图像分类:常用分类网络结构(附论文下载)
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
TeddyZhang:上海大学研究生在读,研究方向是图像分类、目标检测以及人脸检测与识别
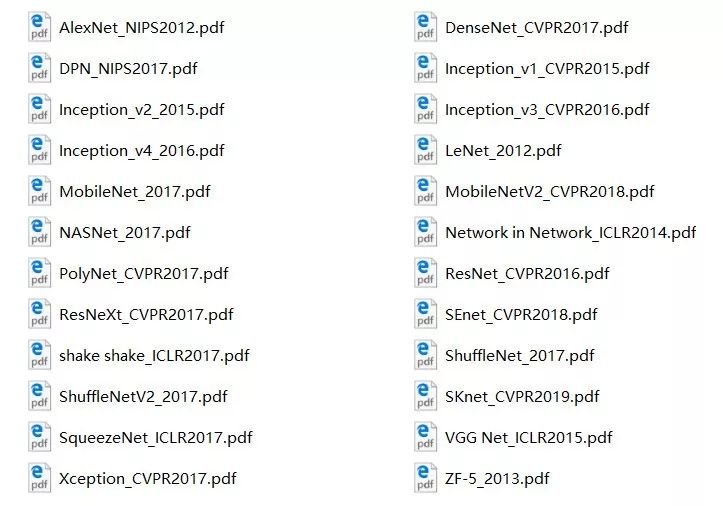
本文整理了一般常用的图像特征提取网络,下图是笔者整理的近年来图像分类网络的论文以及所在期刊,在极市平台公众号后台回复“图像分类”即可获取下载链接。
下面来介绍几种常用于分类问题的DNN,以及各自的特点,提取特征的新思路!对于以后做研究或者分类任务有很大的用处!本文篇幅较长,建议收藏阅读~
(一)VGG Net、ResNet、ResNeXt、DenseNET、SE-Net
VGG Net (ICLR2015)
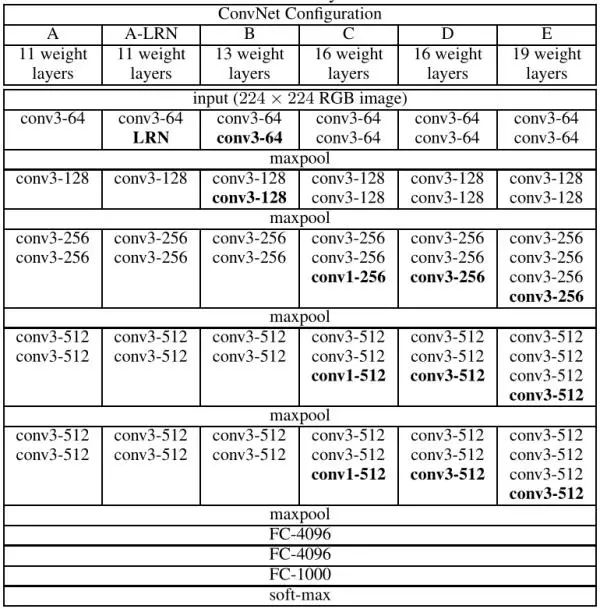

在VGG Net中,作者探讨了7x7的卷积核和3x3的卷积核的区别?那么我们使用3x3的卷积核,得到了什么呢?第一,利用三个非线性的激活层来代替一个,可以增加网络的鉴别能力,第二,单个7x7卷积核的参数量为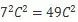
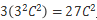
ResNet (CVPR2016)
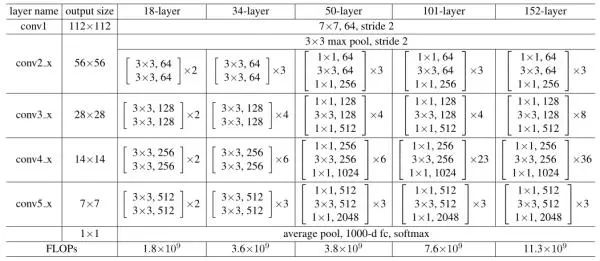
ResNet由何凯明等人提出,为了去构建更加深的网络而提出的。从历届ImageNet冠军看出,神经网络的层数是越来越多,那么更深的网络其性能就更好么?实验发现并不是这样,当网络层数过多后,会出现梯度消失的问题,从而网络会饱和导致精度下降。
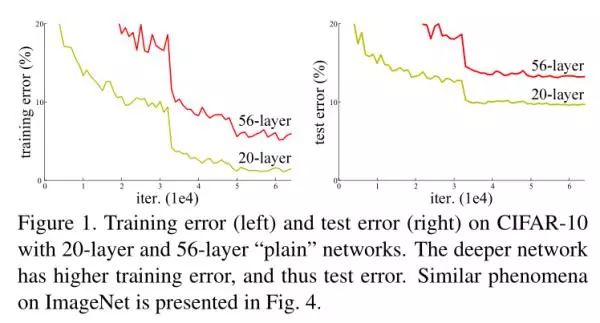
所以作者提出了一种跳过连接的方式来解决这个问题,也就是我们把输入跨层连接到下一层,通过网络的训练让其更加关注网络之间的变化,即残差。
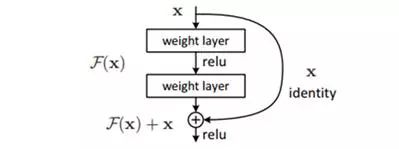
对于输入输出维度一致的,我们可以直接使用H(x)=f(x)+x来进行连接,如果维度不一致,也就是进行降采样的时候,会使用1x1的卷积核去调整维度以及feature map的大小!
