【一文看懂】深度神经网络加速和压缩新进展年度报告
新智元报道
来源:深度学习大讲堂
作者:中科院自动化所程健
转载编辑:克雷格
【新智元导读】在人工智能领域,深度神经网络的设计,如同绘制枝蔓繁复的兰竹,需在底层对其删繁就简;而将其拓展至不同场景的应用,则如同面向不同意境的引申,需要创新算法的支撑。中国科学院自动化研究所的程健研究员,向大家介绍过去一年,深度神经网络加速和压缩方面所取得的进展。

郑板桥在《赠君谋父子》一诗中曾写道,
“删繁就简三秋树,领异标新二月花。”
这句诗讲的是,在画作最易流于枝蔓的兰竹时,要去掉其繁杂使之趋于简明如“三秋之树”;而针对不同的意境要有发散的引申,从而使每幅作品都如“二月之花”般新颖。
其实在人工智能领域,深度神经网络的设计,便如同绘制枝蔓繁复的兰竹,需在底层对其删繁就简;而将其拓展至不同场景的应用,则如同面向不同意境的引申,需要创新算法的支撑。
1946年,世界上第一台通用计算机“恩尼亚克”诞生, 经过七十年余的发展,计算机从最初的庞然大物发展到今天的可作“掌上舞”,在体积逐步缩小的同时算力也有了很大提升。然而随着深度学习的崛起,在计算设备上可集成算法的能力边界也在不断拓展,我们仍然面临着巨大计算量和资源消耗的压力。
深度神经网络,作为目前人工智能的基石之一,其复杂性及可移植性将直接影响人工智能在生活中的应用。因此,在学术界诞生了深度网络加速与压缩领域的研究。
今天,来自中国科学院自动化研究所的程健研究员,将向大家介绍过去一年中,深度神经网络加速和压缩方面所取得的进展。
文末,大讲堂提供文中提到参考文献的下载链接。

首先我们来了解一下常用卷积神经网络的计算复杂度情况。
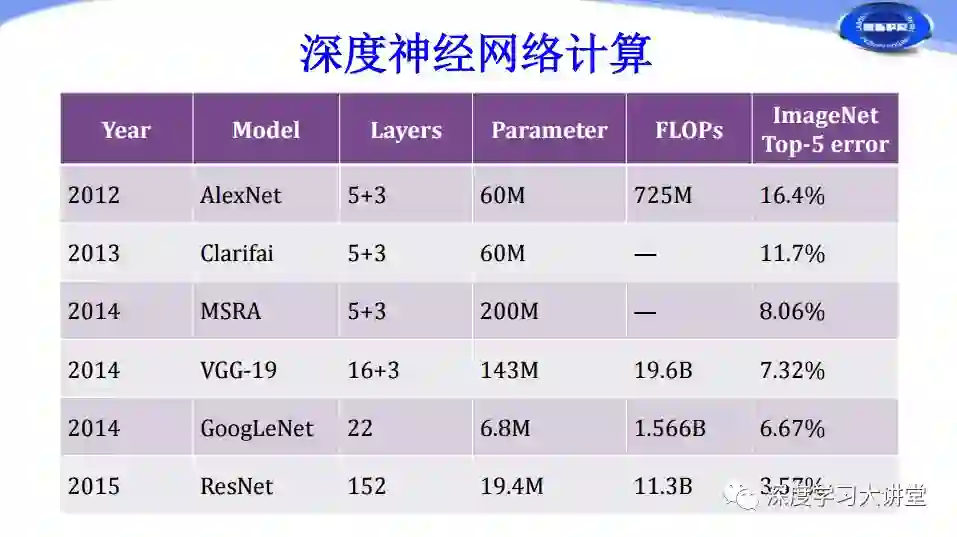
从上表可以看出近年来网络层数越来越多,计算复杂度越来越高。而过高的计算复杂度通常要求我们使用GPU或者高性能的CPU对神经网络进行运算。实际上在深度学习应用过程中,我们还面临很多诸如移动设备、嵌入式设备这样存在计算、体积、功耗等方面受限的设备,它们也需要应用深度学习技术。由于这些设备存在的约束,导致现有的高性能深度神经网络无法在上面进行有效的计算和应用。

这种情况给我们提出了新的挑战:我们如何在保持现有神经网络性能基本不变的情况下,通过将网络的计算量大幅减小,以及对网络模型存储做大幅的削减,使得网络模型能在资源受限的设备上高效运行。这正是我们做深度神经网络加速、压缩的基本动机。
从加速和压缩本身来说,两者不是同一件事,但通常情况下我们往往会同时做加速和压缩,两者都会给网络的计算带来收益,所以我们今天把它们放在一起来讲。

网络加速和压缩技术根据采用的方法不同大概可以分为Low-Rank、Pruning、Quantization、Knowledge Distillation等。目前存在很多体积比较小,性能还不错的紧致网络,在其架构设计过程中也含有很多网络加速压缩的基本思想,所以我们今天也把Compact Network Design也作为网络加速和压缩方法的一种来介绍。
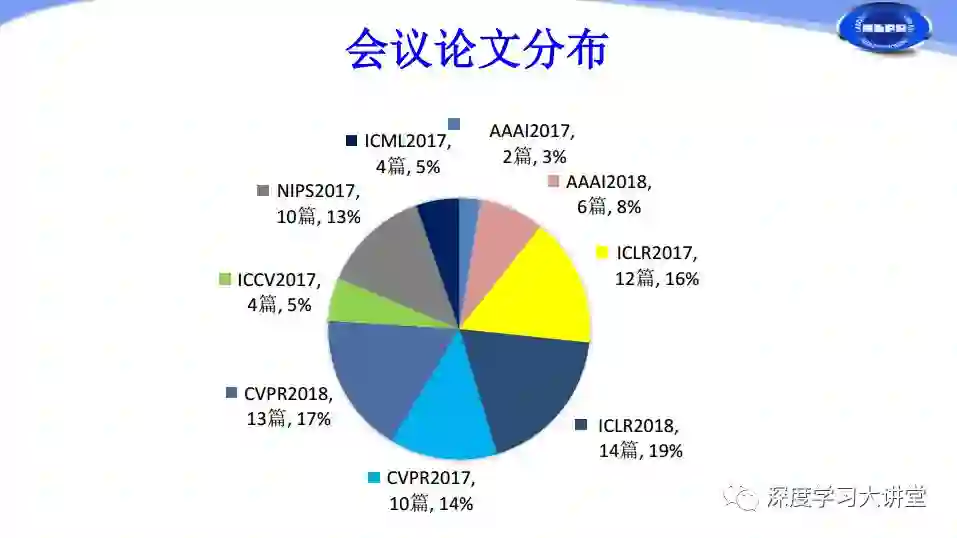
我们对过去一年和2018年目前发表在国际顶会上的有关网络加速和压缩的论文做了统计。由上图可以看出在CVPR2017有10篇关于网络加速和压缩的文章,到CVPR2018年增加到13篇文章,ICLR2017有12篇,ICLR2018增加到14篇,这是两个与深度学习应用相关的主要会议。
但奇怪的一点是我们看到也有很多文章在NIPS、ICML等相对传统、比较注重理论的会议上发表,其中NIPS2017有10篇,ICMI2017有4篇。可以说在过去一年多的时间里,深度神经网络加速和压缩不仅仅在应用方面有所突破,还在理论方面有所进展。
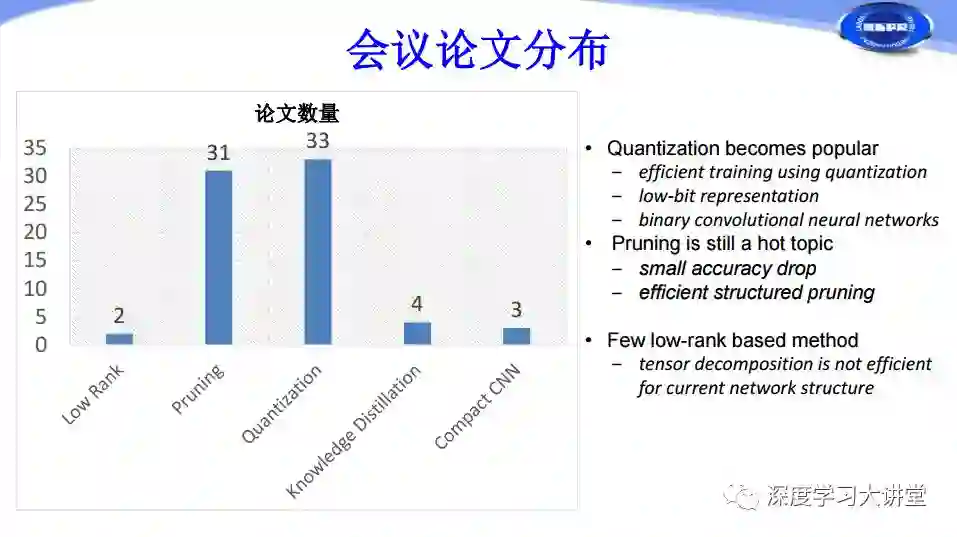
根据我们刚才对网络加速和压缩方法的分类来看,Low-Rank只有两篇,Pruning、Quantization都有三十多篇,这两个是研究的绝对热点问题。Knowledge Distillation有4篇,Compact CNN Design有3篇。下面分别从这几个方面进行简单介绍。

