旷视研究院张祥雨:高效轻量级深度模型的研究与实践
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

近日,旷视研究院基础模型组负责人张祥雨博士受邀在 VALSE 2019 上做了题为《高效轻量级深度模型的研究与实践》的 Workshop 报告,这次通过文字梳理的形式将其呈现出来,作为第 5 期「R Talk 」。
背景
众所周知,CNN 模型已是现代深度视觉系统的一个核心部分,作为基础模型,它起到了特征抽取器的作用,被应用于很多业务场景如人脸识别、物体检测与语义分割等等;之所以将基础模型称为“核心部分”,有以下 2 个原因:
基础模型设计的好坏在很大程度上会影响整个系统的精度;
由于 CNN 模型的计算复杂度往往相当巨大,因此基础模型还决定着整个模型的计算复杂度和开销。
以 ImageNet 数据集的分类任务成绩为例,自 2012 年 AlexNet 出现以来,短短 3 年,网络的分类错误率大幅下降,到 2015 年 ResNet 出现时,已经低至 3.57%。虽然如此,理论上的“攻城掠地”却并未给落地应用铺平多少“道路”,巨大的计算负荷致使一般设备完全无法在模型精度和速度上进行平衡。
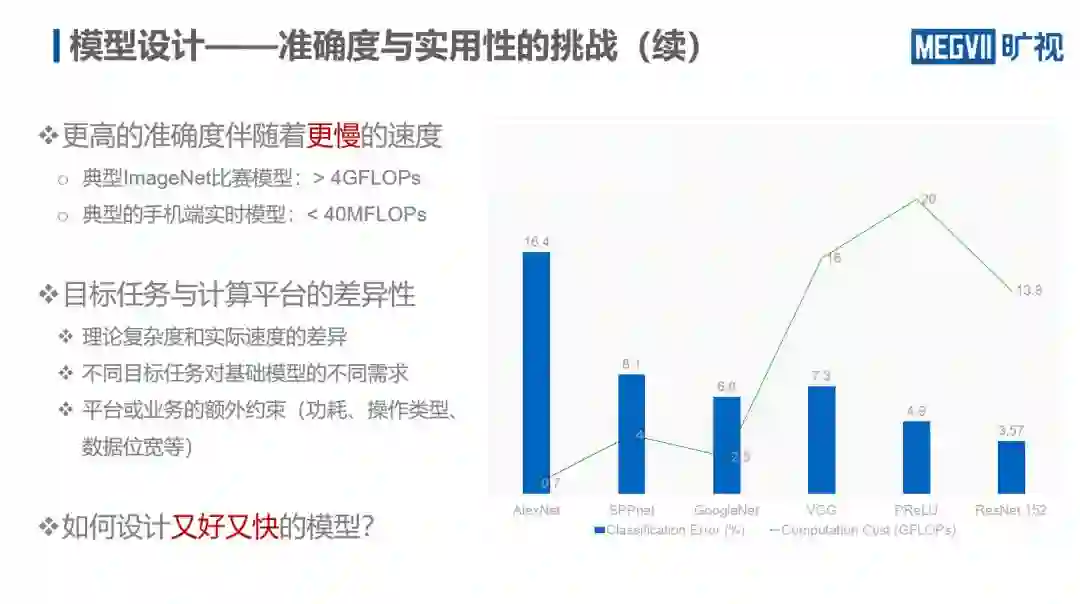
由上图可知,虽然 ResNet 在当时取得了最高精度,但其计算复杂度也达到了惊人的 13.8 GFLOPs。因此,为了模型能够落地应用,设计一个精度既高、速度又快的模型就成了当下的一大研究重点。
一般而言,高效模型的设计有 6 大基本思路:1)轻量级架构、2)模型裁剪、3)模型搜索、4)低精度量化、5)知识蒸馏、6)高效实现。本文将根据旷视研究院相关工作,着力讨论前面 3 三种思路。
轻量级架构
轻量级架构——ShuffleNet V1