最后的resnet的效果图,非常的漂亮!
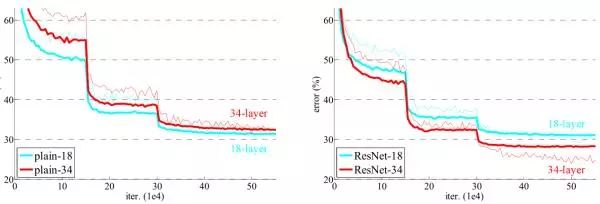
ResNeXt (CVPR2017)
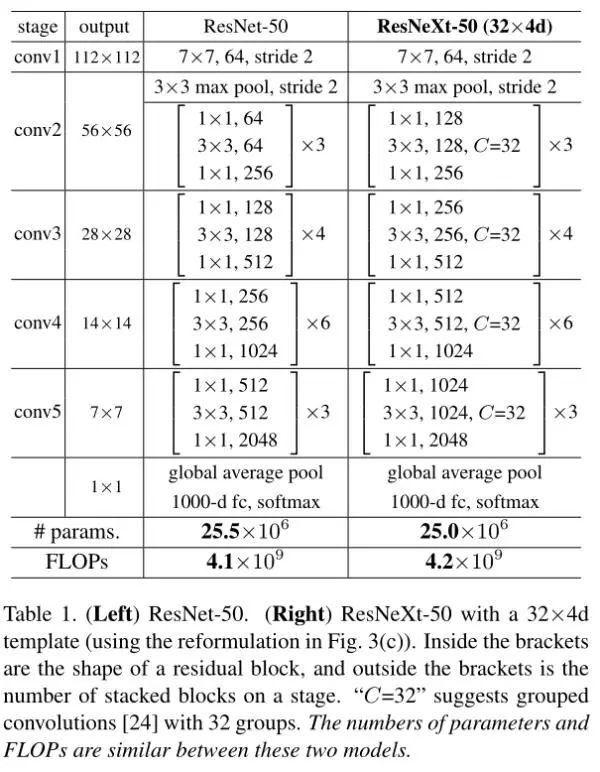
之前的ResNet关注的更多的是网络的深度,而同一时期的Inception系列关注更多的是网络的宽度,所以ResNeXt也开始在网络宽度上进行探索,并引入了一个cardinality的概念,主要利用的是分组卷积,什么是分组卷积呢?我们通过两张图片来感受一下:
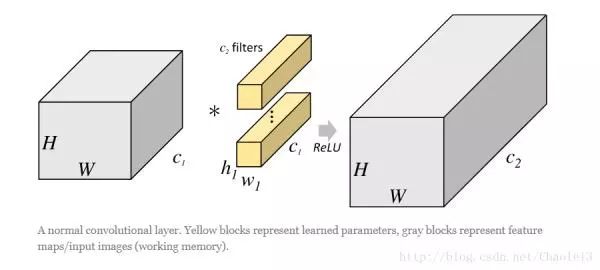
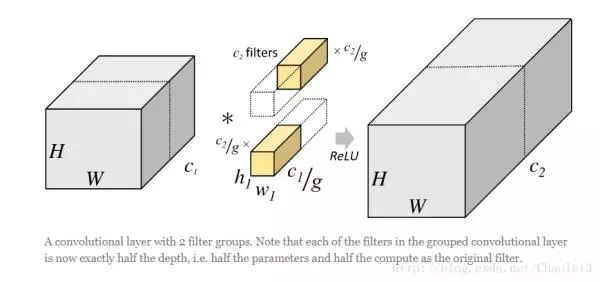
我们可以明显的看出,经过分组卷积后,参数量减少了,举一个例子,假如一个卷积层输入通道为256,输出通道也为256,正常卷积的话,参数量为256x3x3x256。但是如果进行分组卷积且组数为8的话,那么每个组卷积的输入和输出通道均为32,共8组,那么参数量为8x32x3x3x32,参数量降低了8倍。然后将每个组的输出进行concate,这样可以增加卷积核之间的相关性,并防止过拟合。当然这个分组处理的方式还很多,不限于concate。