深度网络加速和压缩的第一种方法是Low-Rank低秩分解。由于卷积神经网络中的主要计算量在于卷积计算,而卷积计算本质上是矩阵分析的问题,通过在大学对矩阵分析、高等数学的学习我们知道通过SVD奇异值分解等矩阵分析方法可以有效减少矩阵运算的计算量。
对于二维矩阵运算来说SVD是非常好的简化方法,所以在早期的时候,微软研究院就做过相关的工作来对网络实现加速。后面对于高维矩阵的运算往往会涉及到Tensor分解方法来做加速和压缩,主要是CP分解、Tucker分解、Tensor Train分解和Block Term分解这些在2015年和2016年所做的工作。

应该说矩阵分解方法经过过去的发展已经非常成熟了,所以在2017、2018年的工作就只有Tensor Ring和Block Term分解在RNN的应用两篇相关文章了。
那么为什么Low-Rank不再流行了呢?除了刚才提及的分解方法显而易见、比较容易实现之外,另外一个比较重要的原因是现在越来越多网络中采用1×1的卷积,而这种小的卷积使用矩阵分解的方法很难实现网络加速和压缩。

深度网络加速和压缩的第二种方法是Pruning,简单来说就是把神经网络中的连接剪掉,剪掉以后整个网络复杂度特别是网络模型大小要减小很多。最早在ICLR2016上斯坦福大学提出了一种称为Deep Compression的随机剪枝方法。
由于随机剪枝方法对硬件非常不友好,往往在硬件实现的过程中不一定能够很好地对网络起到加速和压缩的效果。后来大家就想到使用成块出现的结构化Pruning,Filter Pruning,梯度Pruning等方法。
