
摘要
Transformer模型架构最近引起了极大的兴趣,因为它们在语言、视觉和强化学习等领域的有效性。例如,在自然语言处理领域,Transformer已经成为现代深度学习堆栈中不可缺少的主要部分。最近,提出的令人眼花缭乱的X-former模型如Linformer, Performer, Longformer等这些都改进了原始Transformer架构的X-former模型,其中许多改进了计算和内存效率。为了帮助热心的研究人员在这一混乱中给予指导,本文描述了大量经过深思熟虑的最新高效X-former模型的选择,提供了一个跨多个领域的现有工作和模型的有组织和全面的概述。
关键词:深度学习,自然语言处理,Transformer模型,注意力模型
介绍
Transformer是现代深度学习领域中一股强大的力量。Transformer无处不在,在语言理解、图像处理等许多领域都产生了巨大的影响。因此,在过去的几年里,大量的研究致力于对该模型进行根本性的改进,这是很自然的。这种巨大的兴趣也刺激了对该模式更高效变体的研究。
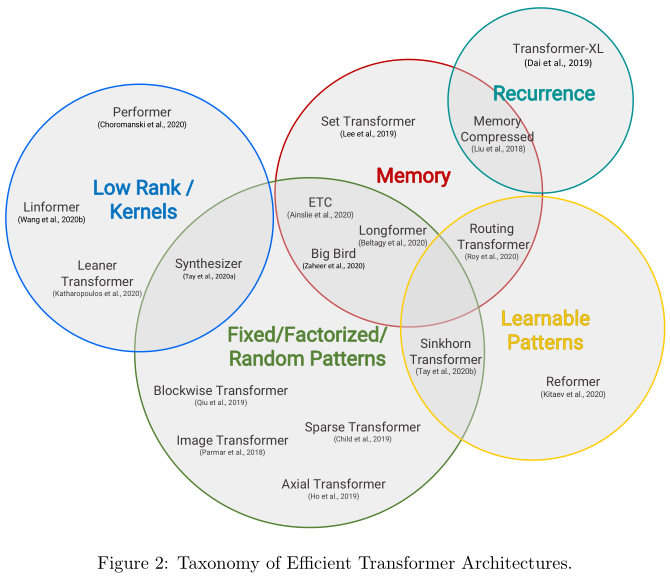
最近出现了大量的Transformer模型变体,研究人员和实践者可能会发现跟上创新的速度很有挑战性。在撰写本文时,仅在过去6个月里就提出了近12种新的以效率为中心的模式。因此,对现有文献进行综述,既有利于社区,又十分及时。
自注意力机制是确定Transformer模型的一个关键特性。该机制可以看作是一种类似图的归纳偏差,它通过基于关联的池化操作将序列中的所有标记连接起来。一个众所周知的自注意力问题是二次时间和记忆复杂性,这可能阻碍模型在许多设置的可伸缩性。最近,为了解决这个问题,出现了大量的模型变体。以下我们将这类型号命名为“高效Transformers”。
根据上下文,可以对模型的效率进行不同的解释。它可能指的是模型的内存占用情况,当模型运行的加速器的内存有限时,这一点非常重要。效率也可能指计算成本,例如,在训练和推理期间的失败次数。特别是对于设备上的应用,模型应该能够在有限的计算预算下运行。在这篇综述中,我们提到了Transformer在内存和计算方面的效率,当它们被用于建模大型输入时。
有效的自我注意力模型在建模长序列的应用中是至关重要的。例如,文档、图像和视频通常都由相对大量的像素或标记组成。因此,处理长序列的效率对于Transformer的广泛采用至关重要。
本篇综述旨在提供这类模型的最新进展的全面概述。我们主要关注的是通过解决自我注意力机制的二次复杂性问题来提高Transformer效率的建模进展和架构创新,我们还将在后面的章节简要讨论一般改进和其他效率改进。
本文提出了一种高效Transformer模型的分类方法,并通过技术创新和主要用例对其进行了表征。特别地,我们回顾了在语言和视觉领域都有应用的Transformer模型,试图对各个领域的文献进行分析。我们还提供了许多这些模型的详细介绍,并绘制了它们之间的联系。