
主题: A Survey of Methods for Model Compression in NLP
摘要: 近年来,基于Transformer的语言模型在神经机器翻译,自然语言推理和许多其他自然语言理解任务方面取得了实质性进展。 通过语言建模损失的变体进行自我监督的预训练意味着,在广泛的语料库上训练的模型可以提高在一系列任务上的下游性能。 但是,高参数数量和大计算量意味着BERT和友人的生产部署仍然很困难。 值得庆幸的是,在过去的两年中,已经开发出了多种技术来缓解疼痛并缩短预测时间。 特别是,本文重点介绍在基础模型预训练后应用的以下方法,以减少预测的计算成本:
- 数值精度降低
- 操作融合
- 修剪
- 知识蒸馏
- 模块更换
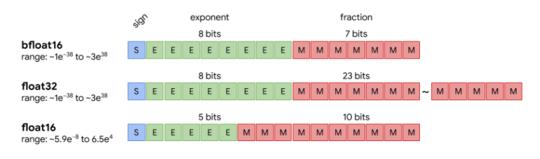
成为VIP会员查看完整内容
相关内容

专知会员服务
140+阅读 · 2020年7月10日
专知会员服务
94+阅读 · 2020年4月13日
专知会员服务
80+阅读 · 2020年3月5日
专知会员服务
99+阅读 · 2019年11月11日
Arxiv
18+阅读 · 2019年9月25日

相关VIP内容
专知会员服务
140+阅读 · 2020年7月10日
专知会员服务
94+阅读 · 2020年4月13日
专知会员服务
80+阅读 · 2020年3月5日
专知会员服务
99+阅读 · 2019年11月11日
相关资讯
相关论文
Arxiv
18+阅读 · 2019年9月25日