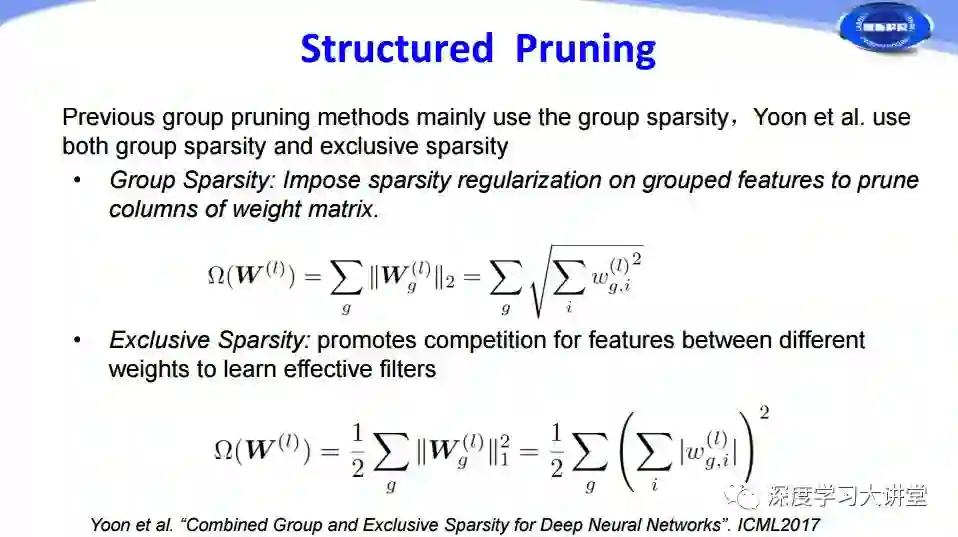
对于结构化Pruning,在ICML2017中有一篇对于权重进行分析剪枝的文章。具体方法是:首先使用Group Sparsity组稀疏的方法对分组特征添加稀疏正则来修剪掉权重矩阵的一些列,然后通过Exclusive Sparsity增强不同权重之间特征的竞争力来学习更有效的filters,两者共同作用取得了很好的Pruning结果。
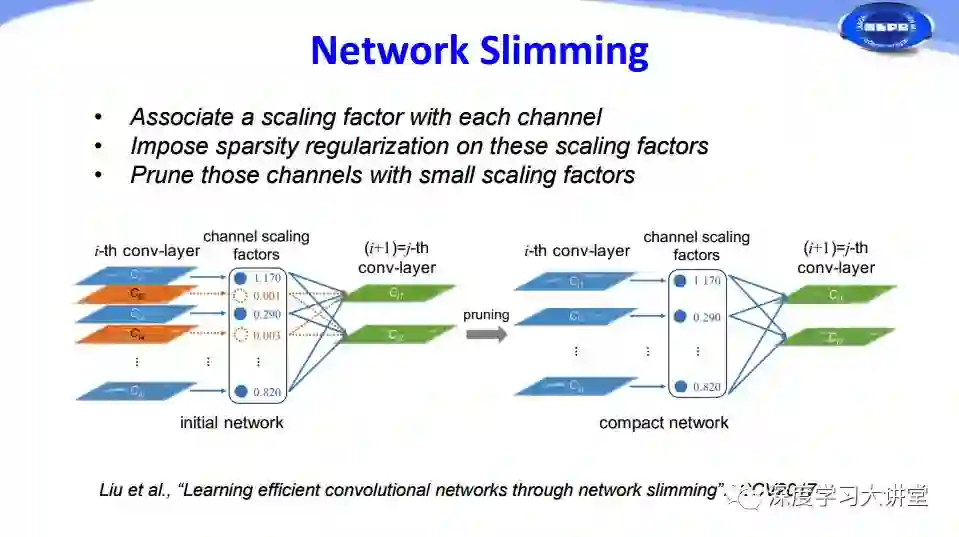
从另一方面考虑,我们能否对feature map和activation也做一些pruning的工作呢?在ICCV2017的工作中有人通过给每个通道channel添加一个尺度因子scaling factor,然后对这些尺度因子scaling factor添加sparsity regularization,最后根据尺度因子大小对相应的通道channels进行修剪,将一些尺度因子比较小的通道剪掉,实现对整个网络的瘦身效果。
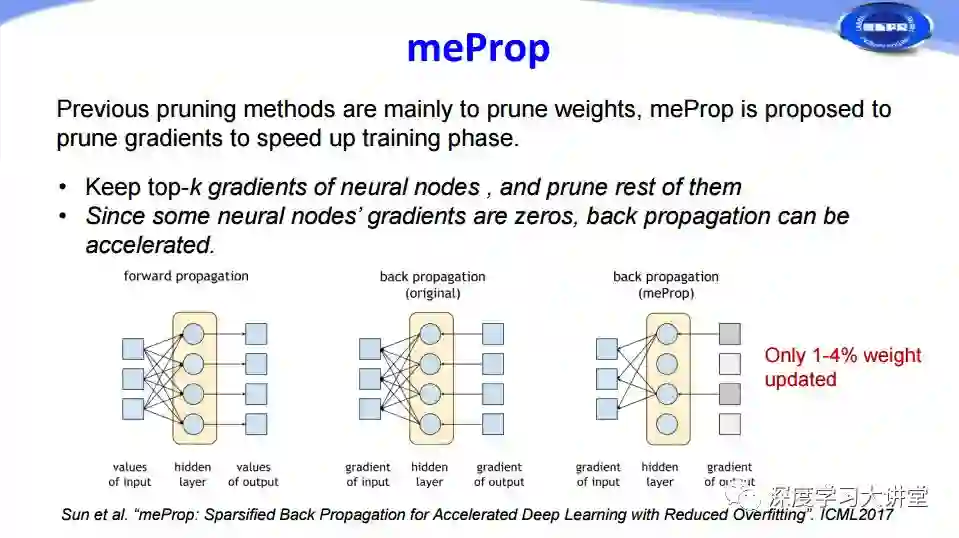
刚才所讲的都是在网络前向传播过程中所做的Pruning,那么我们能否在网络训练的过程中也加入Pruning来加快网络训练的过程呢?ICML2017有一篇文章对网络训练过程中的梯度信息做了分析,通过去掉幅值比较小的梯度来简化网络的反向传播过程,从而加快网络的训练过程。从结果来看,这种方法可以通过仅仅更新1%-4%的权重来实现和原有网络相当的效果。

