P-tuning v2: 提示微调方法可在跨规模和任务上与精调方法媲美 | 论文荐读
作者:
刘潇,纪开轩,伏奕澄,谭咏霖,杜政晓,杨植麟,唐杰
Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Lam Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks. In Proceedings of the 60th Annual Meeting of the Association of Computational Linguistics (ACL'22).
Code & Data:
https://github.com/THUDM/P-tuning-v2
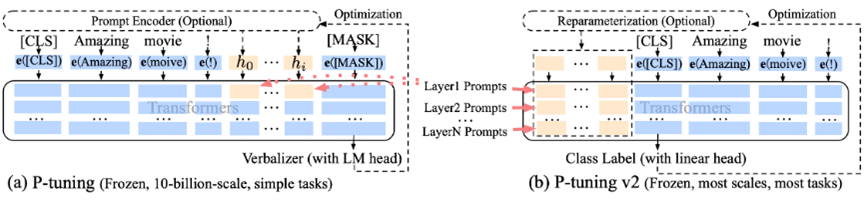
提示微调(Prompt Tuning),指只用一个冻结的语言模型来微调连续提示向量的方法,大大减少了训练时每个任务的存储和内存使用。然而,在自然语言理解(Natural Language Understanding, NLU)的背景下,先前的工作表明,以 P-Tuning 为代表的提示微调算法,在不使用精调的情况下,具有独特的规模效应:当预训练模型规模增长至 100 亿时,提示微调算法仅以 0.01% 的微调参数量,便可取得和精调一样好的迁移效果;小于 100 亿时则不然。然而,考虑到实际应用中,小于 100 亿的模型的精调成本也十分高昂,如何将 P-Tuning 算法应用到这类中小规模的模型上成为大家关注的话题。
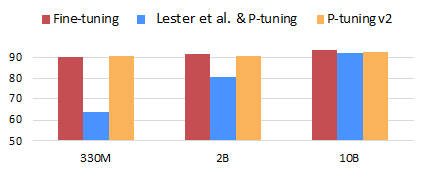
为了应对这一挑战,我们提出了基于深度提示微调思想的 P-Tuning v2 算法,将 P-Tuning 中原本只加在输入层的可学习微调向量,以前缀的形式添加至预训练 Transformer 的每一层的输入中,层与层间相互独立;同时,我们证明了在该情况下,我们可以将原本 P-Tuning 中的语义标签(只能用于文本分类任务和问答任务)替换为传统精调方法使用的下游分类器,以应用于机器阅读理解、命名实体识别和语义角色标注等更具有挑战性的序列标注任务上。实验结果表明,P-Tuning v2 在 3 亿到 100 亿参数的广阔参数规模上,均能仅以 0.1%~3% 的微调参数量,取得和精调方法媲美的迁移效果,并大大超越前代 P-Tuning 算法;在文本分类和问答到序列标注的广泛任务类型上,P-Tuning v2 也总能取得和精调方法接近的表现水平。
点击【阅读原文】查看paper