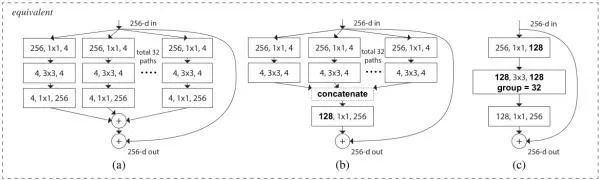
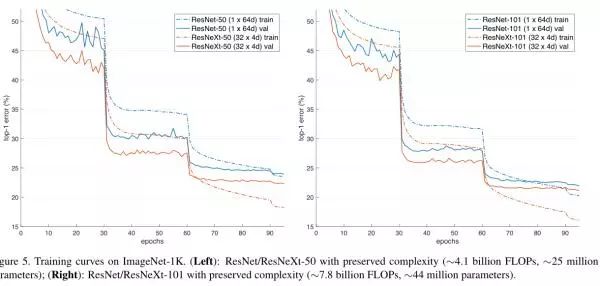
如上图,最后一种为分组卷积的方式,前面两种也是作者尝试的两种结构。一般我们设置cardinality C=32, d=4,那么参数量为:
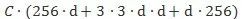
我们经常见的ResNeXt-101(32x4d)就是深度为101的上面的网络结构。
DenseNet(CVPR 2017)
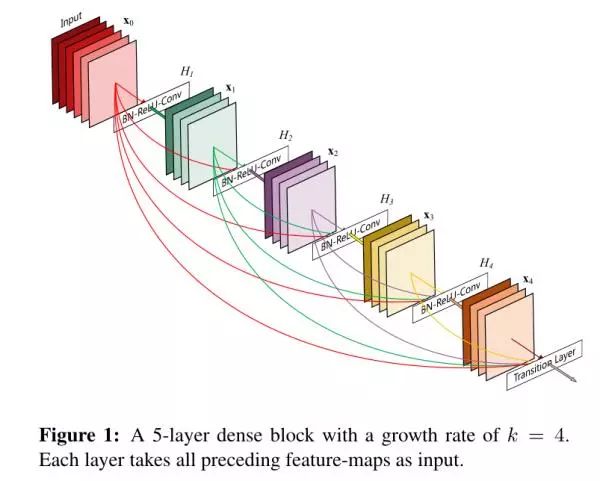
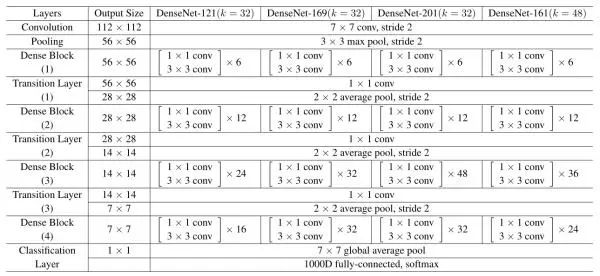
本篇论文从图中可以看出,是对ResNet进行了改进,作者总结了一下近几年的文章,在提高网络性能方面要么网络越深,要么网络越宽,但作者使用了一个更为激进的特征重用策略,把ResNet的单层特征重用扩展到多层,但参数量更少。相比于ResNet,其有很多优点,比如多层直接连接加强了特征的传递,减轻了梯度消失的现象,减少了参数量!正是因为参数量的减少,其具有一定的防止过拟合的能力!