除了Pruning,还有一种研究较多的方法是Quantization量化。量化可以分为Low-Bit Quantization(低比特量化)、Quantization for General Training Acceleration(总体训练加速量化)和Gradient Quantization for Distributed Training(分布式训练梯度量化)。

由于在量化、特别是低比特量化实现过程中,由于量化函数的不连续性,在计算梯度的时候会产生一定的困难。对此,阿里巴巴冷聪等人把低比特量化转化成ADMM可优化的目标函数,从而由ADMM来优化。

我们实验室从另一个角度思考这个问题,使用哈希把二值权重量化,再通过哈希求解。
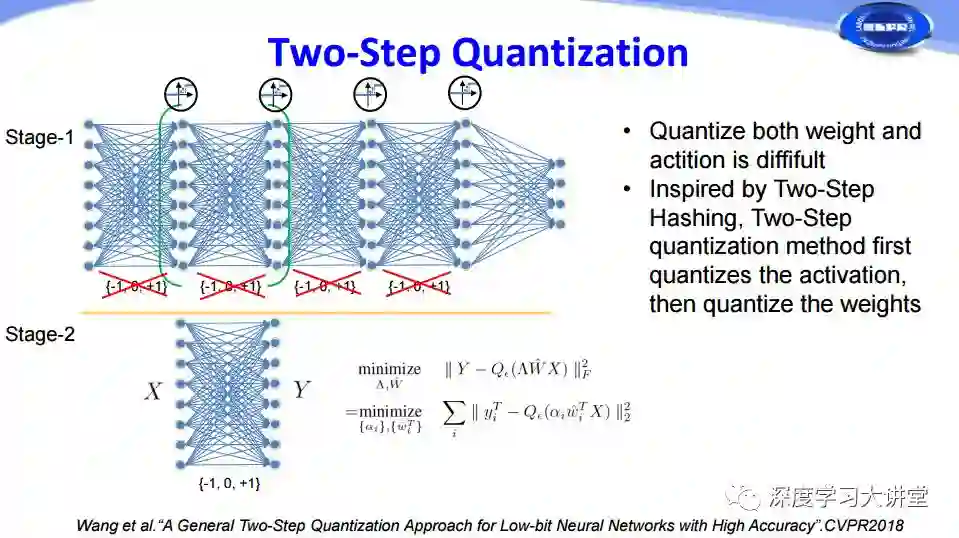
前面两篇文章都是对权重进行量化,那么feature map能否也可以进行量化呢?以前有人考虑过这个问题,将权重和feature map一起进行量化,但在实际过程中非常难以收敛。我们实验室在CVPR2018上提出一个方法,受到两步哈希法的启发,将量化分为两步,第一步先对feature map进行量化,第二步再对权重量化,从而能够将两个同时进行很好的量化。
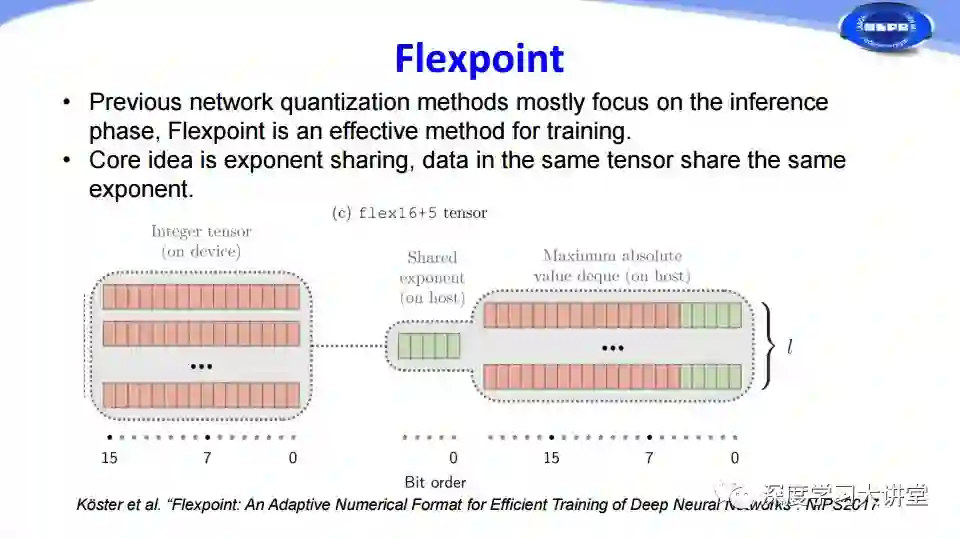
刚才的量化都是在网络inference过程中,其实量化也可以在训练过程中使用,这是英特尔在NIPS2017提出的Flexpoint方法。我们知道在32位浮点和16位浮点存储的时候,第一位是符号位,中间是指数位,后面是尾数。他们对此提出了把前面的指数项共享的方法,这样可以把浮点运算转化为尾数的整数定点运算,从而加速网络训练。