轻量级架构是一种直接思路,其要义是设计一个轻量级模型,能够完成相应的目标任务,相较于上述参加 ImageNet 比赛的模型,它最显著的特征是计算量很小。然而,由于计算量的下降,模型的精度势必会降低,所以对于轻量级模型设计而言,如何在有限的计算复杂度下让模型获得尽可能高的表示能力就成为了该思路要解决的核心问题。
一般而言,通道的宽度直接决定了模型的表示能力。因此一个可行的着手点便是如何在相同的 FLOPs 下尽可能多地增加通道数量。最直接的想法是将通道进行稀疏连接。基于这一思路,第一代 ShuffleNet 应运而生。
分组卷积是一种非常有效的稀疏连接方式 ,能大幅减少网络的计算量,被用于如 DeepRoots、Xception、ResNeXt 这些较早期的网络。人们自然猜想,如果将网络的所有卷积改为分组卷积,是否就可以得到一个非常轻量化的模型呢?并不是。
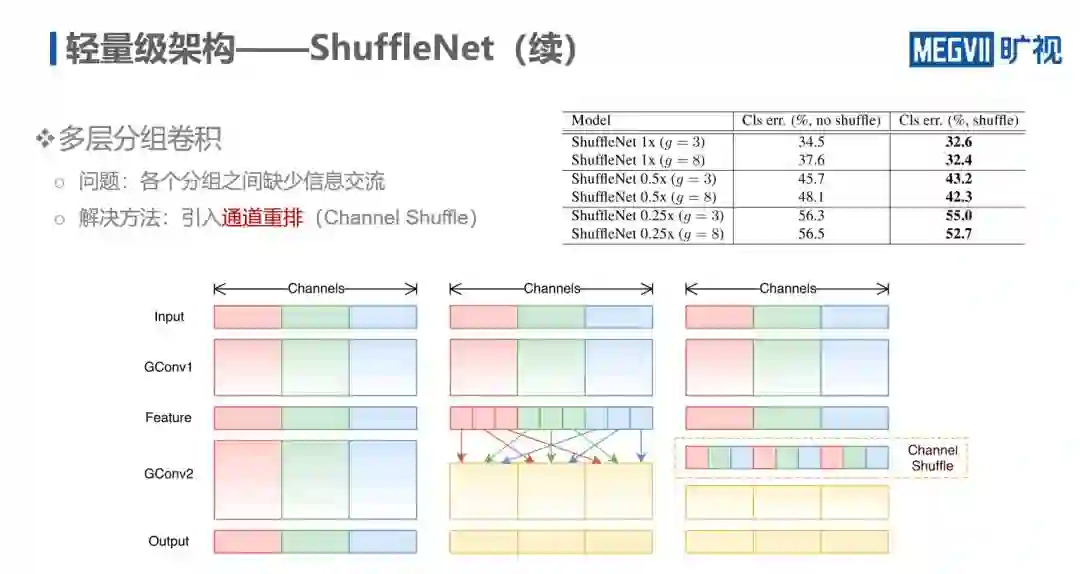
假定卷积的组数完全一致,如果把网络的所有层都用分组卷积来实现,则会发现网络被拆分成多份,且每份之间没有信息交流,网络性能不如人意。为此,旷视研究院提出通道重排(Channel Shuffle)。
如下图所示,在分组卷积的情况下,每一个辅助的通道都是来自于输入通道的一部分,即每一个 GConv 都是输出通道的一部分。当对这些分组卷积进行打乱并重新组合以后,通道之间的信息便得到了交换。由下图数据可知,引入通道重排后模型的错误率显著下降。
在构造单元设计方面,ShuffleNet 采用了类似 ResNet 的结构,不同的是把 ResNet 的 3 × 3 卷积层换为 DWConv,其它则都换为 GConv。
此外,该结构还采用了快速降采样的设计,即只用一层卷积将网络的 stride 迅速降为原来的 1/8。之所以采用这一设计,是因为,虽然图像的分辨率对于提升网络的精度十分关键,但在需要网络快速运算的场景下,高分辨率会引入很大的内存读写开销。因此,快速降低图像分辨率就成为了缩短网络运行时间的重要一环。