在ResNet中,一层的输出直接与其输入相加:
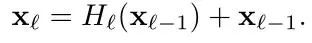
而,在DenseNet中,用concat的方式来替代相加的方式:
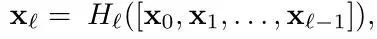
作者认为直接相加的方式会阻碍信息在网络的流动,所以很简单的实现就是将所有的feature map直接拼接。但这种直接的拼接方式会使得最后得到的featuremap通道数急剧增加,因此作者并没有将这种方式应用到整个网络,而是设计成Dense Block,整个网络方式如下图:

第一个图中的growth rate也就是k,是指每个函数产生k个featuremap, 所以第 L 层就会有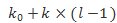
1. Bottleneck Layers, 把每个卷积层设计成效率更高的形式,也就是先使用1x1的卷积核进行降维到4k的feature map,然后再送进3x3的卷积中,即BN-ReLU-Conv1x1-BN-ReLU-Conv3x3的结构,注意这是在DenseBlock内进行参数缩减,称为DenseNet-B
2. Compression,在每个DenseBlock相连接的地方,即transition layers,加入一个DenseBlock输出m个feature map,那么我们使用transition中的1x1卷积使其输出为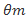
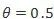
3. DenseNet-BC为两者操作均有的DenseNet
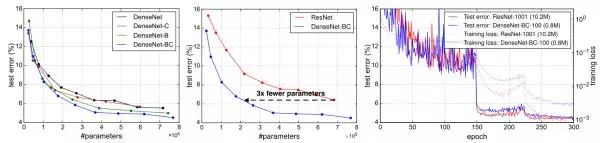
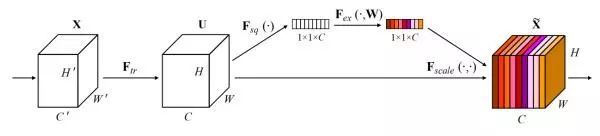
SE-Net (CVPR2018)
SE的全称为Sequeeze-and-Excitation,SE block并不是一个完整的网络结构,而是一个子模块,可以嵌入到其他的分类或者检测模型,其思想核心是通过网络根据loss函数去学习特征权重,使得有效的feature map权重大,而无效的小一些,从而使得模型精度更高。
那么SE block是怎么去衡量featuremap的权重呢?其主要包括Squeeze和Excitation两个部分,下面是其结构图:
1. 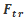
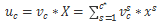
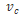
2. 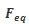
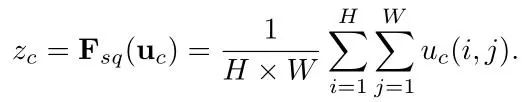
经过这个操作后,一个的张量就变成了
3. 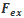
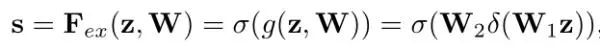

4. 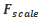
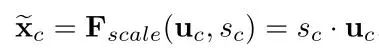
可以看到,SE block还是十分强力的,厉害~~
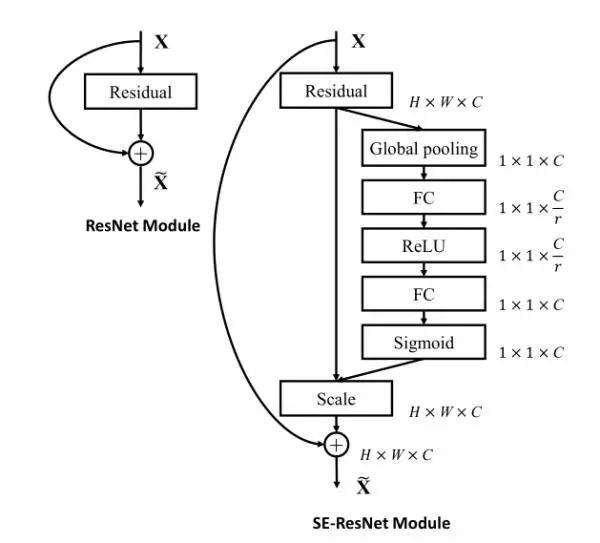
下图为SE-resnet的结构示意图:
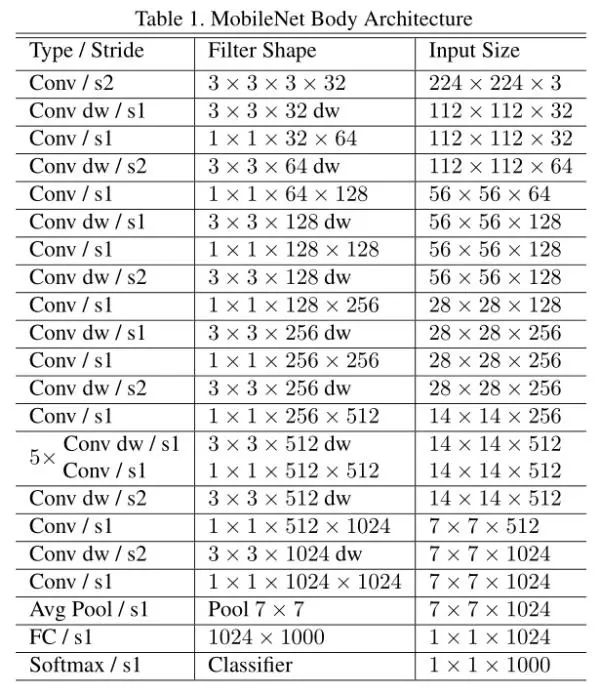
MobileNet (2017)
本篇文章是关于网络加速的问题,如何在保持精度的同时,使网络的速度大大提升,从而可以达到速度和精度的tradeoff,其论文主要提出了一个深度可分离卷积的方式(Depthwise Separable Convolutions),可以大大降低参数量!
