Reformer: 局部敏感哈希、可逆残差和分块计算带来的高效

最近要开始使用Transformer去做一些事情了,特地把与此相关的知识点记录下来,构建相关的、完整的知识结构体系,
以下是要写的文章,本文是这个系列的第九篇:
-
Transformer:Attention集大成者 -
GPT-1 & 2: 预训练+微调带来的奇迹 -
Bert: 双向预训练+微调 -
Bert与模型压缩 -
Bert与模型蒸馏:PKD和DistillBert -
ALBert: 轻量级Bert -
TinyBert: 模型蒸馏的全方位应用 -
MobileBert(待续) -
更多待续 -
Bert与AutoML (待续) -
线性Transformer (待续) -
Bert变种 -
Roberta: Bert调优 -
Transformer优化之自适应宽度注意力 -
Reformer: 局部敏感哈希和可逆残差带来的高效(本篇) -
Longformer (待续) -
T5 (待续) -
更多待续 -
GPT-3 -
更多待续
Overall
随着模型的发展和对效果孜孜不倦的追求,现在的Bert/Transformer模型越来越大,单层参数量甚至达到的0.5B之多,需要2GB的内存才能放下。另一方面,需要处理的序列越来越长,之前的研究中甚至出现的11k长的序列。所以越来越多的研究者们感慨Transformer模型的训练越来越是有钱人的游戏,只有大型AI研究组织才负担得起如此昂贵的资源。
但真的如此吗?
通过我们在前面的文章中对Transformer和Bert的讲解,我们会知道,Transformer之所以大,占内存多,主要来源于三个方面:
-
模型越来越深,占用的内存基本上随深度呈线性增长。 -
Transformer块的全连接部分的中间层让宽度变四倍,占用了大量的内存。 -
Transformer块的注意力部分随着序列长度的增长而平方倍增长,当处理长度为64K的时候,只是这部分的内存显卡就放不下了。
相应的,列出了问题之后,就可以推出解决的办法。
-
针对模型层次深的问题,可以使用可逆残差来解决,这样只用在内存中维护一层网络就可以了。 -
全连接层中的计算可以分块来做。 -
通过局部敏感哈希来近似求解注意力矩阵,把O(L^2)的复杂度减为O(LlogL)从而使得在长序列上提高效率。
实验表明,这几种方法对模型的效果影响可以忽略不计,但性能却能大大提升。