在很多深度学习训练过程中,为了让训练更快往往会用到分布式计算。在分布式计算过程中有一个很大问题,每一个分布式服务器都和中心服务器节点有大量的梯度信息传输过程,从而造成带宽限制。这篇文章采取把要传输的梯度信息量化为三值的方法来有效加速分布式计算。

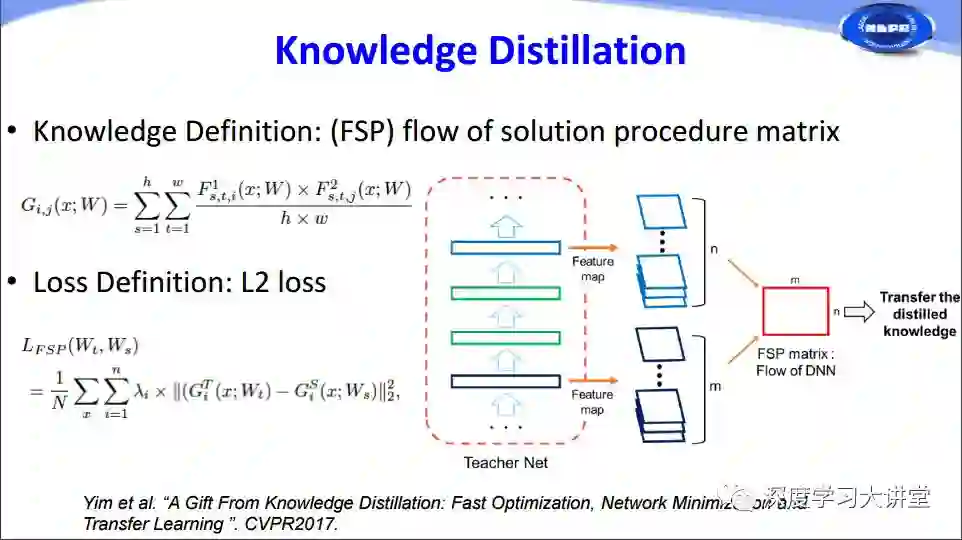
第四种方法是Knowledge Distillation。这方面早期有两个工作,Knowledge Distillation最早由Hinton在2015年提出,随后Romero提出了FitNets。在Knowledge Distillation中有两个关键的问题,一是如何定义知识,二是使用什么损失函数来度量student网络和teacher 网络之间的相似度。

这里主要介绍2017年的两个相关工作。一是FSP方法,它实际上将原始网络中feature map之间的相关度作为知识transfer到student network中,同时使用了L2损失函数。
另一个ICLR2017的工作在feature map中定义了attention,使用了三种不同的定义方法,将attention作为知识transfer到student network中。