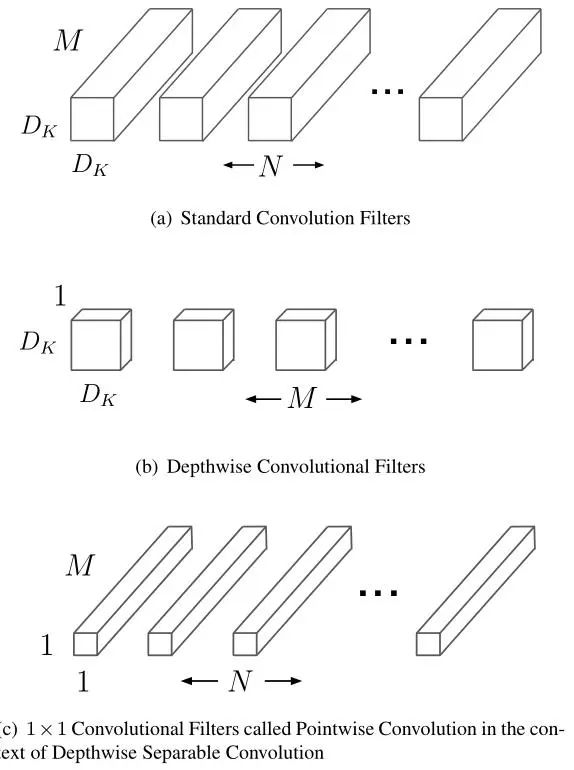
假设我们使用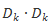
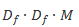
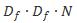
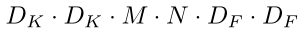
而对于可分离卷积来说,首先进行一个depthwise conv(逐通道)的操作,即分别对输入图像的每一个通道进行卷积,每个卷积核的输出也是单通道,所以需要 M个 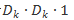
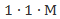
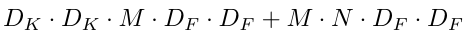
这样的话,其参数量由原来的相乘变为相加,即降低参数量百分比为
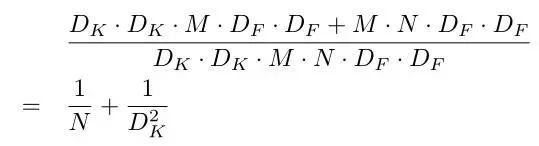
depthwise操作其实质就是一种G=输入通道数的特殊分组卷积!!!
对比传统卷积,其网络结构的变化为:
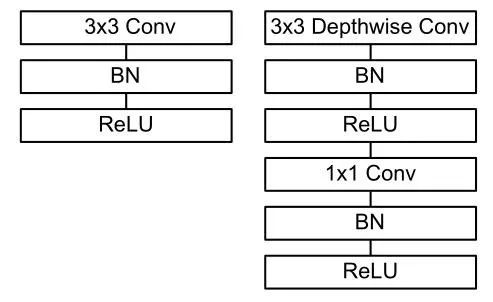
MobileNet的网络框架为:
MobileNet V2 (CVPR2018)
通过上面的讲解,我们都知道了使用深度可分离卷积可以使得参数量大大降低,加入Kernel的大小为3x3,那么相比传统卷积可以降低8到9倍的参数量!
