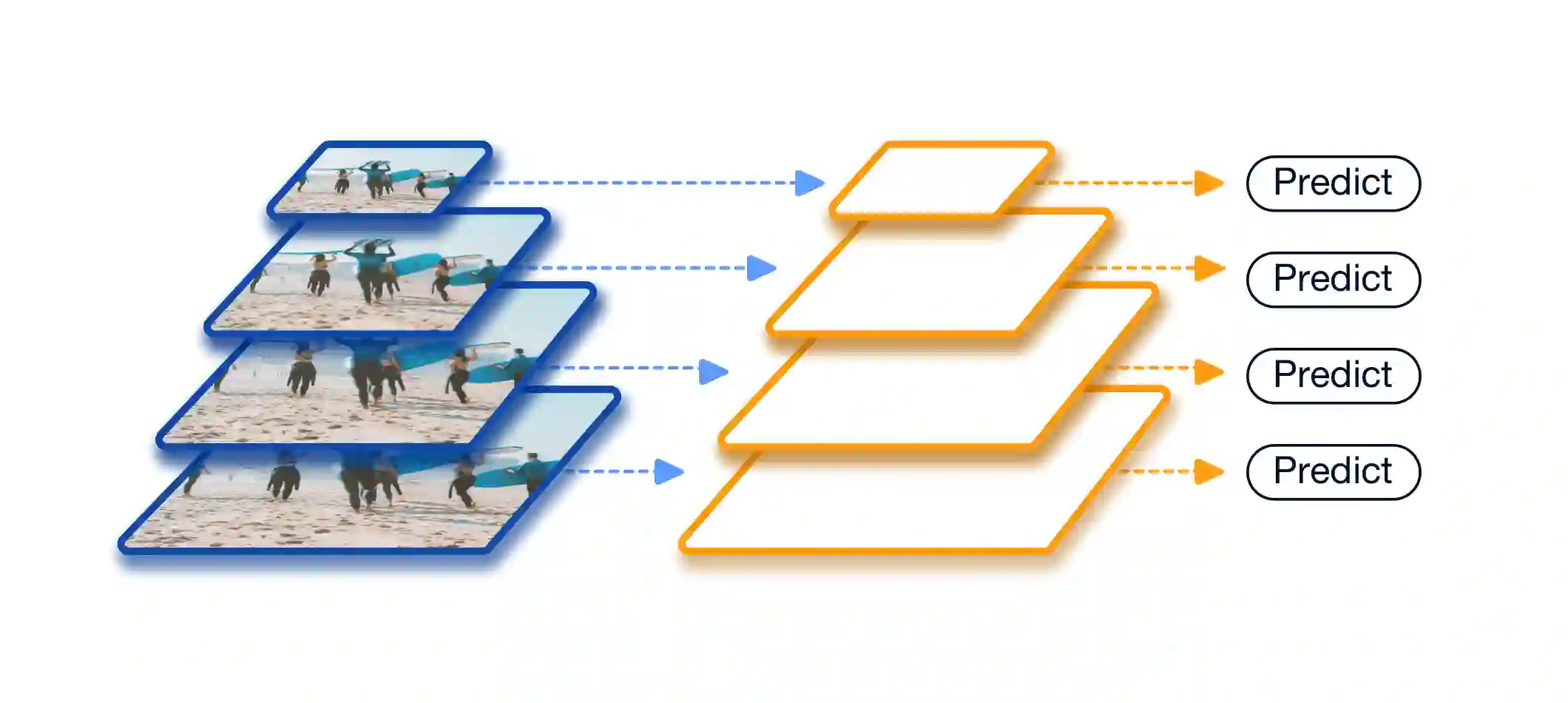
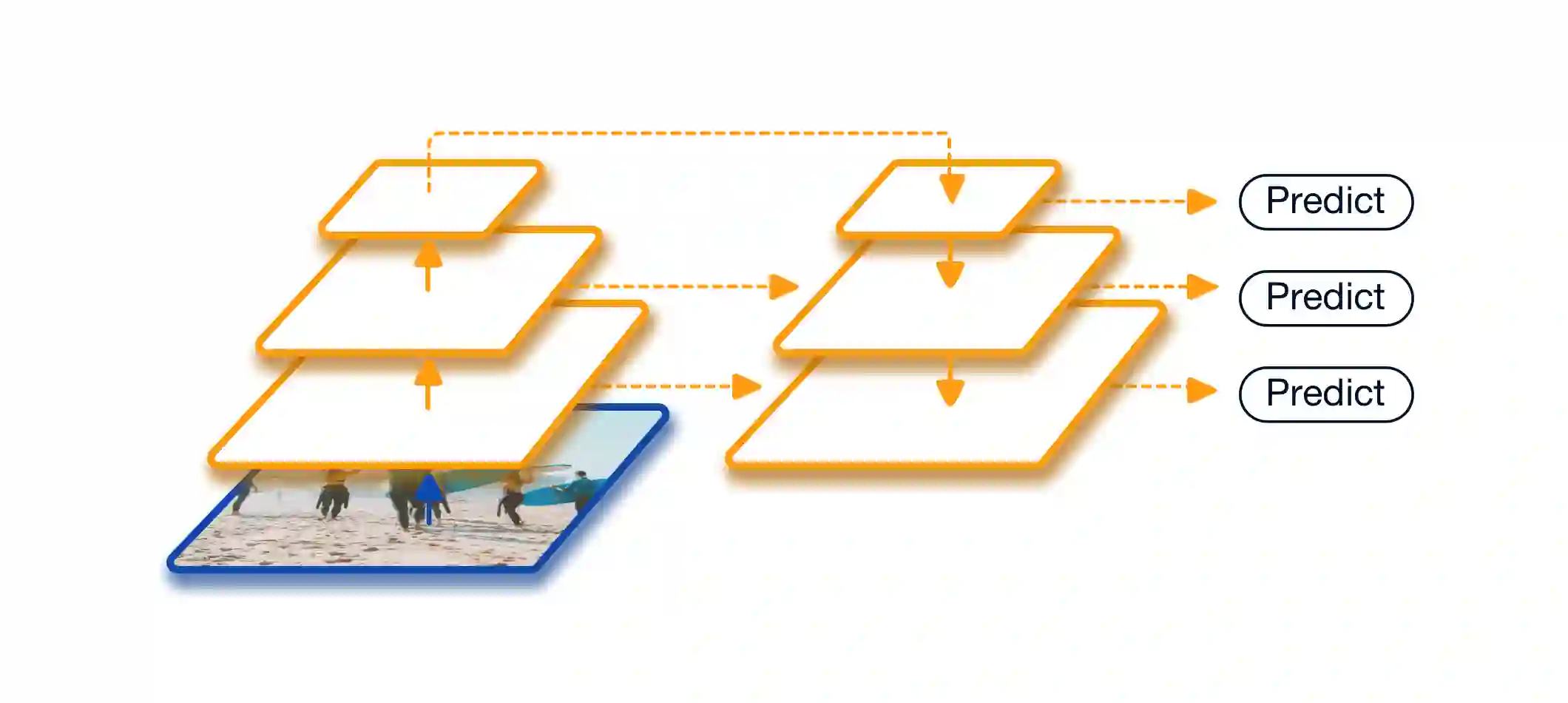
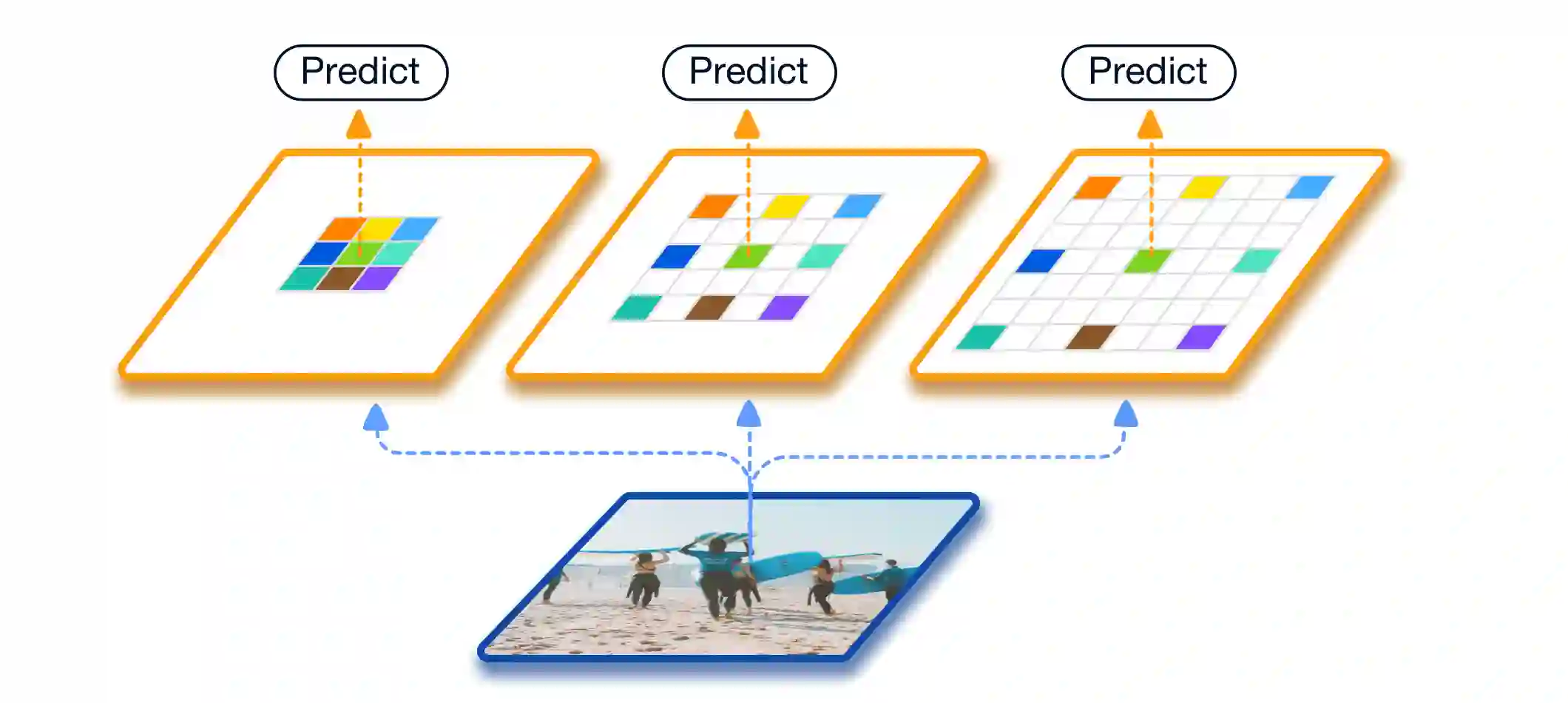
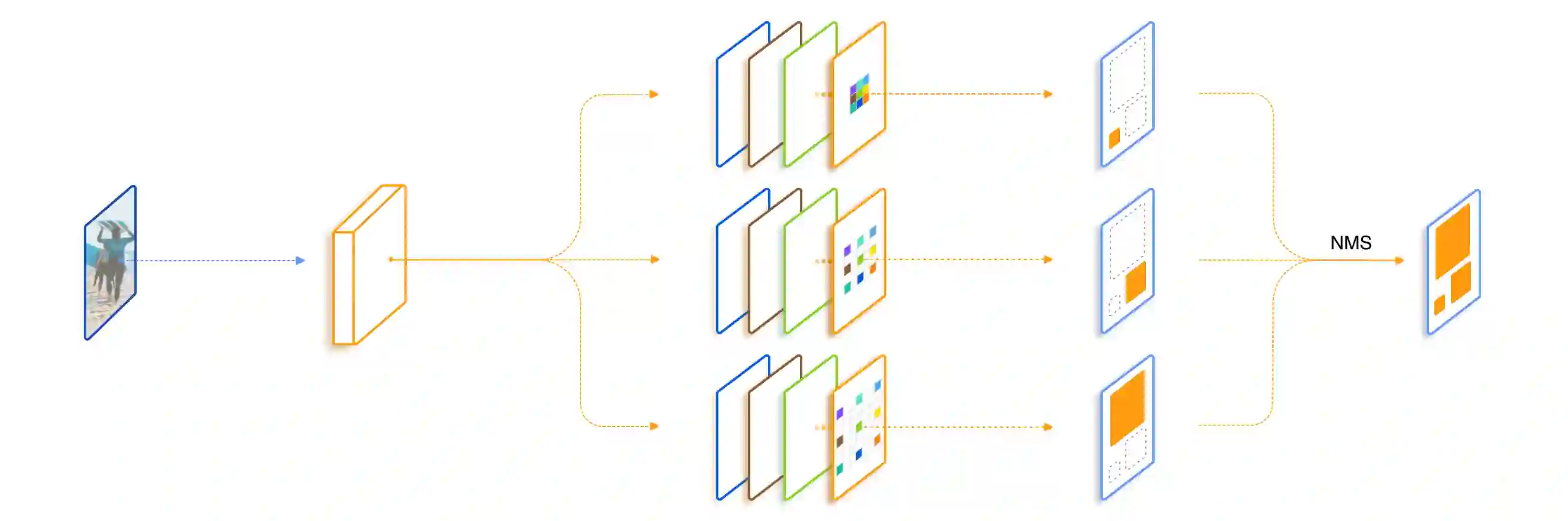
Scale variation is one of the key challenges in object detection. In this work, we first present a controlled experiment to investigate the effect of receptive fields on the detection of different scale objects. Based on the findings from the exploration experiments, we propose a novel Trident Network (TridentNet) aiming to generate