
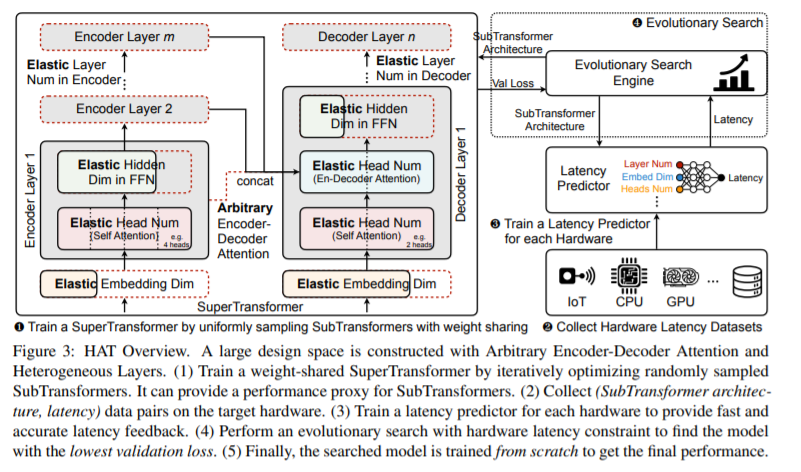
Transformers 在自然语言处理(NLP)任务中是普遍存在的,但由于计算量大,很难部署到硬件上。为了在资源受限的硬件平台上实现低延迟推理,我们提出使用神经架构搜索设计硬件感知转换器(HAT)。我们首先构造了一个具有任意编码-解码器关注和异构层的大设计空间。然后我们训练一个超级Transformers,它能覆盖设计空间中的所有候选Transformers ,并有效地产生许多具有重量共享的次级Transformers。最后,我们执行带有硬件延迟约束的进化搜索,以找到专用于在目标硬件上快速运行的专用子转换器。对四种机器翻译任务的大量实验表明,HAT可以发现不同硬件(CPU、GPU、IoT设备)的有效模型。在Raspberry Pi-4上运行WMT’14翻译任务时,HAT可以实现3×加速,3.7×比基准Transformer小;2.7×加速,比进化后的Transformer小3.6倍,搜索成本低12,041倍,没有性能损失。
成为VIP会员查看完整内容
相关内容
专知会员服务
21+阅读 · 2020年4月30日
Arxiv
15+阅读 · 2018年10月11日
相关主题

相关VIP内容
专知会员服务
21+阅读 · 2020年4月30日
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日