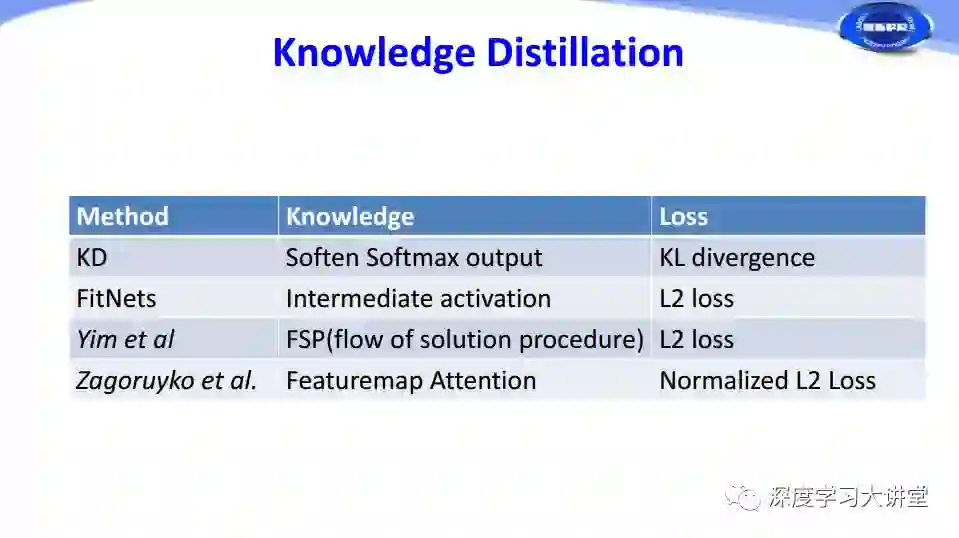
下面是几种主流方法在知识定义和损失函数选择方面的对比。
最后简单讲一下紧致网络设计。我们刚才讲到的几种网络加速和压缩方法都是在原有非常复杂的网络基础上,对它进行量化、剪枝,让网络规模变小、计算变快。我们可以考虑直接设计又小又快又好的网络,这就是紧致网络设计的方法。我们主要讲三个相关的工作。