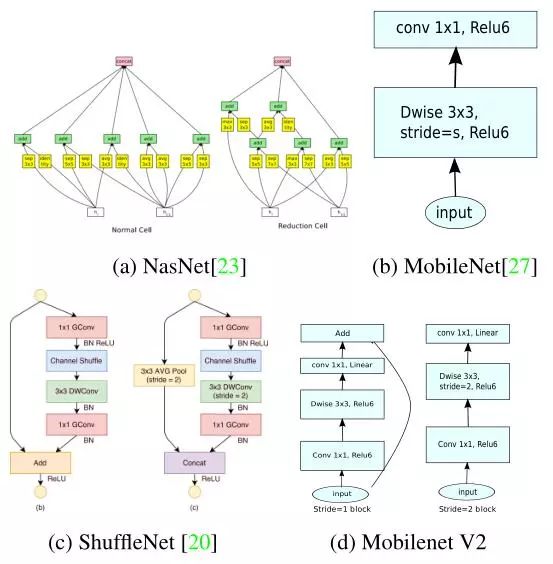
但是MobileNetV1的结构设计过于简单,后续的很多网络证明了复用特征的有效性,如ResNet和DenseNet, 所以在网络结构上面有很大的改进性!1. 因此作者重新设计了一个Inverted Residual block并加入了跳过连接的方式。2. 使用了Linear Bottlenecks,作者在实验中发现非线性激活层在低维空间容易改变输入的数据结构,但Depthwise的操作正是低维空间,所以要去掉最后的非线性激活层,并在Depthwise前加入一个线性结构,保持模型的表达能力。
下图为ReLU函数在不同维度下的输入,可以看到dim=2或3时变形很厉害。

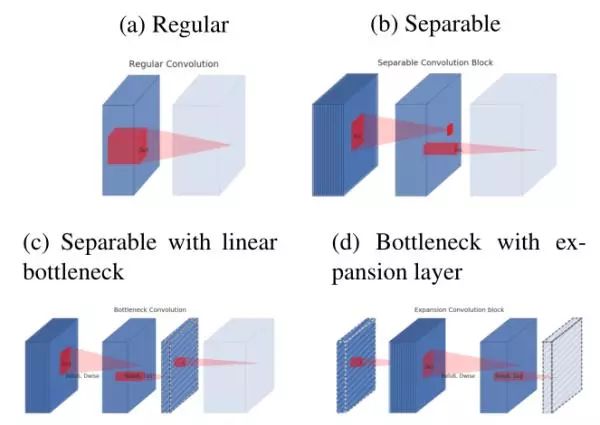
总的来说:如果manifold of interest经过ReLU激活后仍然非零,那么这就相当于一个线性操作,ReLU也是有能力保留全部的输入空间的信息,但仅仅是输入空间的低维子空间。
根据上面的原因,作者建议通过插入Linear Block到卷积层,从而保留非线性的同时避免丢失太多的信息。因此MobileNet V2中的Block在卷积层中加入了Linear Block,然后还有跳过连接的方式。接着作者又探讨了上图C和D两种结构的优劣性,也就是Linear Block放在那里的问题!下图为实验结果:
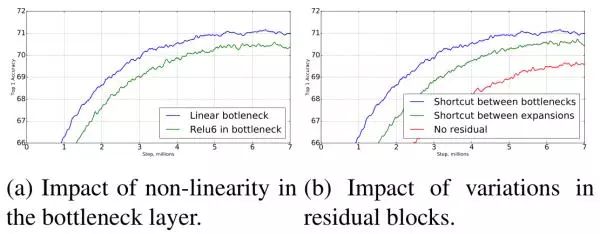
实验证明,加入Linear Block的有效性,并且C图的结构形式优于D图的结构形式,即

ShuffleNet (2017)
在讲解这篇文章之前,我们首先回顾一下group convolution,它最早由AlexNet提出,当时是由于计算能力不足,然后在ResNeXt中,作者也使用了分组卷积的方式来降低参数量,并增加网络的宽度,效果也很不错!接着我们在说下depthwise convolution, 其在MoblileNet中得到了使用,作者想讲这两种操作相结合,以达到更低参数量的同时精度也能保持的目的。
作者分析了下ResNeXt网络,发现其GP Conv只用在了3x3的layer中,这样就导致了一个残差模块中93.4%的计算量都在pointwise convolution, 对于一个比较小的网络,为了降低这种操作的运算量,只能减少通道数,但有可能会导致精度下降,因此,作者提出:
把GP Conv也应用到pointwise convolution, 也就是分组后的卷积核为单通道的卷积核!
