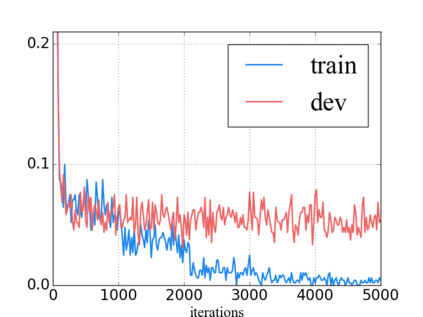
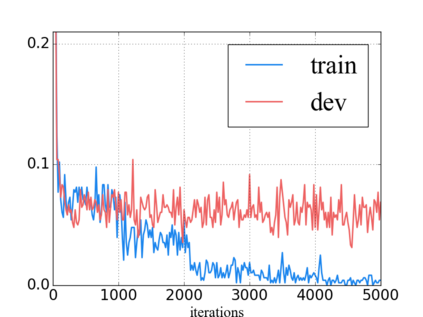
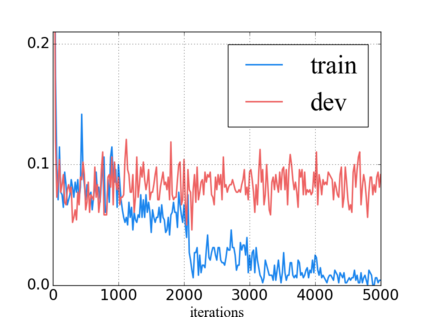
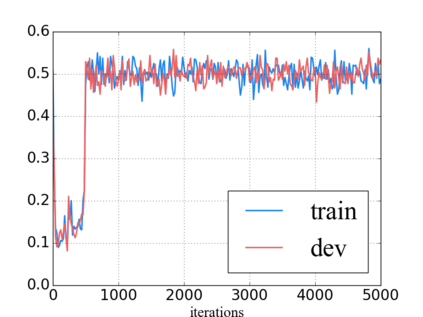
Language model pre-training has proven to be useful in learning universal language representations. As a state-of-the-art language model pre-training model, BERT (Bidirectional Encoder Representations from Transformers) has achieved amazing results in many language understanding tasks. In this paper, we conduct exhaustive experiments to investigate different fine-tuning methods of BERT on text classification task and provide a general solution for BERT fine-tuning. Finally, the proposed solution obtains new state-of-the-art results on eight widely-studied text classification datasets.
翻译:事实证明,语言模式培训前模式有助于学习通用语言代表制,作为一个最先进的语言模式培训前模式,BERT(来自变换者的双向编码器代表制)在许多语言理解任务中取得了惊人的成果,在本文件中,我们进行了详尽的实验,以调查BERT在文本分类任务上的不同微调方法,并为BERT的微调提供一个总体解决办法。最后,拟议的解决方案在8个经过广泛研究的文本分类数据集中获得了新的最新结果。