scale-specific feature maps with a uniform representational power. We construct a parallel multi-branch architecture in which each branch shares the same transformation parameters but with different receptive fields. Then, we propose a scale-aware training scheme to specialize each branch by sampling object instances of proper scales for training. As a bonus, a fast approximation version of TridentNet could achieve significant improvements without any additional parameters and computational cost. On the COCO dataset, our TridentNet with ResNet-101 backbone achieves state-of-the-art single-model results by obtaining an mAP of 48.4. Code will be made publicly available.
翻译:比例变异是物体探测方面的主要挑战之一。 在这项工作中, 我们首先提出一个受控实验, 以调查接收字段对探测不同比例天体的影响。 根据探索实验的结果, 我们提出一个新的三叉戟网络( Trisid Net), 旨在生成具有统一代表力的大小特征地图。 我们建立一个平行的多部门结构, 每个分支共享相同的变换参数, 但与不同的可接收域共享。 然后, 我们提出一个有比例的培训计划, 通过取样对象对每个分支进行特殊化, 以适当规模的培训。 作为奖励, 三叉戟网络的快速近似版本可以在不增加参数和计算成本的情况下实现重大改进。 在 COCO 数据集上, 我们拥有 ResNet- 101 骨架的三叉式网络通过获得48.4 的 mAP, 将公布最新的单一模型结果。 代码将公布于众。