但这是就会出现一个问题,就是通道之间某个通道输出仅从一小部分输入通道中导出,我们都知道MobileNet中的Pointwise就是为了融合通道间的信息的,如下图所示,这样的属性降低了通道组之间的信息流通,降低了信息表示能力。所以作者又设计了一个channel shuffle的结构,用于交换通道组之间的信息!
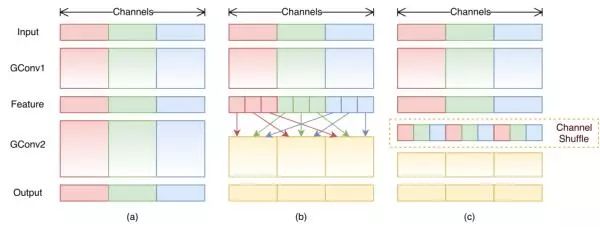
channel shuffle具体实现:假设有gxn个通道,首先将其reshape成(g, n),然后再转置为(n, g), 进行flatten操作,再分为g组作为下一层的输入!
但是有个问题,就是GP Conv的pointwise的操作是无法改变通道数的,那shufflenet的通道数在不同的Stage是如何增加的呢? 很简单,Concat~~
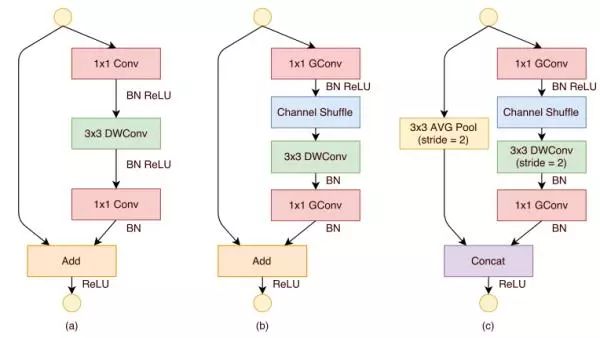
我们可以看到,ShuffleNet在每个Block也都是用了LinearBlock,即最后的输出没有ReLU, 然后利用了分组卷积,在Stride=2时,使用Concat操作将通道数增加为原来的2倍!
网络结构:
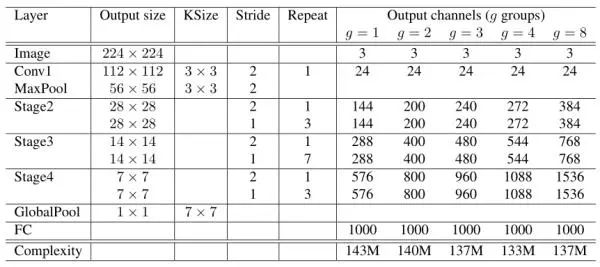
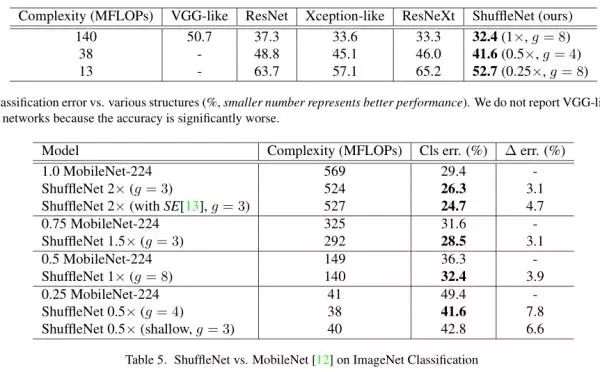
模型参数量和精度比较:
ShuffleNet V2(2018)
这篇论文十分的精彩,基本上没有任何的理论推导和解释,而是通过大量实验进而总结得到的结论,都是立足于实际,用实验结果来说话!