先介绍谷歌在2017年和2018年连续推出的MobileNets V1和MobileNets V2,其中使用了depthwise的1x1卷积。MobileNets V1是一个在网络非常精简情况下比较高性能的网络,MobileNets V2开始于通道比较少的1×1的网络,然后映射到通道比较多的层,随后做一个depthwise,最后再通过1x1卷积将它映射回去,这样可以大幅减少1×1卷积计算量。
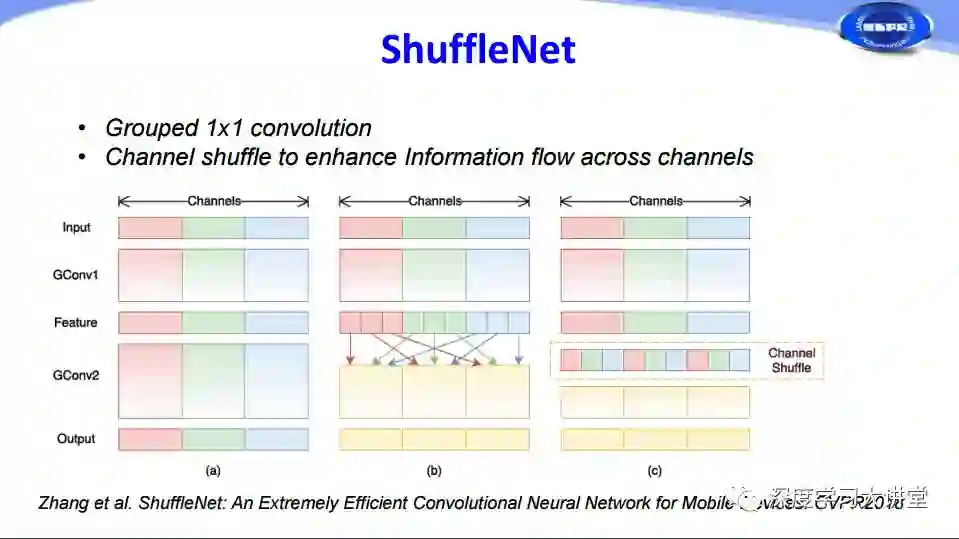
实际上MobileNets中1x1的卷积占有很大的比重,基于这样的原则,旷视科技在CVPR2018提出把1×1的卷积通过分组来减少计算的方法,由于分组以后存在不同通道之间信息交流非常少的问题,他们又在卷积层之间增加channel shuffle过程进行随机扰乱,增加了不同通道之间的信息交流。这是ShuffleNet所做的工作。
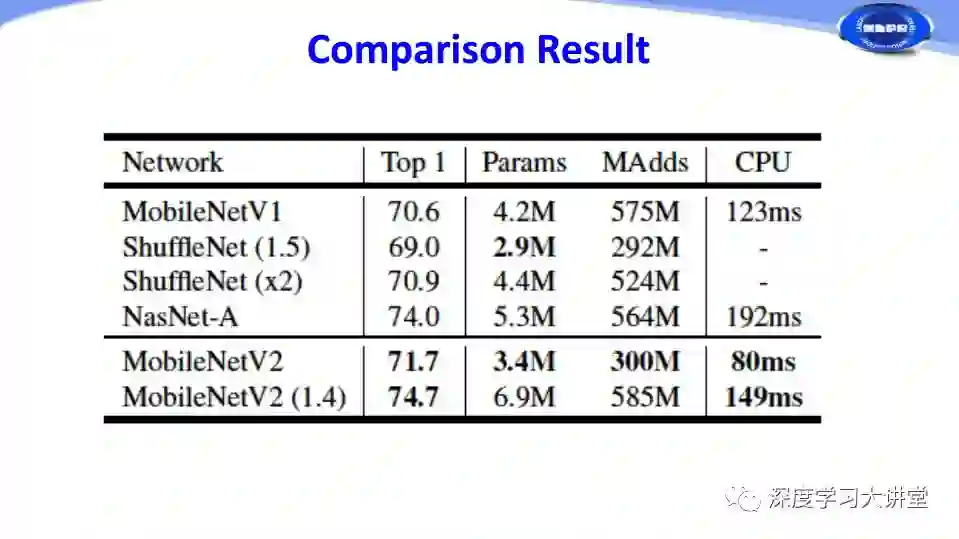
下面是紧致网络设计几种方法的比较。
最后简单讲一下深度神经网络加速和压缩的发展趋势。
第一,我们发现实际上现在绝大部分加速和压缩的方法,都需要有一个fine-tuning的过程,这个过程需要有一定量的含有标签的原始训练样本,这在实际应用过程中可能会有一定的限制。会有一些Non-fine-tuning或者Unsupervised Compression方法的出现。实际上现在已经有人在研究这方面的东西。
第二,在加速和压缩过程中会涉及到很多参数,甚至还包含很多经验性东西,将来能不能做到尽可能少需要、不需要经验或者参数越少越好的self-adaptive方法。
第三,现在很多加速压缩方法往往都是针对分类问题,未来在目标检测、语义分割方面也会出现类似的工作。
第四,现在很多方法与硬件的结合越来越紧密,对于加速和压缩方面来说也是如此,未来肯定是之间的结合越来越多。最后是二值网络越来越成熟,未来研究的人会越来越多。由于时间的关系只能简单介绍,可以参考我们最近刚发表在FITEE 2018上的综述论文了解更多详细的信息。

文中提到参考文献的下载链接为:
https://pan.baidu.com/s/1mpXsDzMZXRNO9tVB8pVkHw
密码:k1T5
作者信息:
作者简介:

程健,博士,中国科学院自动化研究所模式识别国家重点实验室研究员、南京人工智能芯片创新研究院常务副院长、人工智能与先进计算联合实验室主任。分别于1998年和2001年在武汉大学获学士和硕士学位,2004年在中国科学院自动化研究所获博士学位。2004年至2006年在诺基亚研究中心做博士后研究。2006年9月至今在中科院自动化研究所工作。目前主要从事深度学习、人工智能芯片设计、图像与视频内容分析等方面研究,在相关领域发表学术论文100余篇,英文编著二本。曾先后获得中科院卢嘉锡青年人才奖、中科院青年促进会优秀会员奖、中国电子学会自然科学一等奖、教育部自然科学二等奖等。目前担任国际期刊《Pattern Recognition》的编委,曾担任2010年ICIMCS国际会议主席、HHME 2010组织主席、CCPR 2012出版主席等。
(本文授权转载自深度学习大讲堂,ID:deeplearningclass)
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号: aiera2015_3 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。





