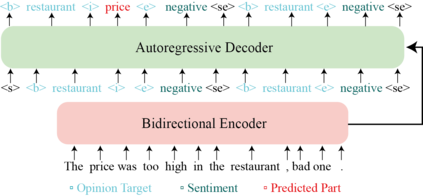
Since previous studies on open-domain targeted sentiment analysis are limited in dataset domain variety and sentence level, we propose a novel dataset consisting of 6,013 human-labeled data to extend the data domains in topics of interest and document level. Furthermore, we offer a nested target annotation schema to extract the complete sentiment information in documents, boosting the practicality and effectiveness of open-domain targeted sentiment analysis. Moreover, we leverage the pre-trained model BART in a sequence-to-sequence generation method for the task. Benchmark results show that there exists large room for improvement of open-domain targeted sentiment analysis. Meanwhile, experiments have shown that challenges remain in the effective use of open-domain data, long documents, the complexity of target structure, and domain variances.
翻译:由于以往关于开放域目标情绪分析的研究在数据集域多样性和刑期层面有限,我们提议建立一个由6,013个人类标签数据组成的新数据集,以扩展感兴趣和文件层面的数据领域;此外,我们提供一个嵌套目标注释方案,以提取文件中的全部情绪信息,提高开放域目标情绪分析的实用性和有效性;此外,我们利用预先培训的BART模型,以顺序生成方法完成这项任务;基准结果显示,在改进开放域目标情绪分析方面有很大空间;与此同时,实验表明,在有效利用开放域数据、长文件、目标结构的复杂性和域差异方面仍然存在挑战。