子图检索增强的知识图谱问答方法 | 论文荐读
论文标题:
Subgraph Retrieval Enhanced Model for Multi-hop Knowledge Base Question Answering (ACL2022)
作者:
张静(中国人民大学),张晓康(中国人民大学),于济凡(清华大学),唐建(魁北克人工智能研究所),唐杰(清华大学),李翠平(中国人民大学),陈红(中国人民大学)
论文代码与 pdf:
https://github.com/RUCKBReasoning/SubgraphRetrievalKBQA
知识图谱问答致力于基于百科知识图谱数据回答客观事实问题。目前的两种主流方法包括语义解析法和表示学习法。前一种着眼于将自然语言问题解析为诸如 SPARQL 之类的逻辑表达式,其优点在于能够解决多样的复杂问题,但是会过度依赖于标注的逻辑表达式。为了克服这个缺陷,表示学习法直接对图中的实体进行表示和排序。在这类方法中,从全图中先抽取问题相关的子图,再在子图上推理答案的表示学习方法表现出显著的优势。实验表明,子图的质量极大地影响整体问答的效果。子图太小极其容易漏掉答案,太大又会引入过多的噪音。已有工作例如 PullNet 提出对子图检索模块进行训练,以提升检索到子图的质量。但是其检索与推理模块是交织在一起进行的。具体来说,在每一步中,检索器选择与问题相关的知识图谱关系,同时推理器推理决定该关系的哪个尾实体需要被扩展到子图中。检索与推理的交织导致推理器的训练和推理过程都需要在中间不完整的子图上进行。由于中间子图的监督信号通常是缺失的,不完整子图上的推理会增加偏差,影响到最终推理的效果。
本文提出一种子图增强的知识图谱方法,其核心思想是子图检索模块与推理模块是解耦的。具体地,子图检索器被设计为一个高效的双编码器,通过自动扩展路径的方法来归纳子图。当检索得到子图后,任何面向子图的知识图谱问答模型都可以应用到该子图上进行答案推理。解耦合的设计使得推理仅在完整的子图上进行,并且提供了一个可插拔的框架来支持任何面向子图的推理器。图 1 展示了整个子图检索的过程。
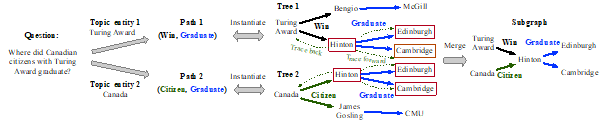
图 1: 子图检索过程。给定问题和主题实体,从主题实体开始扩展路径,由路径归纳树,最后将扩展自不同主题实体的树合并为图。
为了有效训练提出的检索器,采用弱监督训练,无监督训练以及与端到端训练的方式。弱监督采用主题实体与答案之间的最短路径作为近似监督信号。无监督采用关系抽取的数据集来构建问答伪标签。端到端的核心思想是利用推理器的反馈指导路径的扩展。尽管两个模块是联合训练的,但推理始终在整个子图上进行。图 2 展示了整个训练的过程。
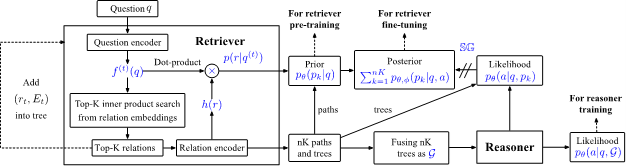
图 2:子图检索器的训练过程。给定问题,子图检索器抽取 nK 条路径。首先基于每条路径的先验概率预训练子图检索器,然后基于路径融合产生子图的似然概率训练推理器。最后进行端到端训练时,检索器基于每条路径的后验进行微调,其中后验概率包含先验概率和私然概率。
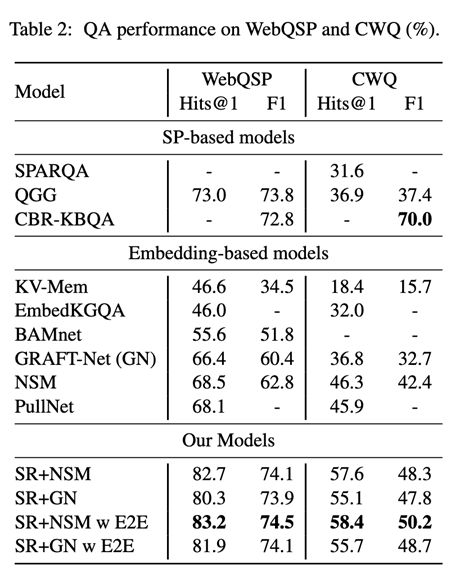
我们在 2 个公开数据集 WebQSP 和 CWQ 上进行了实验,结果表明:(1)将提出的子图检索器结合经典的图推理器模型 NSM,在知识图谱问答上取得新的最佳效果;(2)为得到相同的答案覆盖率,提出的子图检索器能够产生更小的子图并得到更优的问答效果;(3)无监督预训练搭配 20% 的弱监督信号能够媲美全部弱监督训练;(4)端到端微调能够同时提升检索器与推理器的效果。
点击【阅读原文】查看paper


