FewRel 2.0数据集:以近知远,以一知万,少次学习新挑战

大家都知道,传统的机器学习模型需要较大的训练数据才能达到好的效果。然而我们人类从小时候起,就有看少量例子学会新事物的能力。少次学习(Few-Shot Learning)正是致力于探索模型如何能快速适应新任务的一种方式。
有一类经典的少次学习设定叫做 N-Way K-Shot:给定 N 个模型从未见过的类型,每个类型给定 K 个训练样本,要求模型能够将测试样例进行 N 分类。形象地说,这种设定要求模型“现学现卖”,先看几个例子,然后在测试集上做“选择题”,判断它们到底属于新类型中的哪一类。
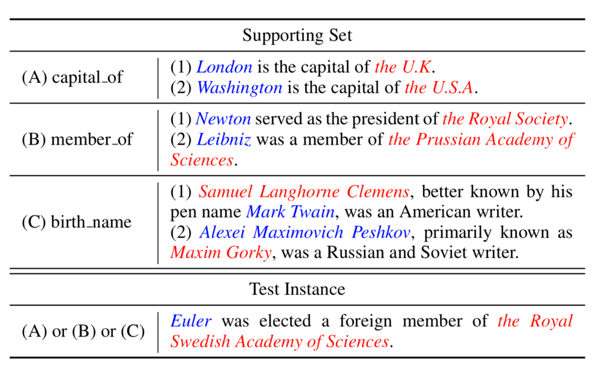
在 CV 领域,常用的少次学习数据集有 miniImageNet 和 Omniglot。而在 NLP 领域,清华大学的刘知远老师组去年发布了 FewRel——一个大规模的少次学习关系抽取数据集。该数据集仅发布一年便获得了多次引用,也有许多研究者以此为基础展开相关研究。
而在今年的 EMNLP 上,该团队又发布了数据集的升级版:FewRel 2.0。相关论文已经放出(https://arxiv.org/abs/1910.07124)。和 1.0 相比,FewRel 2.0 又有哪些区别呢?

两大新挑战
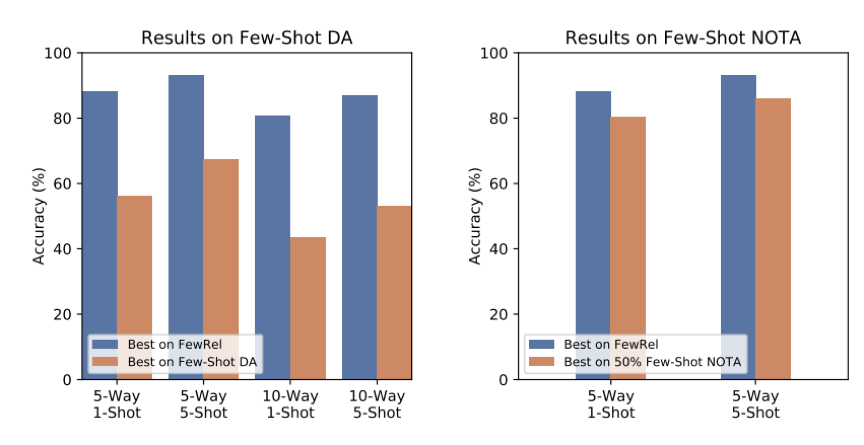
在 FewRel 2.0 中,作者提出了两大少次学习新挑战:跨领域和“以上都不是”(无答案问题)。作者表示,以往的少次学习模型都不能很好的解决这两大问题,虽然他们提出了两个新模型,效果得到了一定的改善,但在这两个挑战上,仍有巨大的上升空间。
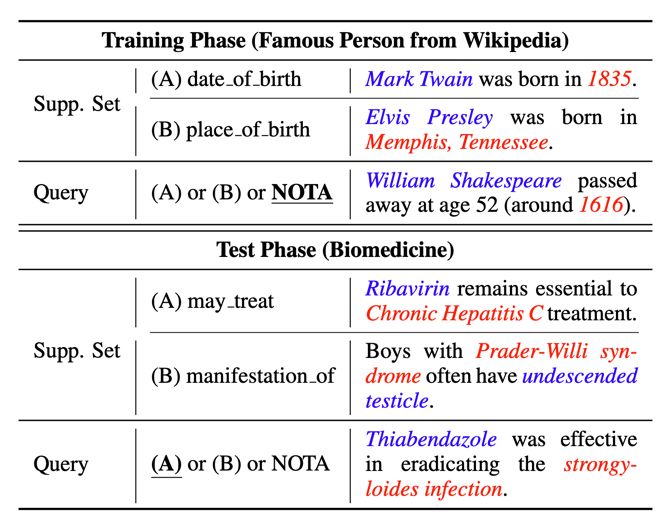
▲ 一图看FewRel两大新挑战
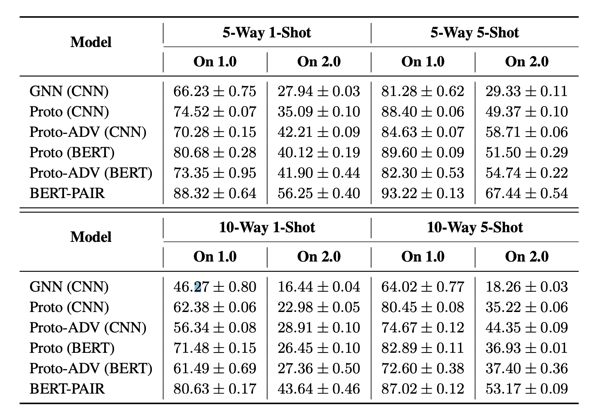
▲ FewRel 1.0和FewRel 2.0测试结果对比,可看出跨领域任务十分具有挑战性
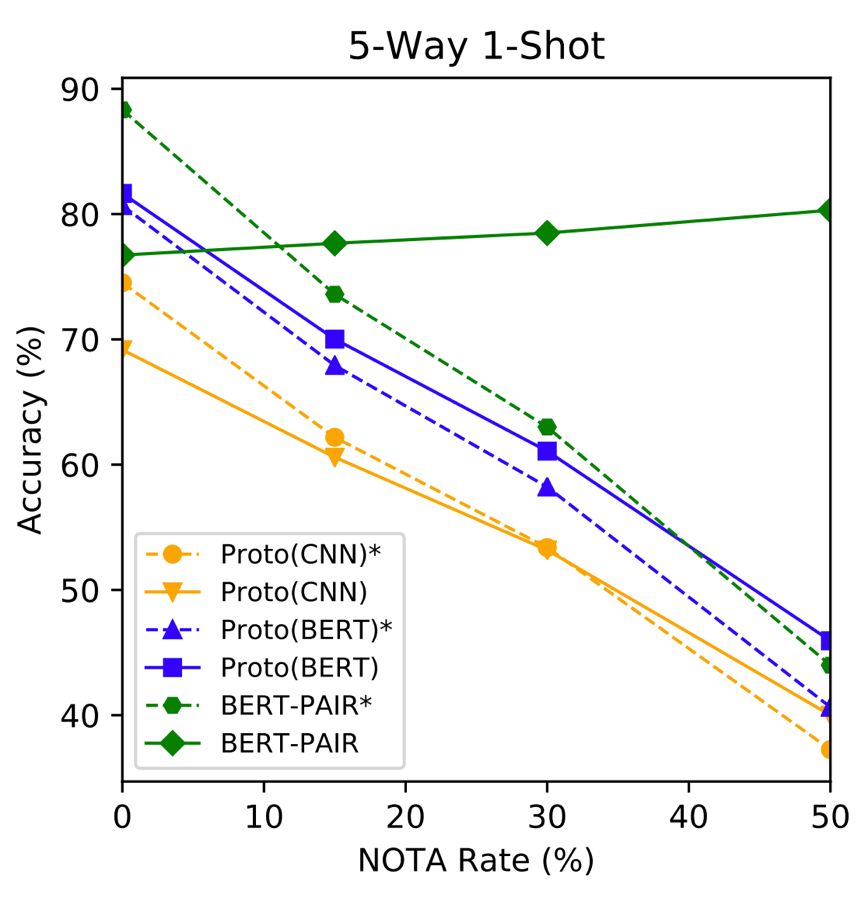
更多信息
总结来说,FewRel 2.0 相比 1.0 版本增加了两个挑战:跨领域和“以上都不是”。经典模型在这两个挑战面前的表现都不尽人意。尽管作者在论文中提出了可能的解决方案和模型,但表现仍然有较大的提升空间。
最后,数据集的论文(https://arxiv.org/abs/1910.07124)和Github项目(https://github.com/thunlp/fewrel)均已放出,论文中提到的模型也都包括在内,感兴趣的同学可以到他们的 Github 主页和论文中了解更多信息。
关于作者

PaperWeekly携手图灵教育
送出5本PyTorch入门宝典

从零到一,真正实现 PyTorch 深度学习入门。本书浅显易懂,图文并貌地讲解了深度学习的基础知识,从如何挑选硬件到神经网络的初步搭建,再到实现图片识别、文本翻译、强化学习、生成对抗网络等多个目前最流行的深度学习应用。书中基于目前流行的 PyTorch 框架,运用 Python 语言实现了各种深度学习的应用程序,让理论和实践紧密结合。
长按识别下方小程序码
即可参与本次抽奖

开奖时间:11月8日 14:00
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 访问项目主页