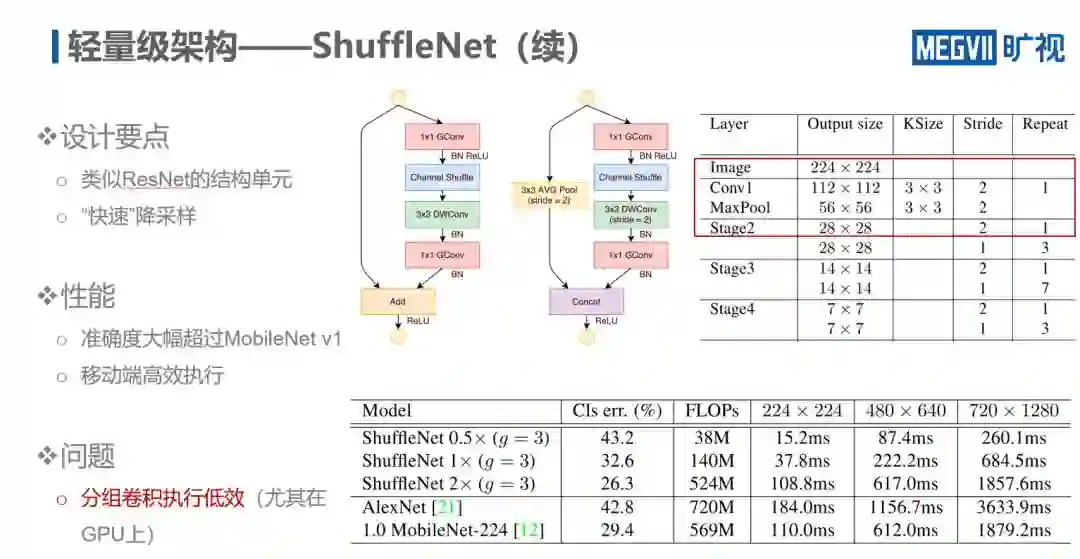
从性能方面看,虽然模型在精度上得到大幅提升,但第一代 ShuffleNet 遗留了一个问题,即大量使用分组卷积。下文可以看到,分组卷积的效率很低,尤其在 GPU 上。因此第一代 ShuffleNet 主要被用于基于 ARM 的低端设备,而不太适用于高性能并行化运算的设备。
轻量级架构——ShuffleNet V2
为攻克 ShuffleNet V1 的缺点,旷视研究院展开进一步研究,并得出结论:理论的计算复杂度往往和实际的执行速度不完全对等。
一般而言,当人们谈到理论复杂时主要指卷积层的复杂度。然而需要注意的是,卷积层之外的其它层其实也会消耗大量计算。因此,影响模型实际运行的因素除了理论计算量之外,同时还有如计算访存比、模块并行度、设备特性等因素。
在 ShuffleNet V2 中,旷视研究院对模型在计算访存比与模型并行度两个方面做了优化,提了 4个高性能网络设计的指导原则:
卷积的输入、输出通道数应尽可能接近
谨慎使用分组卷积
减少网络碎片
逐元素运算的开销不可忽视
需要注意的是,ShuffleNet V2 包含了部分逐点运算结构,如下图的 Channel Split、Contact、Channel Shuffle。对于这些结构而言,一些高度优化的模块可以将其融合成一个操作,进而大幅提升速度。
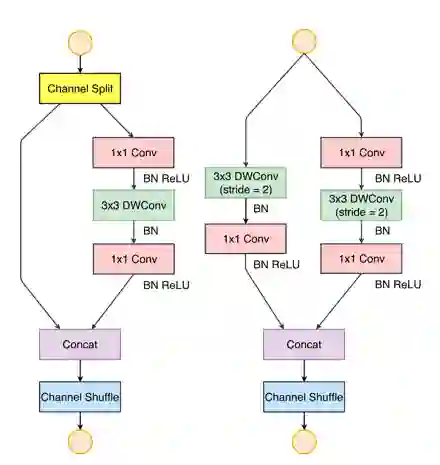
另外,ShuffleNet V2 也参考了 DensNet 的思想,即通过 Contact 实现特征的重用。这也是该模型除速度快以外,精度也高的原因。
ShuffleNet V2 在提出之时实现了在 GPU/ARM 上最优的精度-速度权衡,精度显著超过 MobileNet V2 等 SOTA 模型。
即便到目前,第二代 ShuffleNet 依然是一个非常有竞争力的模型,它不仅在小模型上表现优秀,在大模型上依然抢眼。作为旷视参加 2018 COCO+Mapillary 联合挑战赛的 Backbone,ShuffleNet V2 助力研究院“喜提” 挑战赛 6 项冠军中的 4 项。
在通用性和可迁移性上,ShuffleNet V2 显著提升了物体检测的速度与精度。不过,它在面临诸如语义分割这类任务时效果却一般,究其原因主要与快速降采样有关。这凸显了目前手工高性能模型的一大痛点,即:为了实现高效率,必然要放弃如图片分辨率这样的关键因素。这种妥协对某些特定任务而言,可能会产生明显影响。
模型搜索
模型搜索是当下的一大热门研究领域,旷视研究院在这方面的工作主要聚焦在如何将其应用落地,切实提高生产效,最后凝聚成行业领先的自动化机器学习技术 Brain++ AutoML。
“不可能三角”:通过对目前学界已经提出的模型进行研究,旷视研究院发现还没有一个搜索框架能同时满足效率、性能与灵活性三个要素(称为“不可能三角”),具体痛点如下:
效率:当下很多工作并没有能力在大数据集、大模型上进行搜索;此外,能否针对不同的速度、资源消耗等限制因素,快速生成满足要求的网络结构也是研究员要考虑的问题。
性能:当下模型依据的搜索原则是迁移原则,即在不同数据集之间进行切换搜索,其性能肯定不如直接在一个大型数据集上进行搜索。因此,提出一个有这样能力的模型就显得十分关键。另外,对于超大搜索空间而言,借助模型自动搜索,能否得到超越手工设计的高效结构?
灵活性:这方面很重要的一点被称为“hard constraint”,即搜索模型的速度能否被精准地控制。此外,当下的模型不支持多搜索任务、多种限制条件;也不支持对需要预训练的任务模型进行搜索。
下表是现有模型搜索的主要优缺点对比情况。
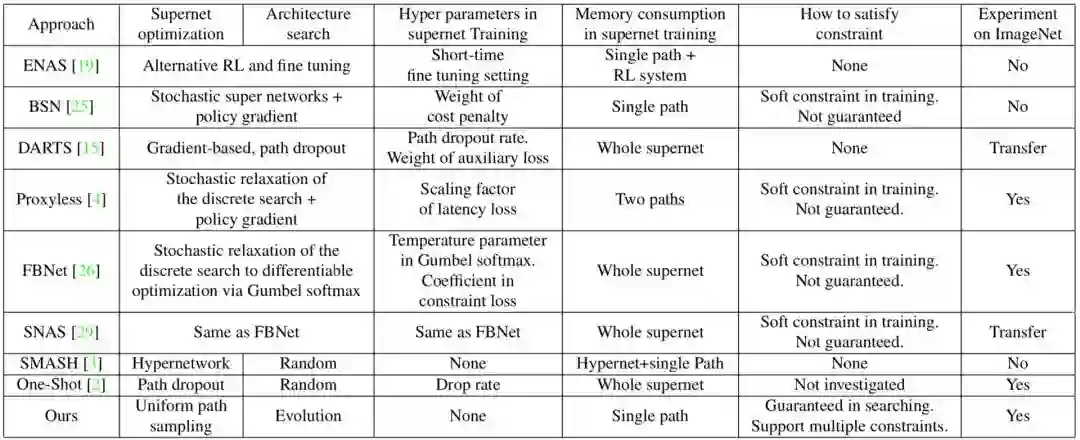
当下模型搜索各主要方法的优缺点
为挑战该“不可能三角”,旷视研究院提出 “Single Path One-Shot ”模型搜索方法,其核心思想分 3 步:1)解耦参数优化与架构优化,提高搜索效率;2)使用 Single Path Supernet 优化参数,保证高准确度;3)使用遗传算法进行架构优化,实现高灵活度。
Single Path One-Shot 算法流程
Single Path One-Shot 算法的 Pipeline 分 3 步走:
训练 Supernet
根据搜索空间构造选择块和 Supernet
每次迭代,随机选择 Supernet 中的一条路径进行训练
架构优化
使用遗传算法生成候选结构
评估 Supernet 对应的路径的性能,作为该候选结构的性能预测
对于不同的模型约束,只需重新运行架构优化步骤。无需重新训练 Supernet
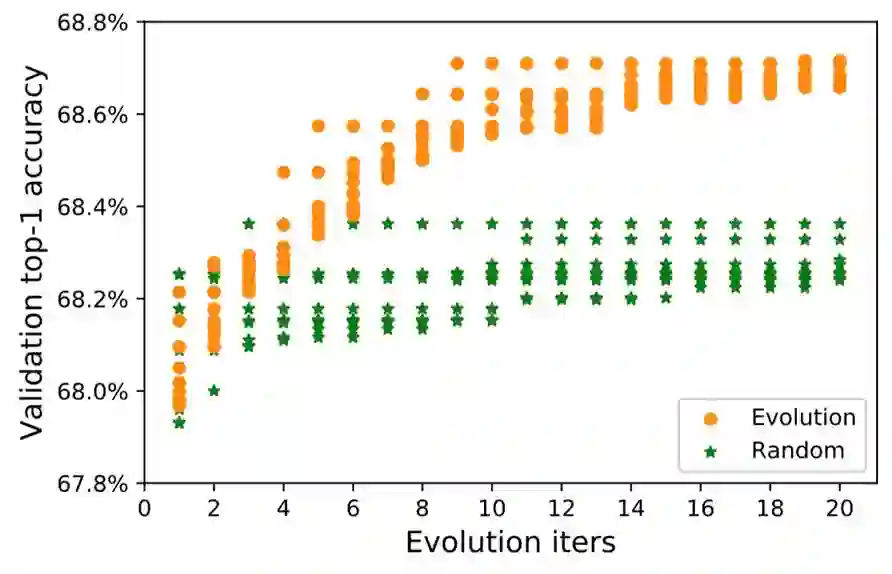
实验结果
实验结果表明,该方法在结构单元搜索、通道搜索与混合精度量化搜索方面皆取得优异成绩,如下表所示。
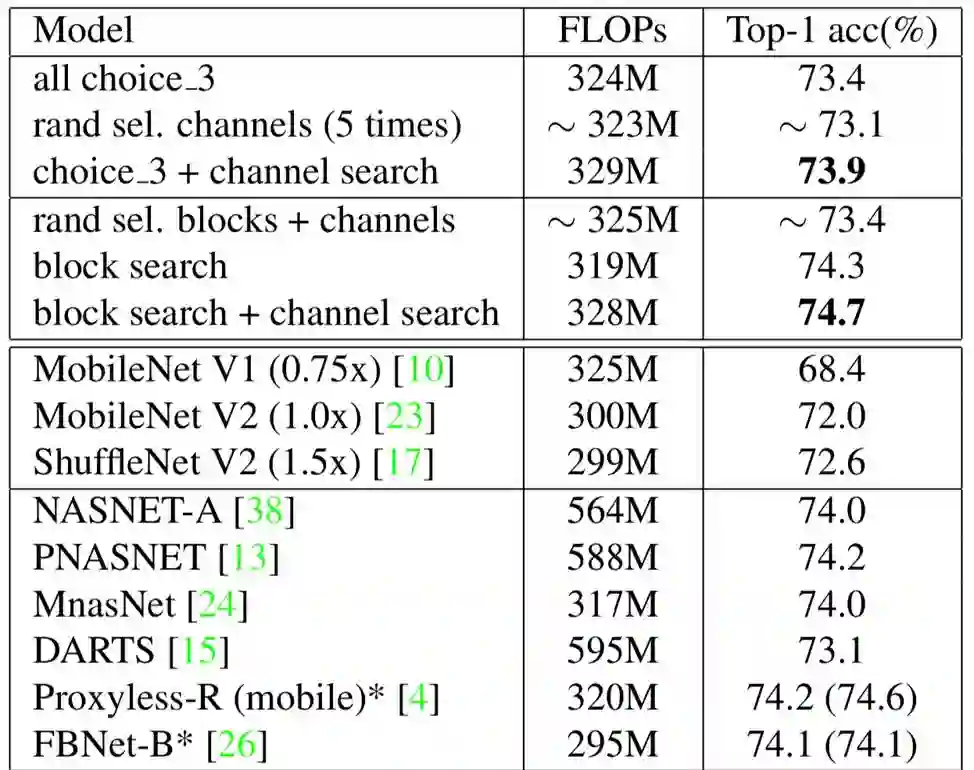
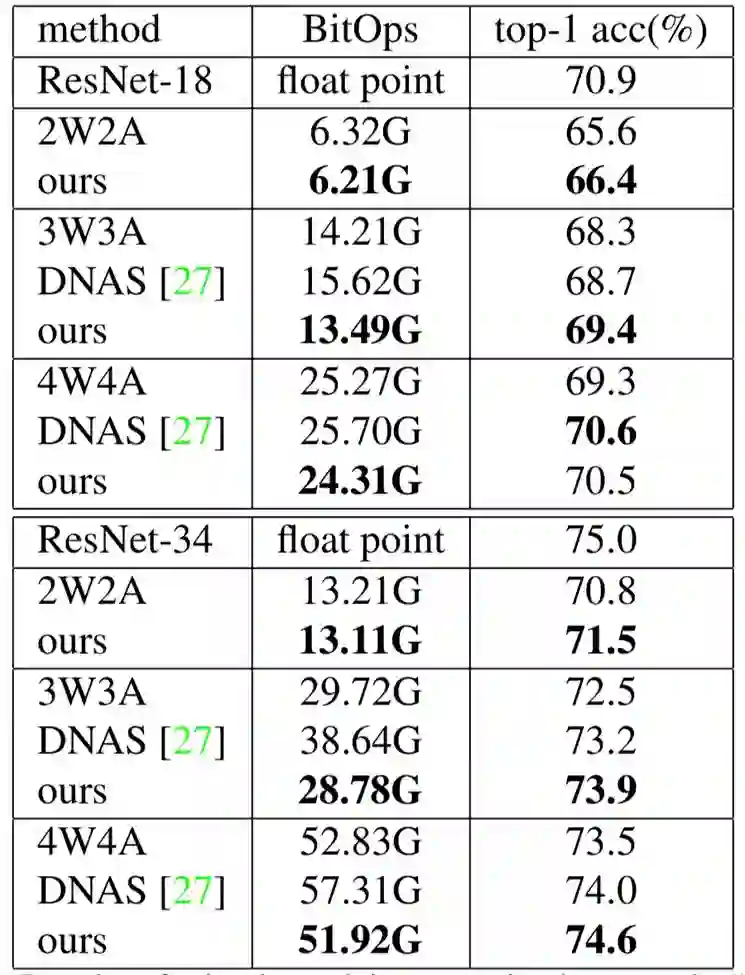
模型裁剪
随着深度神经网络的复杂度越来越高,如何使其在移动设备如手机、平板电脑、车载设备应用上高效运行就成为了一大关键。除上述介绍的轻量级架构模型与自动模型搜索方法以外,对大型模型的裁剪也是其中关键的一环。
MetaPruning方法
受到 Single Path One-Shot 方法的启发,旷视研究院提出一种全新的模型裁剪方法——MetaPruning,其基本思想是:
首先,基于 Single Path One-Shot 的模型结构,搜索裁剪后的模型结构;
进一步,依据结构信息,利用 Meta 网络解耦 Supernet 中不同支路的相关性,预测裁剪后结构的权重;
最后,利用遗传算法对这些权重进行高效搜索。
MetaPruning 方法的优点在于,它支持复杂的网络结构,例如,它可以直接搜索 ResNet 的 Shortcut 宽度;另外,它支持 “hard constraint”,无需调节相应的超参数,且单个 Supernet 可一次性生成多种复杂度的网络。
下表中,旷视研究员对比了在 latency constraint 相同的情况下,MetaPruning 与MobileNet V1/V2 的精度,数据显示 MetaPruning 大幅超越人工裁剪的精度。

总结
从研究可知,模型搜索在模型结构的排列组合、结构超参数的调优方面,相对人工设计有明显优势;但是搜索空间设计的好坏依然很大程度上依靠人工经验。人工设计在网络基本单元挖掘等方面目前仍不可替代,不过已经有相关的模型搜索工作正在进行探索性尝试。
因此,鉴于目前模型搜索的现状,要将其进行落地应用依然存在挑战。
参考文献
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. CVPR 2018.
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. ECCV 2018.
Single Path One-Shot Neural Architecture Search with Uniform Sampling.
Channel Pruning for Accelerating Very Deep Neural Networks. ICCV 2017.
MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning.
-End-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~