最终得到了设计轻量化网络结构的四个准则:
G1 : 当输入、输出channels数目相同时,conv计算所需的MAC(memory access cost)最为节省
下面公式为MAC和FLOPS,也就是B之间的公式关系,其中
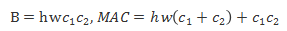
从而其联系为
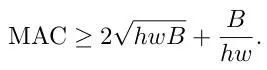
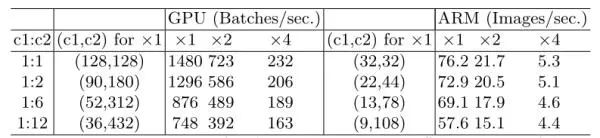
G2 : 过多的分组卷积会增加MAC
对于1x1的分组卷积,其MAC和FLOPS的关系为:
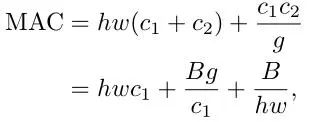
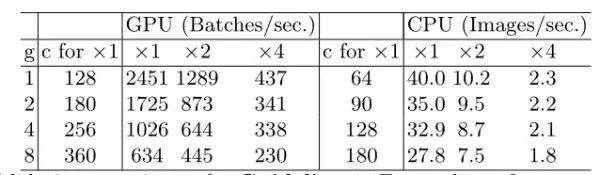
G3 : 网络结构整体的碎片化会减少其可并行计算时间,但在ARM中效果并没有那么好
可以看出碎片化对GPU下的提升还是较为明显的,而CPU并没有明显的提升
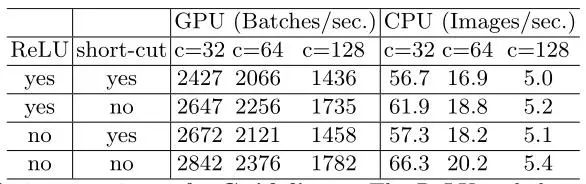
G4 : Element-wise操作会消耗较多的时间, 也就是逐元素操作
从表中第一行数据看出,当移除了ReLU和short-cut,大约提升了20%的速度!
我们来回顾下ShuffleNet V1:
在第一版中,应用了两种技术:pointwise group convolution和bottlenect-like,接着使用了一个channel shuffle的模块用来增加通道之间的交流性同时提高精度。那么根据我们上面提出的四个CNN高效化设计的准则,第一版有什么不足呢?
首先它使用了bottleneck 1x1 group conv与module最后的1x1 group conv pointwise模块,使得input channels数目与output channels数目差别较大,违反了G1和G2。其次由于它整体网络结构中过多的group conv操作的使用从而违反了G3。最后类似于Residual模块中的大量Element-wise sum的使用则进而违反了G4。因此作者在ShuffleNet V2中避免了这种操作!
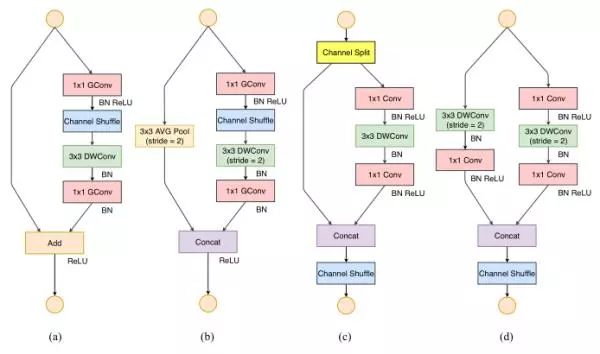
上图就是ShuffleNet V1和V2的比较,前面两个为第一版的结构图,可以看出,第二版为了效率舍弃了原来的pointwise的分组卷积形式,改成普通卷积。为了避免BasicBlock中最后element-wise sum的操作,引入了channel split首先将通道分成两半,进入两个支路,最后使用Concat操作来代替原来的sum操作,既保持了通道数量的不变性又避免了element-wise的操作!太厉害了!进行Concat操作后,接着跟着一个channel shuffle的模块,用于通道间的信息交流!
在这里面3x3 Depthwise操作相当于线性操作,没有加ReLU,这不同于MobileNet V2,其是1x1的pointwise操作中没有ReLU,充当线性层!
网络结构
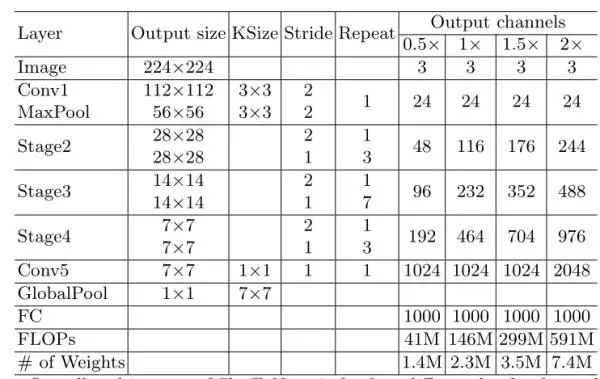
在大模型上面的对比:

以上为笔者整理的常用分类网络结构,也欢迎大家留言补充,一起学习交流~~
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~