回顾: attention
首先,回顾一下注意力的计算。Scaled dot-product Attention的计算公式如下,具体实现中,每个Transformer块中会有多个这样的attention,称之为多头注意力。
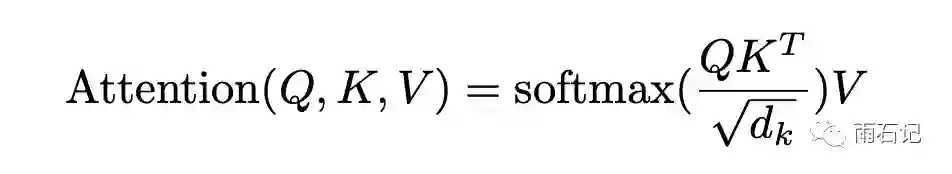
在这个注意力计算中,Q,K,V都是[batch_size, length, d_model]的矩阵,而QKT的结果则是[batch_size, length, length]的矩阵,当序列长度比较长的时候,比如64k,那么光这一项就占用16GB的内存。
一个Trick的方法来降低内存的方法是,Q和K的矩阵乘法可以拆开来做,比如计算每个qi对K中每个item的注意力。计算过程中内存覆盖,从而降低内存使用量。
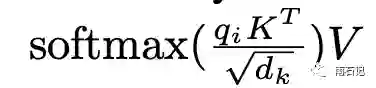
这样做的坏处就是在反向传播的时候,qi对应的注意力需要重复计算一次。
而Q,K,V是怎么来的呢?对于一个输入的向量来说,需要通过三个不同的矩阵去做变换分别得到Q,K,V。Q代表query,K和V分别代表key和value。但是通过实验可以知道,Q和K共享一个矩阵对最后的结果也不会带来损失。
局部敏感哈希和Attention的奇妙碰撞
在上文反复提到过,序列长度L的增长会带来平方级别的内存增长,因为我们需要计算Softmax,从而得到每个位置对其他位置的注意力权重。而Softmax的结果,一般是被较大的值主导,因而,当序列比较长的时候比如64K,可能模型关心的只有前64个,其他的都是长尾。基于此,问题就转化成为了找最相似的Top-N问题,而这个问题是可以用局部敏感哈希来解决的。
下图展示了使用的局部敏感哈希算法,当然,是一个二维版的,对于空间中的点,先将其投影到一个圆(2d是圆,3d是球,4+d是超球体)上,然后将分成八个区域,每个区域都代表一个独立的值。随机转动圆,记录下投影后的点所在区域的值;那么经过多次转动后,就为一个点得到了多个值,这些值就是点的哈希值。
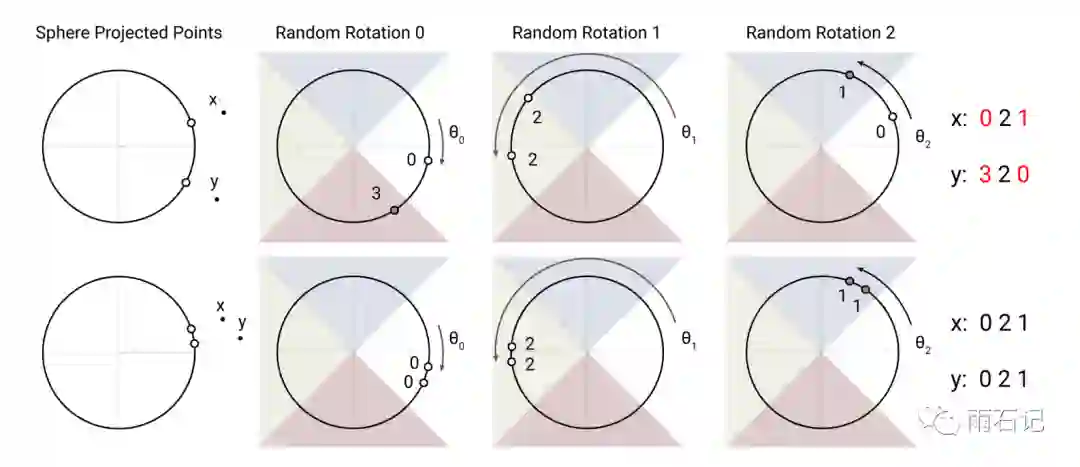
上图中的上半部分是两个不相似的点组成的例子,它们的哈希值差别很大。下半部分则是两个相似的点,它们的哈希值也是一样的。
随机旋转的参数可以定义为R,R是一个[dk, b/2]的矩阵,可以通过下面的公式得到b位的哈希值:
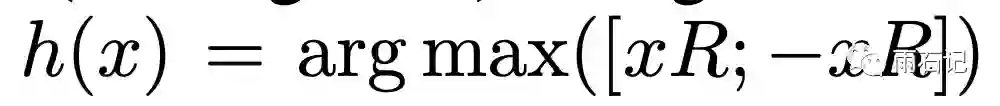
其中, [xR, -xR]代表的是拼接。
那么如何应用这个局部敏感哈希呢?
首先,我们把Attention的计算公式中的softmax给拆开,得到:
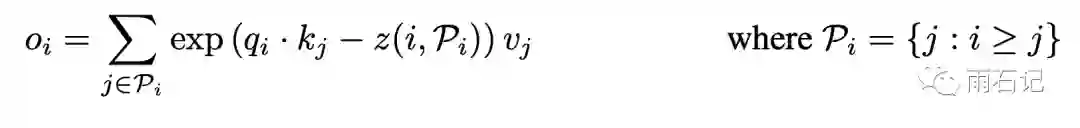
在这个公式中,引入了P,代表了某个位置i可以注意到的位置集合,在上面这个定义中,我们知道这个注意力是只能注意之前的位置。公式中的z代表的其实是归一化项,这里将其写入了exp中,拆开就是除。
更通用一些,还需要支持Mask:
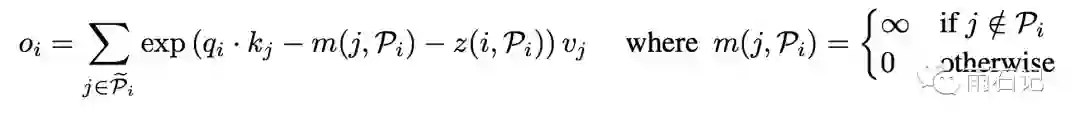
当某个位置不应该被注意时,m函数的值就是无穷大,从而得到的o就几乎为0。
而在引入局部敏感哈希之后,可以重新定义P。下面的公式表明,需要注意的位置是哈希值一样的位置。
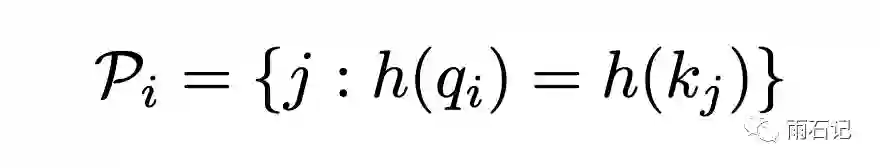
如下图所示,右图中的a图是原始的注意力矩阵,经过哈希分桶然后按桶重排序以后,可以形成如b图所示的块。
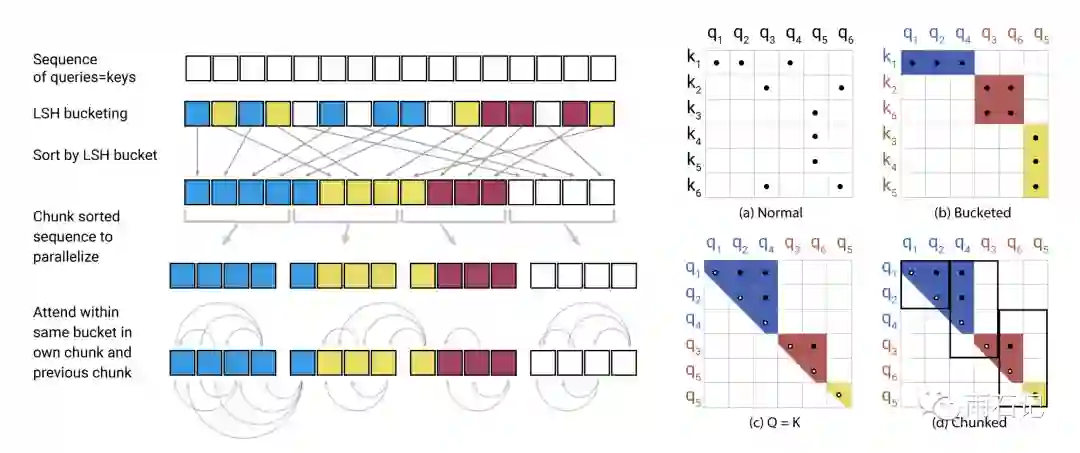
但是这样会有一个问题,那就是q和k是分开的,所以在一个桶中,可能会发生q很多但是k很少的问题,甚至,会有q很多而k不存在的问题。为了解决这个问题,这里让q和k在同一空间,即生成Q和K的矩阵是同一个,这样,对角线肯定都为1,然后经过重排序(先按桶排序,然后桶内按照原来的index排序)后,得到的注意力矩阵则是集中在对角线附近的。
由于不同的桶内的元素数目可能分布不均衡,在这里为了保证计算的均衡,采用的策略是分块,如果一个桶的元素跨块的话,则让后面的块再去attend到前一个块中的元素。如上图左图所示。
之所以只让后面的块attend前面的块,是因为论文在这里的假设是做Transformer的Decoder部分,因而后面的位置本来就不能attend前面的,而如果是Bert这种双向的,则要重新考虑这个策略。
另外,在局部敏感哈希中,随机的次数越多,得到的哈希桶就越准确,所以哈希值可以做多轮。这样,P就成为多次哈希的值的全集:
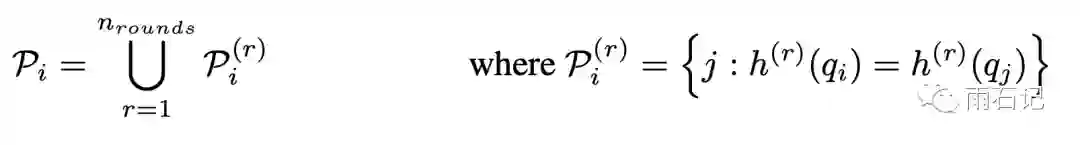
而有了LSH方法之后,内存复杂度和时间复杂度的对比如下表:

实验: 局部敏感哈希
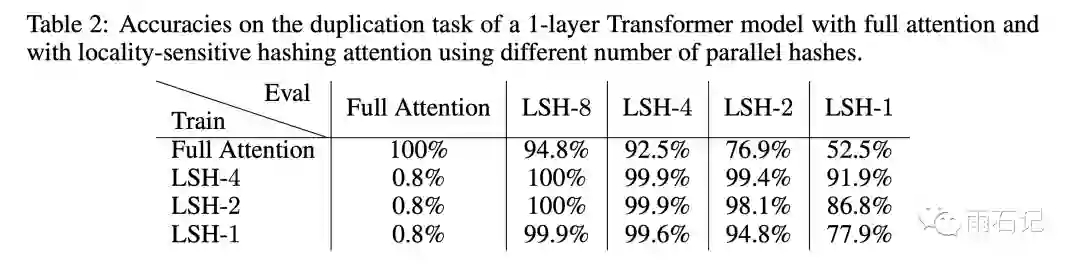
为了验证局部敏感哈希算法和attention的组合,论文采用了一个特殊的任务,那就是重复句子的单词预测。一个长为511的句子,复制一份拼接,中间用特殊字符隔开,就变成了[sep]sentence[sep]sentence,是一个长度为1024的序列。训练的时候只在后面的511个词语上计算loss和准确率。这样,因为这个句子被模型看到了,所以理论上准确率应该是100%,损失为0。
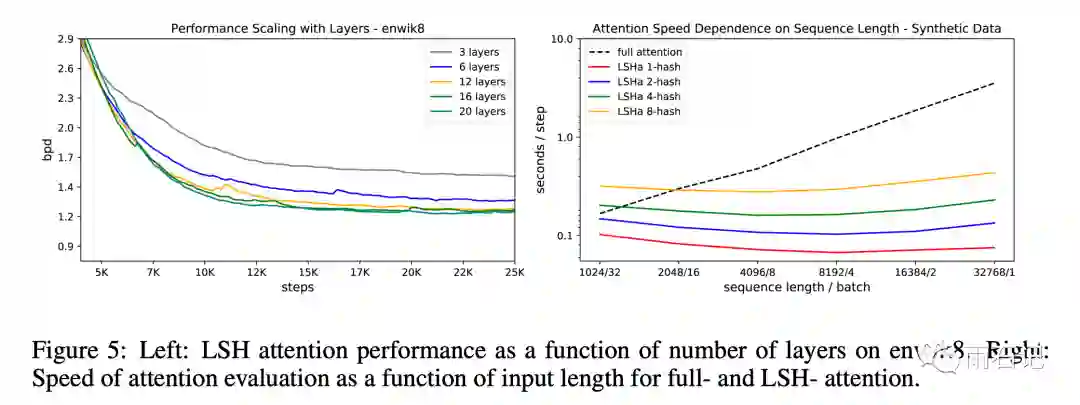
实验结果如下,可以看到,在训练的时候采用LSH,Eval的时候也采用LSH得到结果完全可以媲美Full attention。
可逆残差与Transformer
在训练网络的时候,一般需要记录每层的激活值,用来在反向传播的时候进行计算。所以每增加一层,内存也会随之增长。
为了减少多层网络所带来的内存增长,我们使用可逆残差。先看看普通的残差的计算:y = x + F(x)。可逆残差与残差很像,但它使用了一个数值对来巧妙的避免了记录每层激活值的需求,这里我们需要做的转换是从(x1, x2)到(y1, y2)。
计算方法如下:

因而,在反向传播的时候,就可以恢复某层的激活值:

而对应到Transformer中,公式则变为

分块计算
而为了解决全连接层的瓶颈问题,将全连接层分块计算,同样的,可逆残差也分块计算:

而有了可逆残差和分块计算后,内存复杂度和计算复杂度变为:

实验
首先,在两个数据集上分别做了share-QK和可逆残差的对比实验。结论是相对于原来的Transformer,基本毫无影响。
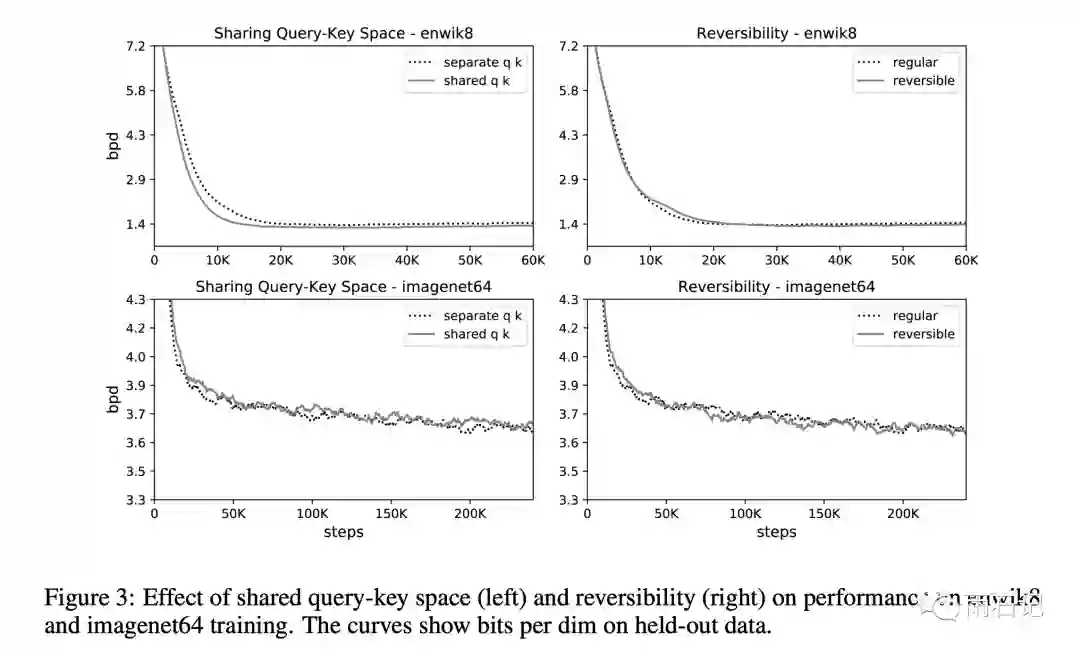
在机器翻译问题上,做了可逆残差的实验,也是相对原来transformer没有损失。

LSH和原始Transformer的对比实验:
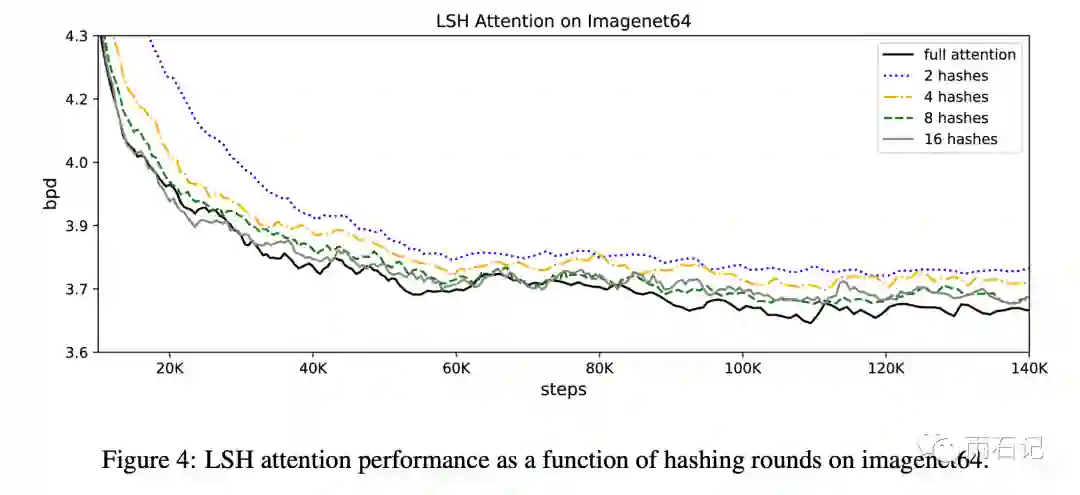
可以看到,LSH会带来些许的损失。但当序列比较长的时候,深层次的Transformer在单机上根本无法训练,而LSH可以继续训练。
总结与思考
Reformer使用局部敏感哈希、可逆残差和分块计算,把深度长序列Transformer训练的计算量和内存使用量降到了单机可训练的水平,降低了Transformer玩家的门槛,扩大了Transformer的应用空间。
多思考,勤提问是每个程序员的必备品德。
提问:
-
在局部敏感哈希的实验部分,为什么局部敏感哈希和Transformer在Train和Eval是独立的?如何理解? -
试解释文章中两个表格的算法复杂度和内存复杂度。
参考文献
-
[1]. Kitaev, Nikita, Łukasz Kaiser, and Anselm Levskaya. "Reformer: The efficient transformer." arXiv preprint arXiv:2001.04451 (2020).

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏





