【论文笔记】基于自编码器的通用性文本表征
【导读】学习文本语义表征是自然语言处理的一项基础研究工作,近年来,越来越多的研究者也开始关注文本的语义表征,本篇论文以无监督的方式来实现自动学习文本语义表征,希望作者的论文对你的研究有所启发。
原文链接:
https://arxiv.org/abs/1809.06590

本篇论文实现通用性文本表征,与以往的RNN模型和监督学习不同,作者基于自编码器,利用Multi-head self-attention机制获取输入序列。在编码中,对隐藏向量h分别进行平均和最大化pooling;解码过程中,运用mean-max attention。本篇论文提出的模型(mean-max AAE)对比其他模型不仅精度最高,而且极大地减少了训练时长。
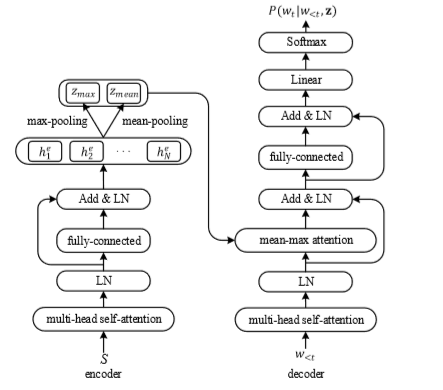
本篇文章将从模型和实验两方面进行详细介绍。
01
Multi-head self-attention
多头注意力机制,该结构出自Google于2017年发布的一篇论文《Attention is all you need》
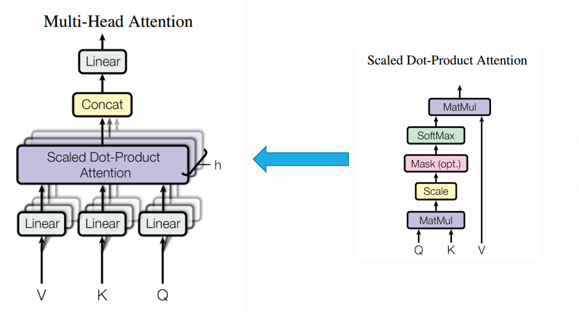
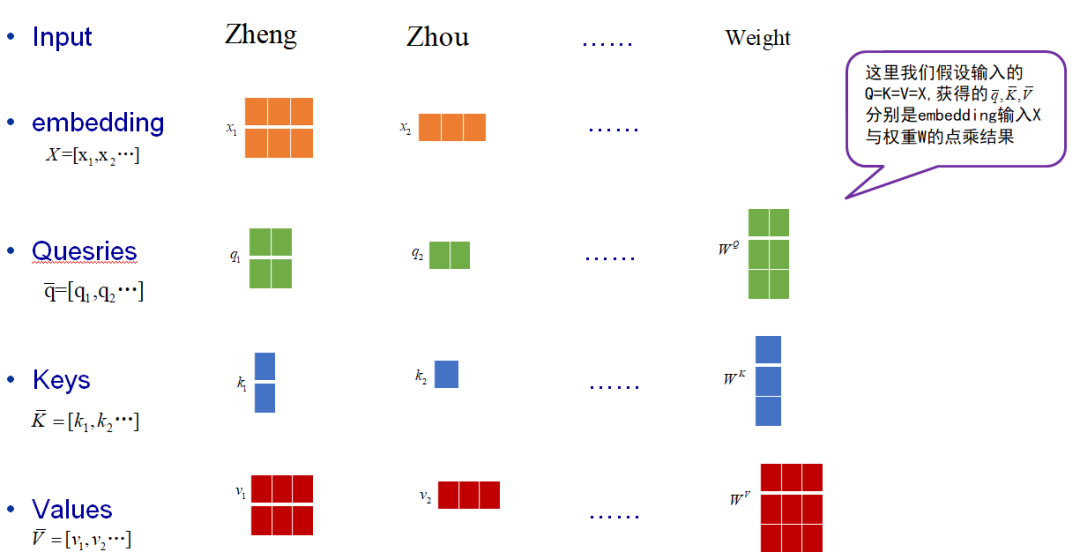
1)从模型可以看出,对于给定的输入V,K,Q要经过一个线性变化,这里的线性运算,我们用一个小例子来解释一下:
2)Multi-head self-attention模型的核心组件是Scaled Dot-Product Attention。

经过Scaled Dot-Product Attention运算(如下图所示)就可以获得n个head:
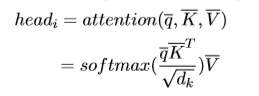
3)Multi-head self-attention是由多个Scaled Dot-Product Attention组成的,将计算的所有attention得到的head进行concat拼接与线性计算
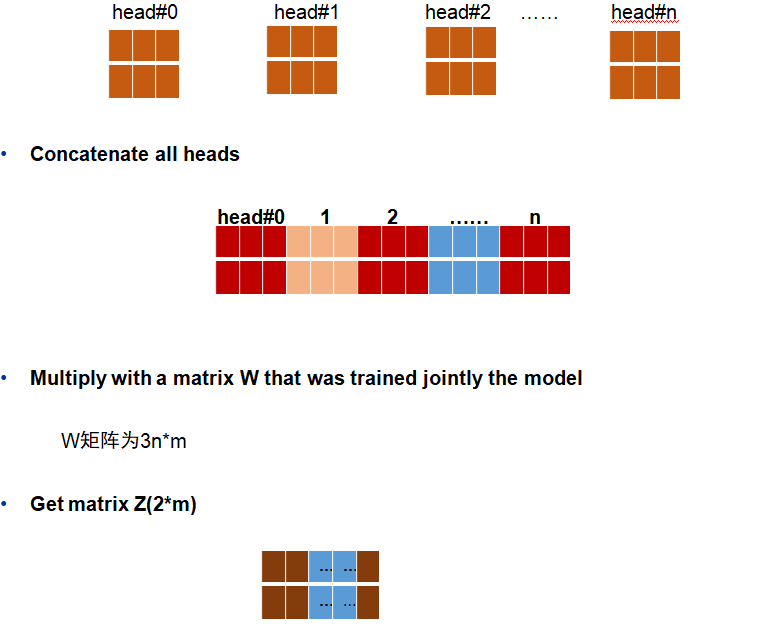
【注】:本篇论文定义的模型输入并非Q,K,V,而是由作者重新定义的x。作者将定义的词序列{w_1,w_2,…,w_N}变换为词向量矩阵e_t=W_e[w_t],除此之外,作者将位置编码与词嵌入矩阵线性相加作为模型的输入x:
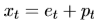
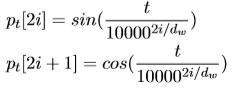
这里,t表示位置,i表示维度,位置编码的每个维度对应正弦曲线。
02
Attention Encoder
编码部分主要由三部分组成,一个是multi-head self-attention,另一个类似于残差网络,最后一步就是 mean-max 表征,如下图所示:
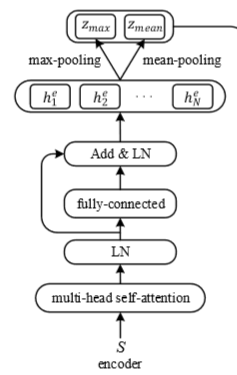
输入一组数据x=(x_1,…,x_N),经过multi-head self-attention得到a^e,然后经过网络中的第二部分前馈计算得到隐藏向量:
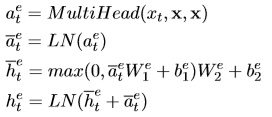
W_1∈R^{d_m*d_f},W_2∈R^{d_f*d_m}, b_1∈R^{d_f},b_2∈R^{d_m},d_m,d_f分别表示隐藏向量和全连接层的维度,实验中设置为2048和4096,LN表示正则化层。
对于编码中的最后一部分 mean-max 表征,就是通过池化计算得到向量中的最大值以及平均值:
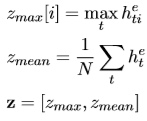
最大池化计算各维度的最大值,以试图捕获序列中的最显著的特征属性而过滤掉其他含有较少信息的局部值;平均池化对于显著的特征不关心,主要是为了捕获更普适性的信息。联合这两种池化向量,可以为文本重构提供更多语义信息。
03
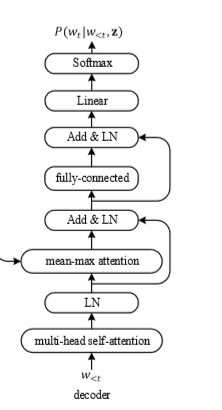
Attention Decoder
解码器同样依赖于multi-head self-attention,编码器与解码器通过mean-max attention层连接,并且将mean-max 层与全连接层通过残差结构连接,网络结构图如下所示:
给定一组输入y=(x_1,…,x_{t-1})和z(encoder的输出),通过一系列计算:
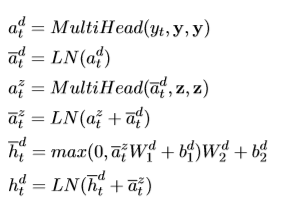
对于生成的隐藏向量,经过线性变换以及概率转换的计算,就得到了一组序列的概率:
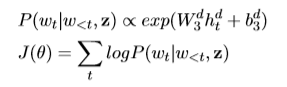
并通过优化J(θ)来学习重构输入序列。
2
01
实验评估
参数设置
隐藏向量和全连接层的维度分为设置为2048和4096,设置8个head进行encoder-decoder;
使用GloVe扩展编码器的词汇量
8G英伟达GPU
作者在10个不同的transfer task上进行实验,并从单模型无监督训练、混合模型无监督训练以及监督训练作实验对比(table 1),为了使对比效果明显,作者计算宏观“macro”和微观“micro”的平均精度(table 2)。
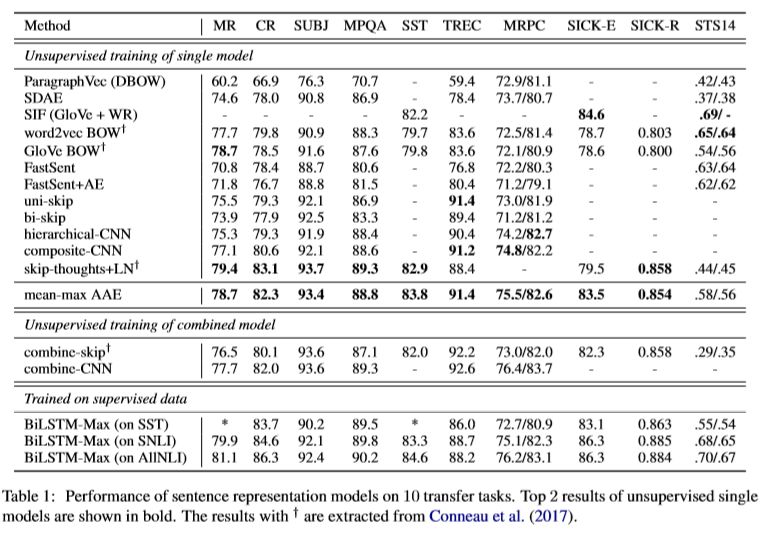
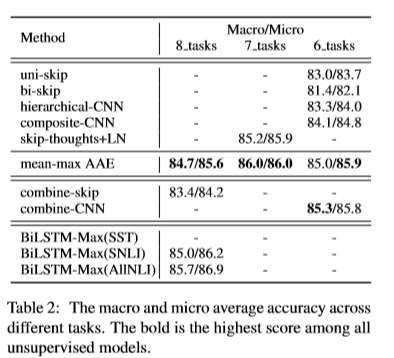
对比skip-thoughts+LN的方法:
表1中,论文提出的模型mean-max AAE在4个数据集中的结果更好(SST, TREC, SICK-E, STS14),在3个数据集上结果略低(SUBJ, MPQA, SICK-R);
表2中,模型mean-max AAE在7个数据集上的结果更好;
skip-thoughts+LN需要连贯的文本作为数据集且训练时间长达一个月,而mean-max AAE只需要单独的句子即可,训练时间最多5个小时
对比混合模型:
表2中,模型mean-max AAE相比模型 combine-skip 精确度高了1.3/1.4
模型mean-max AAE与模型 combine-CNN精度相差无几,然而作者的模型更简单,更快。
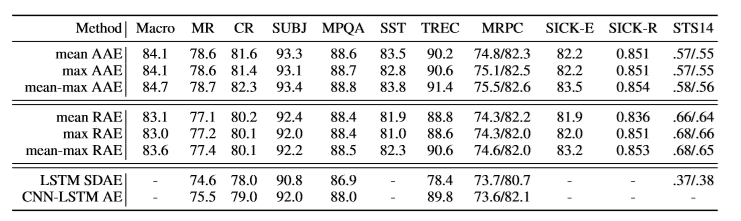
作者提出的模型主要包括3个模块:mean-max atten-tion layer,混合pooling,以及 encoder-decoder网络。
作者为了证明 mean-max representations的有效性,将mean与max分开进行实验对比;同时对比了LSTM SDAE、CNN-LSTM AE 模型,从数据可以看出mean-max AAE模型效果最好:

-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




